



Сравнение содержимого ячеек – одна из базовых операций при работе с данными в Excel, которая помогает находить совпадения, выявлять расхождения и контролировать качество информации. В повседневной работе часто возникает необходимость сопоставить списки клиентов, проверить соответствие товарных позиций, найти дубликаты в базах данных или выявить изменения между версиями документов.
Excel предлагает множество способов сравнения ячеек: от простых операторов равенства до сложных функций, учитывающих частичные совпадения и регистр символов. Правильный выбор метода сравнения зависит от типа данных, требуемой точности анализа и специфики поставленной задачи.
Основные операторы и функции для сравнения
Сравнение ячеек в Excel основывается на использовании логических операторов и текстовых функций, каждая из которых имеет свои особенности применения. Оператор равенства проверяет точное совпадение значений, включая регистр символов и все пробелы.
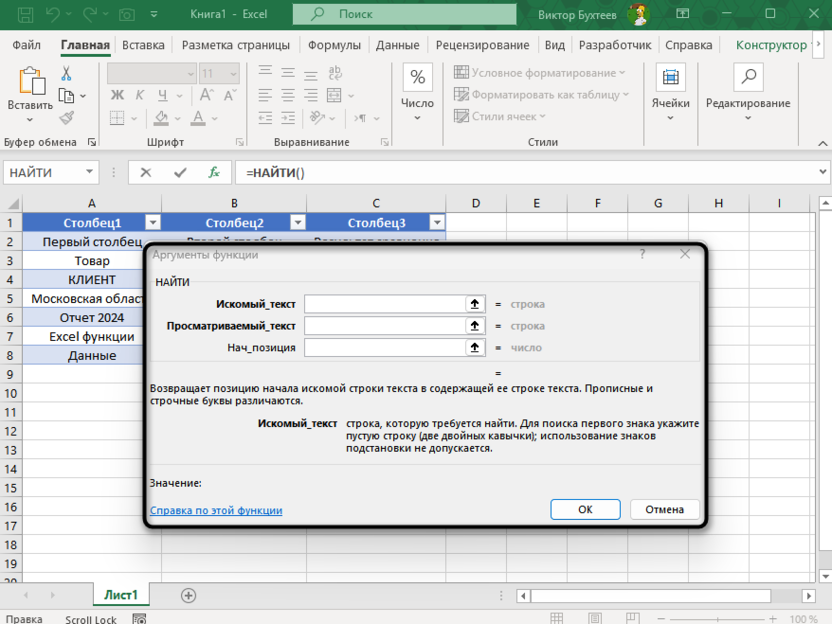
Функции ПОИСК и НАЙТИ позволяют находить частичные совпадения и вхождения одного текста в другой. Для более сложных сценариев используются комбинации функций ЕСЛИ, ПРОПИСН, ДЛСТР и других инструментов, обеспечивающих гибкую настройку критериев сравнения.
Таблица данных для примеров
Для демонстрации различных методов сравнения ячеек создадим таблицу с текстовыми данными, отражающими типичные ситуации сопоставления информации. Примеры включают точные совпадения, различия в регистре, частичные совпадения и полностью разные значения, что позволит показать работу каждого метода в реальных условиях.
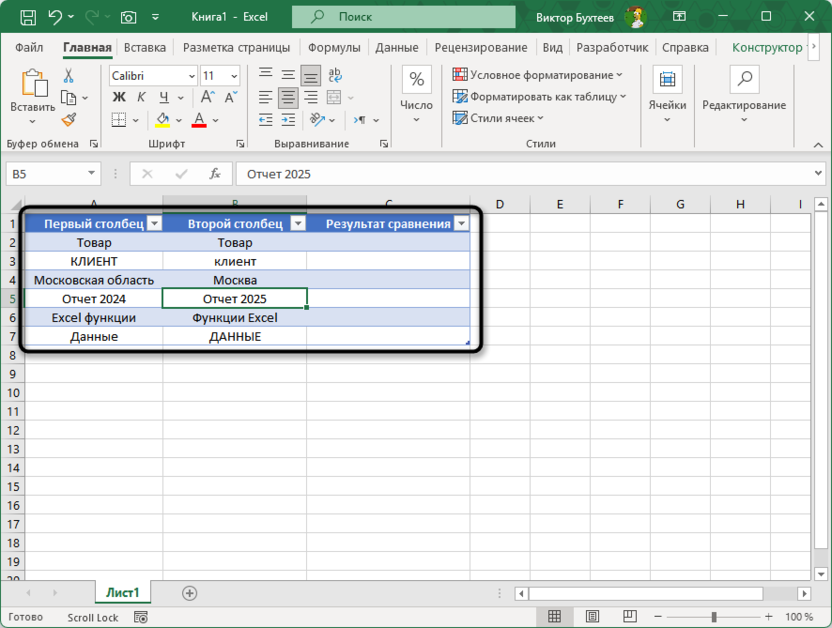
Таблица содержит различные варианты текстовых данных для сравнения: идентичные значения, различия в регистре символов, частичные совпадения и полностью разные записи. Эти примеры отражают реальные ситуации работы с корпоративными данными, где требуется выявить степень соответствия между информацией из разных источников. В следующих разделах рассмотрим четыре основных метода сравнения, каждый из которых решает определенные аналитические задачи.
Пример 1: Базовое сравнение с оператором равенства
Самый простой и распространенный способ сравнения ячеек использует оператор равенства, который проверяет соответствие содержимого двух ячеек без учета регистра символов. Этот метод учитывает пробелы и все специальные знаки, но игнорирует различия между заглавными и строчными буквами, что делает его удобным для большинства повседневных задач.
Оператор равенства идеально подходит для проверки соответствия данных, сравнения текстовых записей и контроля пользовательского ввода, где различия в регистре не критичны. При работе с названиями компаний, именами клиентов, адресами и подобной информацией этот метод обеспечивает оптимальный баланс между строгостью и практичностью. Формула возвращает логическое значение ИСТИНА при совпадении и ЛОЖЬ при различии содержимого.
=A2=B2
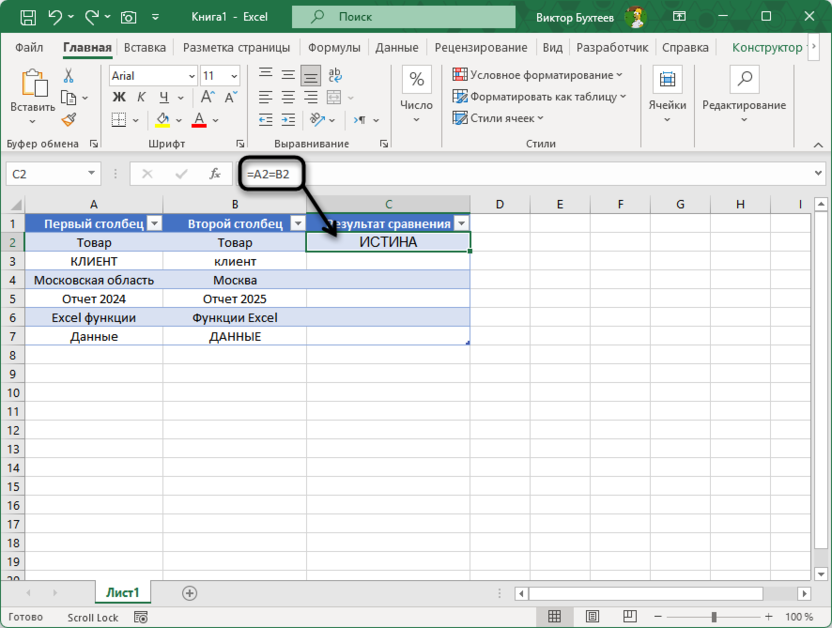
Для строки с текстом «Товар» в обеих ячейках формула вернет ИСТИНА, подтверждая полное соответствие содержимого. При применении к строке «КЛИЕНТ» и «клиент» результат также будет ИСТИНА, поскольку Excel по умолчанию выполняет регистронезависимое сравнение текста. Этот метод эффективен для базовой проверки соответствия данных, где различия в регистре не критичны.
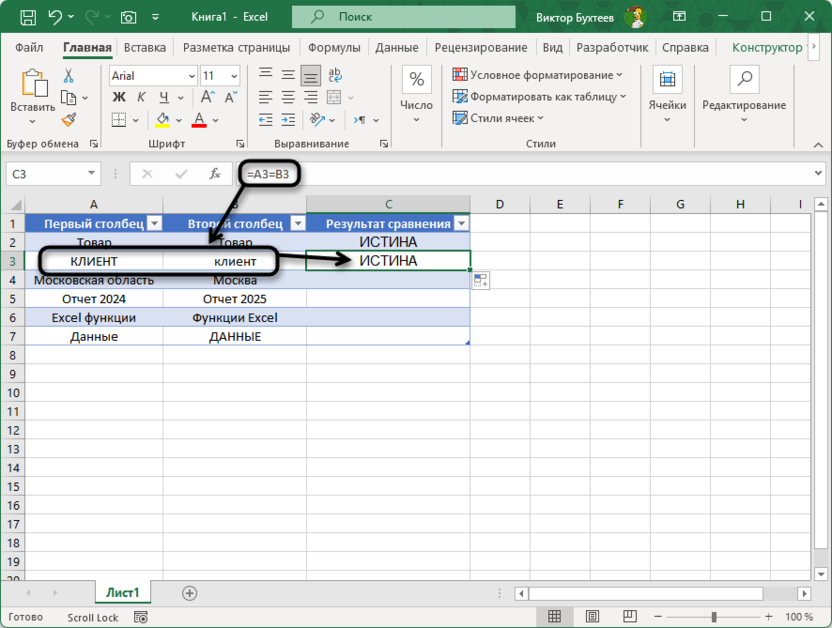
Простота использования и высокая скорость работы делают оператор равенства основным инструментом для массовой проверки соответствия данных. Результат легко интерпретируется и может использоваться в других формулах для создания условной логики. Регистронезависимое поведение оператора делает его особенно полезным при работе с пользовательскими данными, где люди могут случайно использовать разный регистр при вводе одинаковой по смыслу информации.
Пример 2: Поиск частичных совпадений с функцией НАЙТИ
Когда требуется найти вхождение одного текста в другой независимо от точного совпадения, функция НАЙТИ предоставляет эффективное решение для обнаружения частичных соответствий. Этот метод особенно полезен при работе с данными, где одно значение может содержаться внутри другого, например, при поиске названий городов в адресах или ключевых слов в описаниях товаров.
Функция НАЙТИ не чувствительна к регистру символов и возвращает позицию первого вхождения искомого текста или ошибку, если совпадение не найдено. Для получения логического результата функцию часто комбинируют с ЕОШИБКА, которая преобразует ошибку в понятное значение ЛОЖЬ.
=НЕ(ЕОШИБКА(НАЙТИ(B4;A4)))
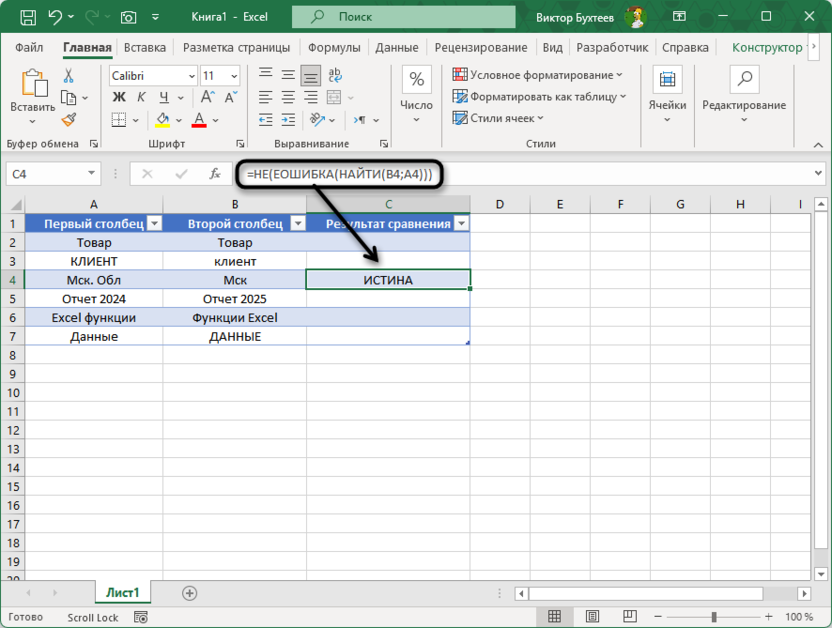
Для сравнения «Мск. обл» и «Мск» формула вернет ИСТИНА, поскольку слово «Мск» содержится в более длинной фразе. Функция НАЙТИ находит вхождение второго значения в первом без учета регистра и возвращает позицию найденного текста, которая затем преобразуется в логическое значение.
Метод эффективно работает с названиями регионов, адресами, описаниями товаров и другими данными, где важно найти смысловые связи между записями. Возможность поиска подстрок открывает широкие возможности для анализа текстовых данных и создания интеллектуальных систем сопоставления информации. Результат помогает выявить скрытые связи между данными, которые не очевидны при точном сравнении.
Пример 3: Точное сравнение с учетом регистра через функцию СОВПАД
Когда требуется строгое сравнение с учетом регистра символов, используется функция СОВПАД, которая проверяет абсолютное соответствие содержимого ячеек. В отличие от оператора равенства, эта функция чувствительна к различиям между заглавными и строчными буквами, что критически важно при работе с кодами, паролями, артикулами товаров или другими данными, где регистр имеет значение.
Функция СОВПАД возвращает ИСТИНА только при полном совпадении всех символов, включая их регистр, пробелы и специальные знаки. Этот метод обеспечивает максимальную строгость проверки и исключает ложные совпадения, вызванные различиями в написании. При работе с формальными данными, требующими точного соответствия, функция СОВПАД становится незаменимым инструментом контроля качества.
=СОВПАД(A7;B7)
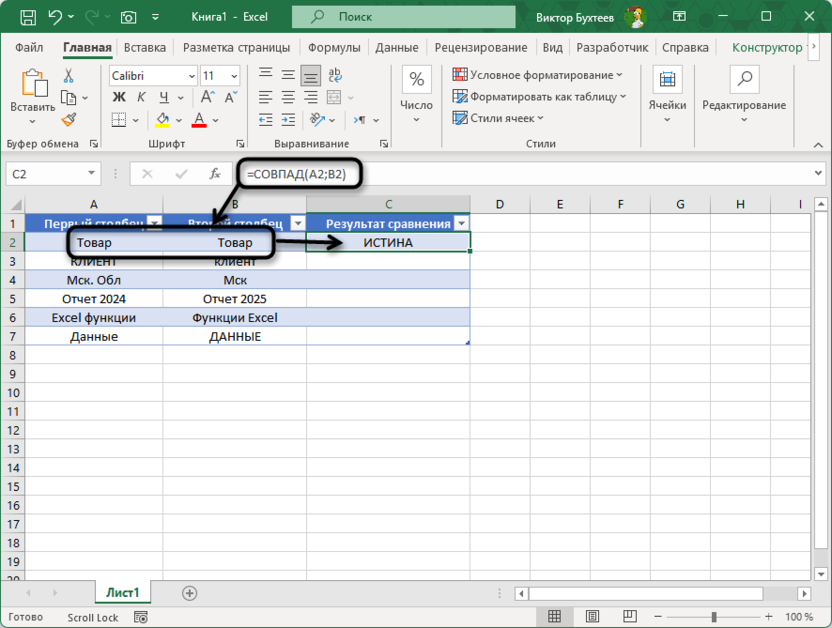
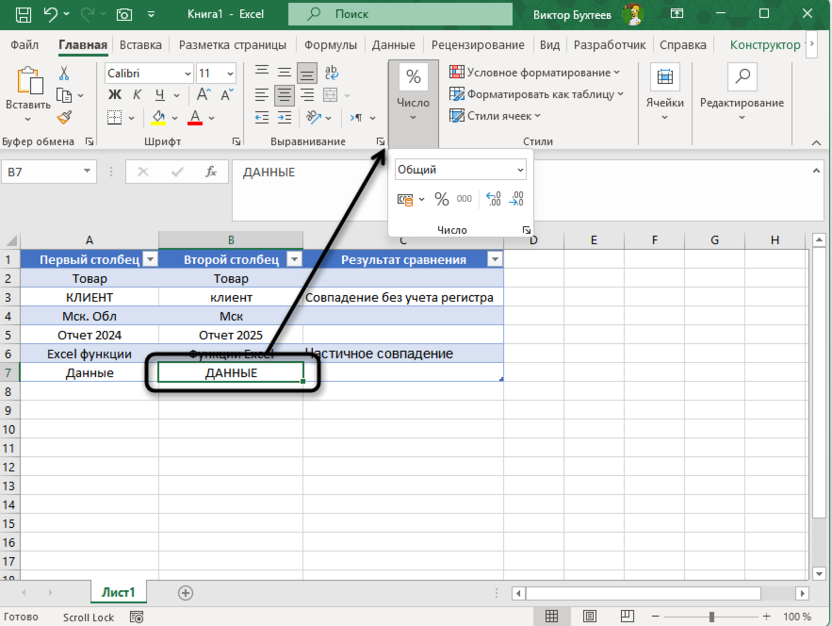
При сравнении «Данные» и «ДАННЫЕ» функция вернет ЛОЖЬ, поскольку строго различает регистр символов в отличие от обычного оператора равенства. Функция СОВПАД обеспечивает абсолютную точность сравнения, что особенно важно при работе с системными данными, где регистр может влиять на функциональность.
Подобная реализация незаменима при проверке паролей, кодов доступа, системных имен файлов и других критически важных данных. Строгое соблюдение регистра помогает избежать ошибок в системах, где «Admin» и «admin» могут означать разные уровни доступа. Использование СОВПАД обеспечивает профессиональный уровень контроля данных в корпоративных системах.
Пример 4: Расширенное сравнение с интерпретацией результата
В задачах, где необходимо определить степень схожести между двумя строками, особенно при анализе данных с ручным вводом, может использоваться комплексный подход, основанный на последовательной проверке нескольких условий. Такой способ не ограничивается простым сравнением значений, а включает логику, которая позволяет Excel возвращать текстовое описание результата, понятное для пользователя. Это особенно полезно, когда важна не только точность совпадения, но и понимание, насколько данные близки друг к другу.
=ЕСЛИ(СОВПАД(A6;B6);"Полное совпадение";ЕСЛИ(СЖПРОБЕЛЫ(СТРОЧН(A6))=СЖПРОБЕЛЫ(СТРОЧН(B6));"Совпадение без учета регистра";ЕСЛИ(ИЛИ(НЕ(ЕПУСТО(ПОИСК(СТРОЧН(B6);СТРОЧН(A6))));НЕ(ЕПУСТО(ПОИСК(СТРОЧН(A6);СТРОЧН(B6)))));"Частичное совпадение";"Совпадений нет")))
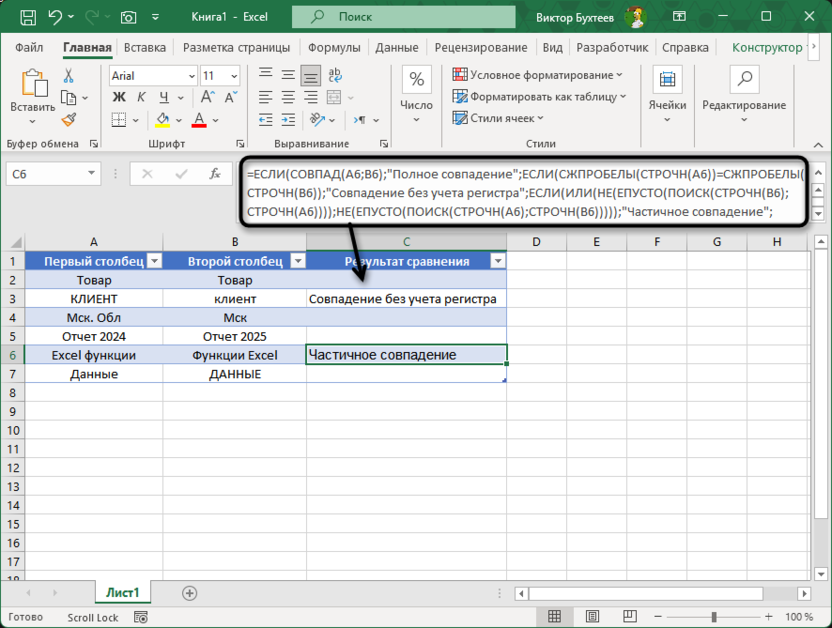 Для примера можно рассмотреть сравнение содержимого разных ячеек из нашей таблицы. Если значения в этих ячейках идентичны и регистр символов полностью совпадает, формула вернет результат «Полное совпадение». Однако, если отличия касаются только регистра или лишних пробелов, и после приведения обеих строк к нижнему регистру и удаления пробелов они становятся одинаковыми, будет возвращено «Совпадение без учета регистра».
Для примера можно рассмотреть сравнение содержимого разных ячеек из нашей таблицы. Если значения в этих ячейках идентичны и регистр символов полностью совпадает, формула вернет результат «Полное совпадение». Однако, если отличия касаются только регистра или лишних пробелов, и после приведения обеих строк к нижнему регистру и удаления пробелов они становятся одинаковыми, будет возвращено «Совпадение без учета регистра».
В случаях, когда одна строка содержится внутри другой (например, «Excel функции» и «Функции Excel»), формула определяет это как «Частичное совпадение», даже если порядок слов различается. Такая проверка осуществляется через встроенную функцию ПОИСК, которая анализирует вхождения текста в обе стороны – это позволяет охватить больше ситуаций.
Если ни одно из условий не выполняется – значения полностью разные и не пересекаются ни по структуре, ни по содержанию, формула возвращает «Совпадений нет».
Советы по эффективному сравнению ячеек
При работе со сравнением ячеек важно учитывать специфику данных и выбирать подходящий метод для каждой конкретной ситуации. Перед сравнением рекомендуется очистить данные от лишних пробелов с помощью функции СЖПРОБЕЛЫ, особенно при работе с информацией, скопированной из внешних источников.
Для больших массивов данных стоит использовать простые операторы вместо сложных формул для повышения производительности. При создании системы массового сравнения полезно комбинировать условное форматирование с формулами для визуального выделения различий и совпадений.
Важно помнить о влиянии типов данных на результат сравнения – числа, введенные как текст, не будут равны числовым значениям даже при визуальном сходстве. Для повышения надежности результатов рекомендуется тестировать формулы на контрольных данных с известными различиями и совпадениями.
При работе с международными данными следует учитывать особенности кодировки символов и региональные настройки Excel, которые могут влиять на результат текстового сравнения.
Заключение
Сравнение ячеек в Excel представляет собой мощный инструмент анализа данных, предлагающий различные подходы для решения специфических задач сопоставления информации. От простого оператора равенства до сложных комбинированных формул – каждый метод имеет свою область применения и преимущества в зависимости от требований к точности и гибкости анализа.
Выбор оптимального способа сравнения определяется характером данных, необходимой степенью детализации результата и объемом обрабатываемой информации. Владение различными техниками сравнения позволяет создавать эффективные системы контроля качества данных, автоматизировать процессы проверки соответствия и выявлять скрытые закономерности в больших массивах информации.






Комментарии