




Рассказываю, как соединить популярнейшую CMS и перспективный фреймворк, сделать из них сайт своей мечты, не жертвуя производительностью, не загоняя себя в рамки возможностей WordPress и не тратя время на изучение других бэкенд-инструментов. Пособие для фронтендеров.
Зачем это нужно?
У многих возникает вопрос, зачем задействовать громоздкий WordPress и комбинировать его с современными технологиями по типу Svelte. Причина кроется в простоте WordPress. Он безумно популярен и очень часто используется для создания сайтов без каких-либо сторонних фреймворков. Стал он таким благодаря простой системе настройки, позволяющей вообще не писать код. И отчасти нам это на руку, так как мы хотим заниматься исключительно фронтенд-частью, а бэкенд оставить на откуп WP.
WordPress справляется с этой задачей на ура. Там уже есть неплохой редактор статей, можно управлять разделами сайта, добавлять теги, всячески настраивать отображение контента и т.п. Все с минимальными трудозатратами.
А еще использование стороннего фронтенда позволяет избежать трех серьезных недостатков WordPress:
-
Вас больше не будут сковывать настройки интерфейса, доступные только в WP. Не нужно будет платить деньги за примитивные плагины и за мало-мальски симпатичные темы оформления, ведь можно будет сделать свою.
-
Вам не придется жертвовать производительностью сайта (фронтенд-составляющая WP-сайтов печально известна не самой высокой скоростью работы).
-
Ну и гораздо меньше придется беспокоиться об обнаружении очередной уязвимости в теме или плагине для WordPress, которые появляются с завидной регулярностью.
Итак, с мотивацией разобрались. Теперь можно перейти к стадии первичной настройки.
Настраиваем локальный сайт на WordPress
Разработку начнем в локальной копии сайта с WP, так как по ходу изменения интерфейса часто придется обращаться к админ-панели CMS и что-то в ней менять; не хотелось бы зависеть от хостинга на этапе проектировки интерфейса и реализации базовой логики фронтенд-составляющей сайта. Но мудрить с проработкой WordPress на локальной машине не будем. Для этого есть программа Local – специальная утилита, позволяющая в пару нажатий запустить на своем компьютере полноценный сервер с предустановленным WordPress.
-
Заходим на официальный сайт приложения Local.
-
Скачиваем копию для своей операционной системы, нажав на Download for free и указав свои персональные данные.
-
Устанавливаем Local в свою систему и запускаем.
-
Нажимаем на кнопку Create a new site.
-
По ходу настройки указываем имя пользователя и пароль от админ-панели (бэкенд-части сайта).
-
Ждем, пока Local скачает все необходимые компоненты и выдаст адрес сайта.
Как только появится список параметров сайта и ссылки Admin и Open Site, наш локальный WP-блог будет готов к работе.
Устанавливаем плагин GraphQL
Для работы с WordPress через сторонний фронтенд-стек нам необходимо использовать какую-либо схему взаимодействия с данными на сайте. Можно пойти путем анализа JSON-объектов, вручную перебирая весь доступный контент. А можно воспользоваться схемой GraphQL, которая часто используется для настройки запросов из фронта к базам данных.
GraphQL – это утилита для создания специального синтаксиса управления информацией из базы данных. Она существует в виде плагина для WordPress, и при ее установке WP начинает выступать в роли базы данных для любого фронтенда на ваш вкус.
-
Открываем раздел с плагинами в админ-панели WordPress.
-
В списке всех расширений ищем WPGraphQL.
-
Устанавливаем его и активируем.
-
Затем находим в боковой панели WP пункт WPGraphQL и пункт «Настройки». Переходим в него.
В настройках плагина будет размещена ссылка, которая понадобится нам на дальнейших этапах настройки, так что не закрываем эту страницу.
Настраиваем SvelteKit
Уже можно говорить о том, что наш бэкенд готов. Блог крутится на локальной машине и доступен из любого браузера. Фронтенд мы будем готовить уже на базе другого локального сервера, который будет работать параллельно и обращаться к тем данным, что имеются в WordPress. Данные будут запрашиваться через GraphQL.
Для этого:
-
Создаем отдельную директорию под SvelteKit-приложение и назовем ее, к примеру, svelteWPBlog.
-
Заходим в эту директорию через терминал (командную строку).
-
Вводим команду npm init svelte@next.
-
Жмем Enter, чтобы проект загрузился в ту директорию, в которой мы находимся.
-
Выбираем Skeleton Project в качестве основы приложения.
-
Отказываемся от всех благ в духе TypeScript и т.п.
-
Затем вводим команду npm install, чтобы подгрузить все необходимые зависимые пакеты.
Далее нам необходимо создать хранилище локальных переменных окружения. Это специальные переменные с ключевым словом VITE в начале (для подключения к упаковщику файлов Vite), содержащие любые данные, которые могут понадобиться будущему приложению.
-
Создаем в папке проекта файл с названием .evn.local.
-
В качестве содержимого файла указываем директиву, хранящую ссылку на GraphQL-компонент нашей локальной копии WordPress. То есть надо скопировать ссылку из настроек плагина GraphQL и записать ее в .env.local. Получится что-то в таком духе:
VITE_PUBLIC_WORDPRESS_API_URL=http://localwp.com/graphql
Загвоздка в том, что у вас может не быть установлена утилита для передачи информации о переменных окружения. Утилита называется dotenv, и ее часто приходится устанавливать вручную. Для этого, находясь в директории с проектом, не поленитесь ввести в терминал команду npm install dotenv. Это поможет избежать ошибок на следующем этапе, где мы будем описывать фронтенд-составляющую приложения, используя данные из WordPress и синтаксис Svelte.
После этого запустим нашу программу на локальном сервере. Для этого достаточно ввести команду npm run dev. Через несколько секунд наш проект будет доступен по адресу localhost::3000. Открываем эту ссылку, чтобы наблюдать за изменениями в приложении (WordPress-сайт тоже должен оставаться активен на протяжении всего процесса разработки).
Создаем главную страницу для отображения контента из WordPress
В предыдущей главе мы создавали переменную для подключения к нашему сайту. Далее мы продолжим ее использовать, чтобы делать запросы через JavaScript и добывать нужный контент из нашей импровизированный базы данных.
Теперь переходим непосредственно к приложению. Можно открыть его в любом текстовом редакторе, но я, как и раньше, советую VS Code.
-
Запускаем редактор.
-
Ищем файл index.svelte в директории src. Это корневой документ нашего сайта. Первый файл, что будет загружен при попытке зайти в наше приложение через браузер. Здесь мы и разместим список статей, чтобы далеко не ходить.
-
Удаляем содержимое документа и готовимся формировать новое.
Создаем схему общения между фронтендом и бэкендом
Логику запросов к импровизированной базе данных будем записывать внутри тега script, помеченного как модуль. То есть сначала открываем тег <script context="module"> </script> и внутри него пишем код.
Первое, что напишем – схему обращения к GraphQL. Это определенный набор свойств, позволяющий более четко понимать, какую информацию мы получим из базы в конкретном компоненте приложения. Нам не придется гадать и самостоятельно перебирать огромную кипу информации, содержащуюся внутри WordPress-приложения. Благодаря GraphQL мы выберем только необходимые элементы.
Но нам не придется вручную описывать схему и ориентироваться на документацию по мере свершения этих действий. Мы воспользуемся графической утилитой GraphQL, доступной непосредственно в настройках плагина для WP.
Открыв утилиту GraphiQL, вы заметите большой список тегов. Все это – различные данные о вашем сайте. Статьи, теги, картинки, страницы, комментарии и многое другое. Но это не их конкретное появление на сайте, а что-то вроде ключей в объектах, позволяющих обращаться к реальным данным через их описательную модель. В этой панели нужно нажать на тем элементы, что понадобятся в итоговом проекте. Я, например, выбрал папку posts, в ней папку nodes, а внутри выбрал свойства title, uri, content, featuredImage (с соответствующими значениями внутри). В итоге получилась следующая схема обращения к бэкенду:
query MyQuery {
posts {
nodes {
title
uri
content
featuredImage {
node {
mediaItemUrl
}
}
}
}
}
С помощью такой схемы я буду запрашивать со своего WordPress-бэкенда название статьи, ссылку на нее, ссылку на картинку и само содержимое поста.
Делаем запрос к списку статей
У нас есть схема, по которой можно сделать запрос, но еще нет самого запроса. Так что сейчас займемся его реализацией.
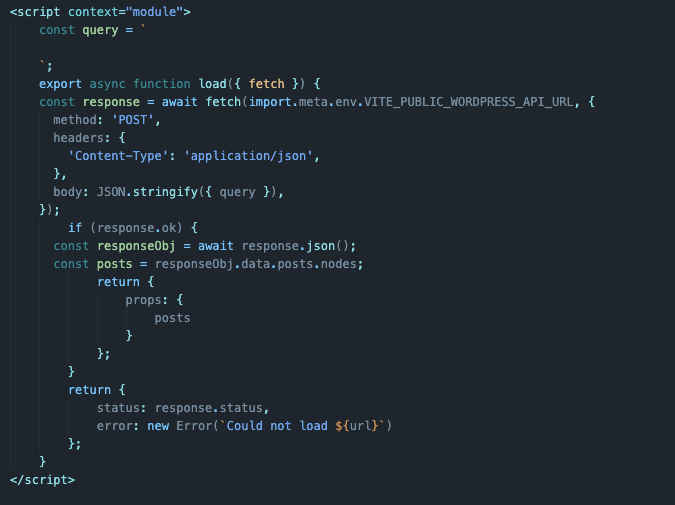
Вот как будет выглядеть код по итогу. Сейчас мы его построчно разберем.
-
Сначала экспортируем асинхронную функцию под названием load, которая принимает функцию fetch в качестве аргумента. Это основа нашего запроса.
export async function load({ fetch }) -
В теле этой функции мы будем постепенно собирать необходимые данные и начнем с fetch-запроса к базе данных (к нашему локальному WordPress-сайту). Для этого будет использована ранее установленная переменная окружения. Ну и для удобства будем хранить данные из запроса в переменной response.
const response = await fetch(import.meta.env.VITE_PUBLIC_WORDPRESS_API_URL, { }) -
В теле запроса все по стандарту. Мы называем тип метода, прописываем заголовки и указываем тело запроса. В общем, следуем правилам типичного HTTP-запроса, указывая в качестве тела нашу схему, созданную ранее для GraphQL.
method: "POST", header: { "Content-Type": 'application/json', }, body: JSON.stringify({ query }), -
Описанных выше функций достаточно для получения необходимого ответа от базы данных, но теперь эту информацию надо обработать. Создадим условие, при котором будет отрисовываться интерфейс (то есть при успешном запросе к БД).
if (reponse.ok) { } -
В теле условного выражения создаем переменную ResponseObj, хранящую в себе ответ от сервера в формате JSON.
const responseObj = await response.json()
-
Затем создаем переменную, которая будет хранить в себе объекты с постами, готовые к отображению на сайте.
const posts = responseObj.data.posts.nodes
-
И из этой же функции возвращаем элементы props с постами из бэкенда.
return { props: { posts } } -
Также необходимо предусмотреть поведение программы на тот случай, если не удастся получить внятного ответа от сервера. Такое тоже может быть, поэтому после условия необходимо сделать возврат ошибки на случай сбоя в работе сайта. Для этого отправим пользователю статус запроса и стандартное сообщение об ошибке.
return { status: response.status, error: new Error('Не получилось загрузить данные из ${url}') }
Готово. Мы получили доступ к информации о контенте, хранящемся в бэкенд-составляющей проекта. Теперь эту информацию можно отправить дальше, отобразив все необходимое на странице сайта.
Отрисовываем список статей в интерфейсе сайта
Для отрисовки мы будем использовать переменную posts, выданную нам из запроса к базе данных, но чтобы получить к ней доступ непосредственно из приложения, необходимо сначала провести экспорт переменной. Для этого:
-
Открываем еще один тег <script>, но уже без контекста.
-
Внутрь экспортируем переменную posts:
export let posts
Программа знает о ее существовании, потому что соответствующий props был передан из модуля при запросе к БД.
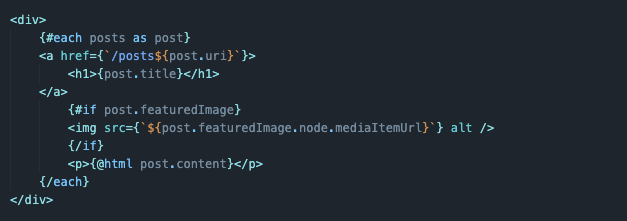
Теперь создаем интерфейс. Мы обернем весь контент в один тег <div> и перебором отобразим каждую статью с базовым набором данных (картинкой, названием и текстом). Вот как это выглядит:
Сейчас поясню, что означает этот код:
-
Сначала мы создаем общий блок, в котором будет отображаться нужный нам контент: <div> </div>.
-
Внутри я запускаю перебор информации, используя синтаксис Svelte. То есть свойство each, примененное на переменную posts, которая хранит в себе массив с объектами-статьями.
{#each posts as post} {/each} -
Непосредственно в переборе я указываю название статьи. Оно, соответственно, подтягивается из каждого объекта.
<h1>{post.title}</h1> -
Затем я проверяю, есть ли у статьи изображение. Для этого используется свойство if, включенное в синтаксис Svelte.
{#if} {/if} -
И если картинка имеется, то она отрисовывается на экране. Создается компонент img, содержащий в себе ссылку на изображение, которое было взято из нашего запроса к базе данных (при желании можно в схеме прописать запрос к альтернативному тексту и его тоже записывать).
<img src={`${post.featuredImage.node.mediaItemUrl}`} alt /> -
И в конце добавляю сам текст статьи со свойством @html, чтобы все стили и прочие элементы, которые могут попасть в статью, корректно отображались либо исчезли из текста.
<p> {@html post.content} </p>
Это самый примитивный вариант. Мы сделаем его чуть симпатичнее позже, но уже сейчас можно поглядеть, как это выглядит на localhost::3000. Все, что мы добавили, действительно отображается на сайте.
Но стилизацией мы будем заниматься немного позже Сейчас необходимо сделать отдельные страницы для статей, чтобы на главной отображались только отрывки, а при клике показывалась полноценная статья на отдельном адресе.
Создаем страницу для отображения отдельных статей из WordPress
Большую часть действий, что мы выполнили в предыдущей главе, придется повторить с небольшими изменениями, чтобы запрашивать с сайта обновленный сет данных (в нашем случае – информацию о конкретной статье, по адресу которой перешел пользователь).
Перед началом необходимо создать папку posts в директории src, а внутри нее создать файл с названием [slug].svelte. Это динамическим меняющийся документ, отображающий тот набор данных, который требует пользователь. Далее начнем описывать его содержимое.
Создаем схему для запросов к информации о конкретной статье
Здесь схема будет немного сложнее, так как от нас потребуется передавать в GraphQL идентификационный номер статьи. Это необходимо, чтобы еще на этапе запроса к базе отфильтровать ненужную информацию и не заниматься реализацией поиска через JavaScript.
Для этого создадим переменную query в блоке <script context="module"> </script>, тут пока все по классике, а вот содержимое переменной поменяется:
query MyQuery($slug: ID!) {
post(id: $slug idType: SLUG) {
content,
date,
title,
featuredImage {
node {
mediaItemUrl
}
}
}
}
Сначала мы указываем аргументы для самого запроса.
-
Надо прописать тип переменной $slug. В нашем случае это ID статьи.
-
Потом в схеме прописываем запрос к post, также указываем id. У нас будет использоваться $slug.
-
Далее можно указывать свойства на свое усмотрение. Я взял контент, дату, название и картинку. Сюда же можно добавить теги, автора или другую полезную информацию о материале.
Обновленная схема готова. Можете перед началом применения потестировать ее в GraphiQL.
Делаем запрос к базе данных
Запрос во многом будет похож на тот, что уже был, но мы разберем его повторно, чтобы не возникло путаницы.
-
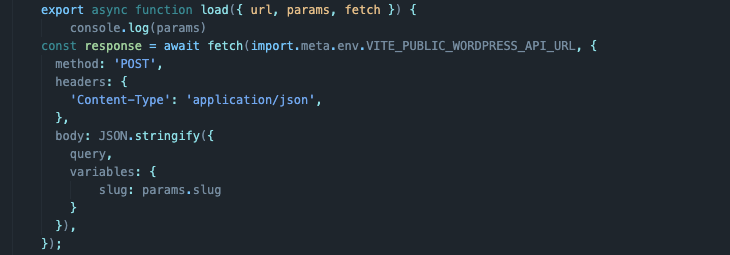
Экспортируем функцию load, которая на этот раз принимает на два аргумента больше. Необходимо отправить в эту функцию еще url и params. Это обновленные компоненты в Svelte, позволяющие получить информацию о странице, сгенерированную в момент перехода на нее.
export async function load({ url, params, fetch }) { } -
В теле функции снова делаем запрос к базе данных. Создаем переменную response и повторяем запрос из предыдущей главы, но редактируем содержимое body, так как на этот раз нам нужно передать не только запрос, но еще и указать отдельную переменную для ID. То есть взять данные, формируемые при переходе по ссылке, и отправить их в GraphQL, чтобы затем вернуть себе подходящую информацию о конкретной выбранной статье.
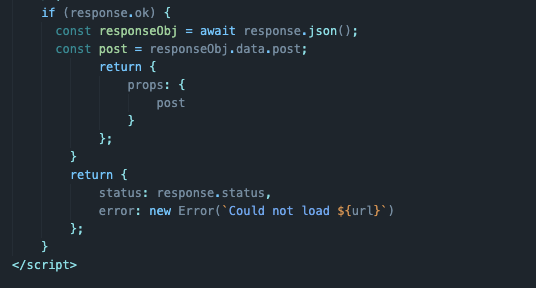
const resposne = await fetch(import.meta.env.VITE_PUBLIC_WORDPRESS_API_URL, { method: "POST", headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ query, variables: { slug: params.slug } }) }) -
Также меняем переменную posts на post и корректируем ее содержимое.
const post = responseObj.data.post
-
И заменяем возврат props с названием posts на post.
Оставшуюся часть скрипта менять необязательно. В ней все подходит и для конкретного поста, и для всех сразу.
Отрисовываем статью в интерфейсе
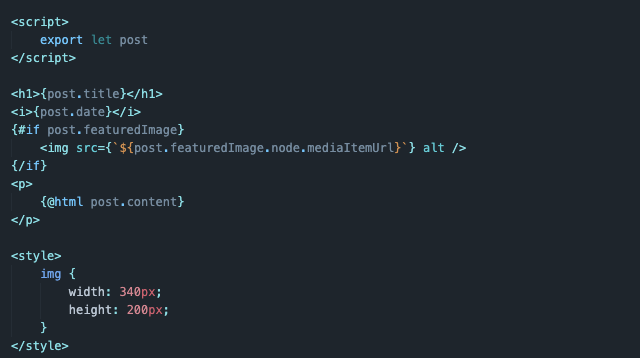
Процедура отрисовки контента для одной статьи почти не отличается от такого для нескольких. Разница заключается лишь в отсутствии перебора. Дело в том, что мы получаем из запроса к серверу только один объект и можем смело работать с ним, не перебирая какой-то массив.
-
Указываем названием материала:
<h1> {post.title} </h1> -
Прописываем дату (я использовал тег i, чтобы использовать шрифт italic).
<i> {post.date} </i> -
Повторяем то же с картинкой. То есть сначала проверяем, есть ли она, а потом отображаем:
{#if post.featuredImage} <img src={`${post.featuredImage.node.mediaItemUrl}`} alt /> {/if} -
И статью:
<p> {@html post.content} </p>
Добавляем slug-ссылку в общем списке статей
Осталось добавить тот самый slug ID, чтобы он передавался при нажатии на название статьи и перенаправлял пользователя на нужный материал. Для этого надо добавить тег href вокруг блока данных post.title в файле index.svelte: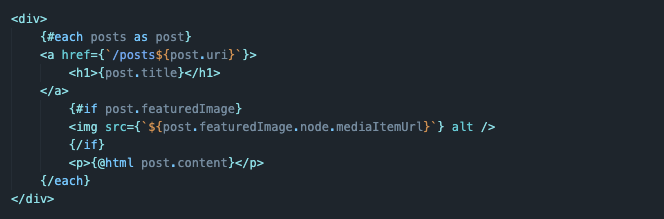 В качестве href необходимо указать uri, так как это постоянная ссылка на материал в WordPress. При нажатии на эту ссылку файл [slug].svelte будет получать постоянный адрес поста и собирать информацию о нем через GraphQL.
В качестве href необходимо указать uri, так как это постоянная ссылка на материал в WordPress. При нажатии на эту ссылку файл [slug].svelte будет получать постоянный адрес поста и собирать информацию о нем через GraphQL.
Вместо заключения
У нас есть локальный ресурс на базе WordPress и фронтенд-сайт, который показывает контент из WP. Да, пока все выглядит не особо симпатично, но в перспективе очевидно, что вы можете самостоятельно настроить дизайн сайта, не обращая внимания на то, какие плагины доступны для WP. То, как будет выглядеть сайт, зависит только от вас. Также такой подход дает возможность добавлять во фронтенд любые сторонние библиотеки. WordPress остается лишь базой данных и редактором для написания статей.
В следующей части статьи мы задеплоим наш сайт на сервер Timeweb, чтобы он был доступен онлайн. Если возникнут вопросы или всплывут какие-то ошибки, напишите о них в комментариях.
Продолжение: Блог на базе WordPress и SvelteKit. Часть 2: Деплой в Timeweb и базовая стилизация






Комментарии
1) "Вас больше не будут сковывать настройки интерфейса, доступные только в WP"
это вообще про что?
про темы вообще бред какой-то написан - не нужно платить деньги за плагины и темы, ведь можно сделать свою))) так сделай свою тему и не плати, собственно это и делается только через изобретение велосипеда с фреймворком)
2) "фронтенд-составляющая WP-сайтов печально известна не самой высокой скоростью работы"
хотелось бы пруфы данного утверждения, откуда вы это взяли? Какие скрипты нужны, такие и используй в теме, при чем тут сам Wordpress вообще. Он не заставляет использовать что-то обязательное, без чего он не будет работать.
можно дополнить и использовать плагин fakerpress для генерации рандомных статей в пару кликов
error: new Error(`Запрос на адрес ${response.url} не доступен`)