




Прайс-листы от поставщиков приходят с артикулами вперемешку с ценами. Отчеты из CRM выгружаются так, что номера заказов слипаются с суммами. Данные с сайтов копируются вместе с форматированием, где телефоны перемешаны с адресами. Типичная картина для тех, кто работает с импортом данных. Вручную разбирать сотни или тысячи строк нереально долго. Google Таблицы решают такие задачи за секунды с помощью правильных инструментов. Разберем все доступные способы: от простых формул до хитрых комбинаций с регулярными выражениями.
Почему числа застревают в тексте
Чаще всего проблема возникает при работе с внешними источниками. Выгрузили данные из учетной системы – получили «Счет №45678 от 15.03.2025». Скопировали таблицу с сайта – вышло «Цена: 15 990 руб.». Импортировали CSV-файл – появилось «+7(926)123-45-67». Система воспринимает все это как обычный текст, хотя внутри спрятаны нужные нам цифры.
Дальше начинаются сложности. Попробуйте посчитать сумму по столбцу, где вместо чисел записано «Оплата 5000р» – формула вернет ошибку. Захотите отфильтровать заказы больше определенной суммы – не получится, ведь «Заказ №123 на 50000 рублей» для таблицы просто набор символов. Вот тут и нужны специальные способы извлечения.
Метод 1: REGEXEXTRACT
Представьте: у вас таблица с тысячей номеров заказов формата «Заказ №12345 на сумму 50000 рублей», и нужно вытащить только первое число – сам номер заказа. Функция REGEXEXTRACT справится мгновенно.
Запишите в ячейке B2 формулу =REGEXEXTRACT(A2;"\d+"). Символы \d+ означают «найди одну или больше цифр подряд». Для нашего примера получится 12345 – именно первое число из строки. Протяните формулу вниз, и все номера заказов окажутся в отдельном столбце.
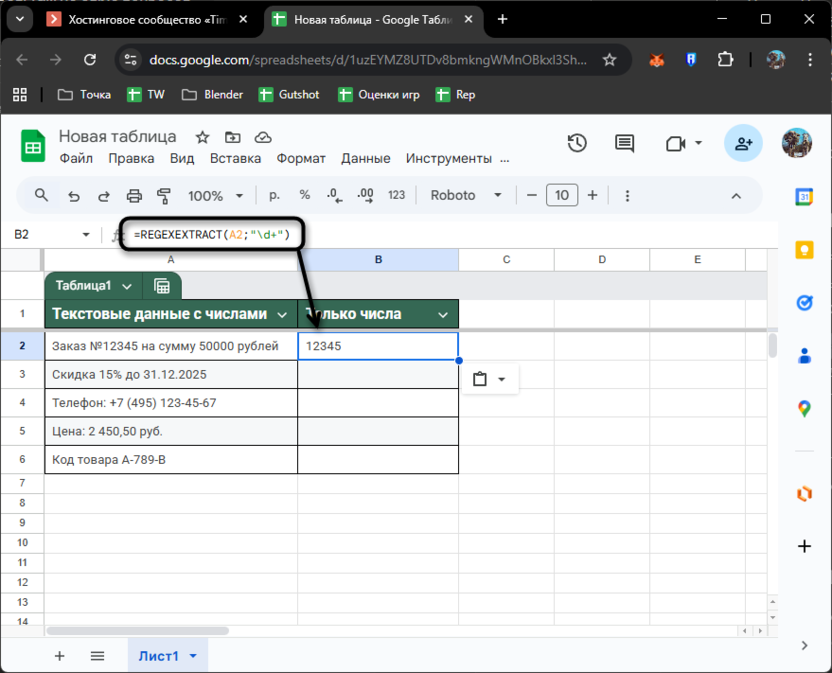
Хитрость в том, что функция ищет первое совпадение и останавливается. Из строки «Код товара A-789-B» вытащится 789, из телефона «+7 (495) 123-45-67» – цифра 7. Если нужно именно такое поведение – отлично. Но что делать, когда в строке несколько чисел и нужно конкретное? Тогда на помощь приходят другие методы, о которых вы прочитаете далее.
Метод 2: REGEXEXTRACT для дробных чисел
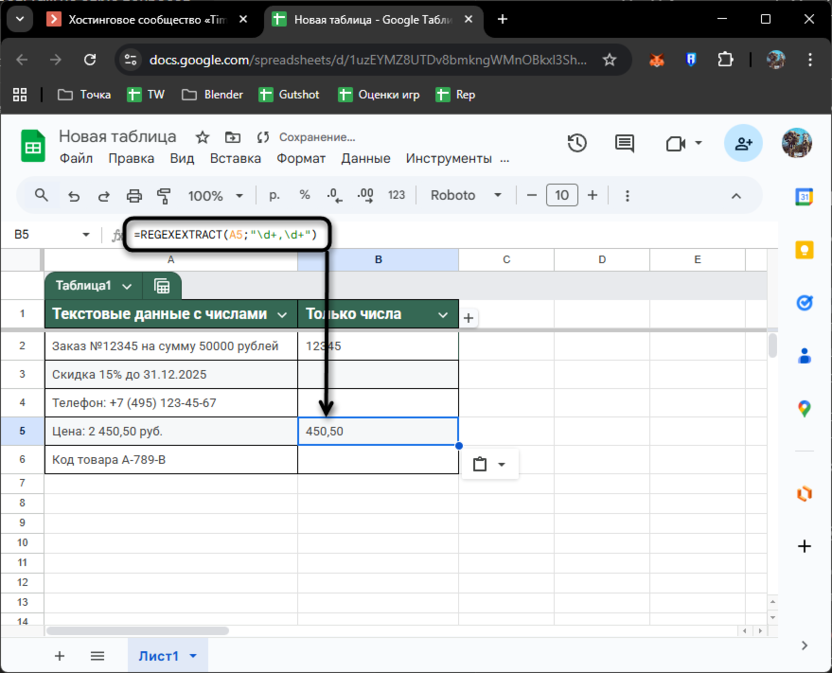
Теперь разберем ситуацию с более сложными конструкциями. Например, в ячейке A5 записана цена «2 450,50 руб.», и нужно извлечь именно дробное число. Обычная формула \d+ вернет только 2 – первые цифры до пробела.
Формула =REGEXEXTRACT(A5;"\d+,\d+") ищет конструкцию «цифры-запятая-цифры». Если говорить про конкретно данный пример, то получим результат 450,50. В некоторых случаях это то, что нужно, однако в этом – потерялась целая часть из-за пробела между разрядами.
Для полного числа нужен другой шаблон: =REGEXEXTRACT(A5;"[\d\s]+,\d+"). Теперь формула захватывает цифры и пробелы перед запятой, выдавая «2 450,50».
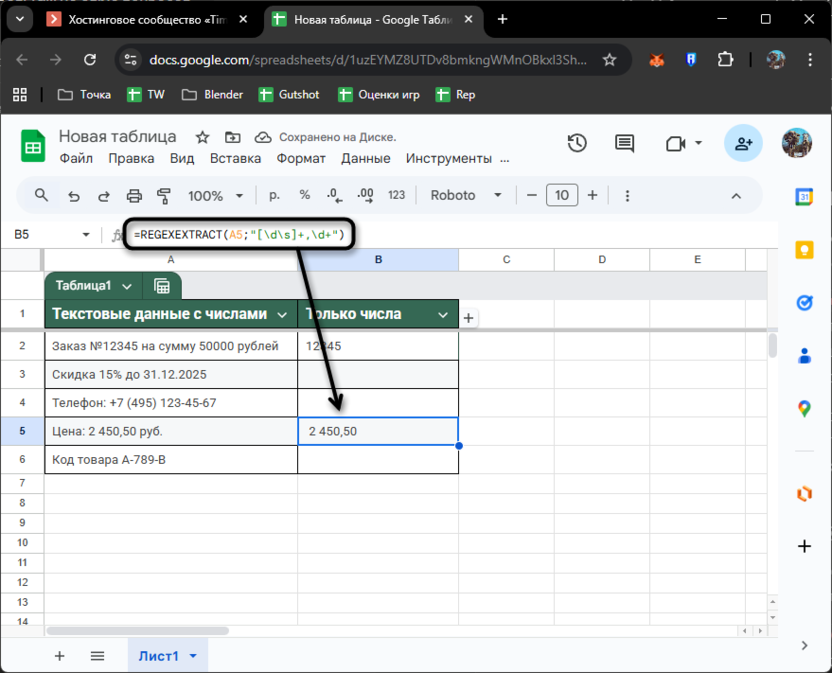
Важный момент: если в данных используется точка вместо запятой (как в англоязычных таблицах), замените запятую на точку в шаблоне: \d+\.\d+. Обратите внимание на обратный слеш перед точкой – без него точка в регулярных выражениях означает «любой символ».
Метод 3: REGEXREPLACE для удаления всего лишнего
Иногда проще пойти от обратного: не искать числа, а удалить все остальное. Особенно когда в строке куча разных символов, а нужны только голые цифры.
Формула =REGEXREPLACE(A2;"[^\d]";"") работает так: шаблон [^\d] означает «любой символ, кроме цифры», а пустые кавычки говорят «замени на ничто». Из «Заказ №12345 на сумму 50000 рублей» получится 1234550000 – все числа склеились в одно.
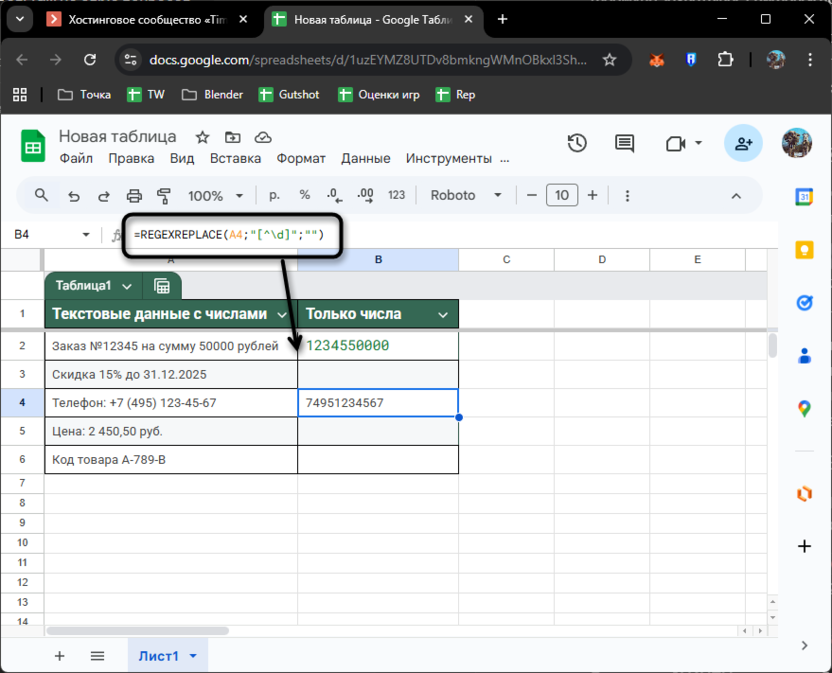
Метод хорош для телефонных номеров. Примените формулу к A4, и из «+7 (495) 123-45-67» останется 74951234567 – чистый номер без форматирования. Правда, тут же кроется подвох: если в строке несколько чисел, они все сольются вместе. Для A2 непонятно, где кончается номер заказа и начинается сумма.
Метод 4: REGEXREPLACE с сохранением разделителей
Работаете с ценами, где разряды разделены пробелами? В таком случае использование предыдущего метода приведет к их уничтожению. Нужен более тонкий подход, который заключается в использовании все той же знакомой функции, но немного с другими аргументами.
Формула =REGEXREPLACE(A5;"[^\d\s,]";"") сохранит цифры, пробелы и запятые. Из «Цена: 2 450,50 руб.» получится «2 450,50» – слово «Цена:» и «руб.» исчезли, структура числа осталась. Теперь нужно убрать пробелы между разрядами и преобразовать в число: =ЗНАЧЕН(ПОДСТАВИТЬ(REGEXREPLACE(A5;"[^\d\s,]";"");" ";"")).
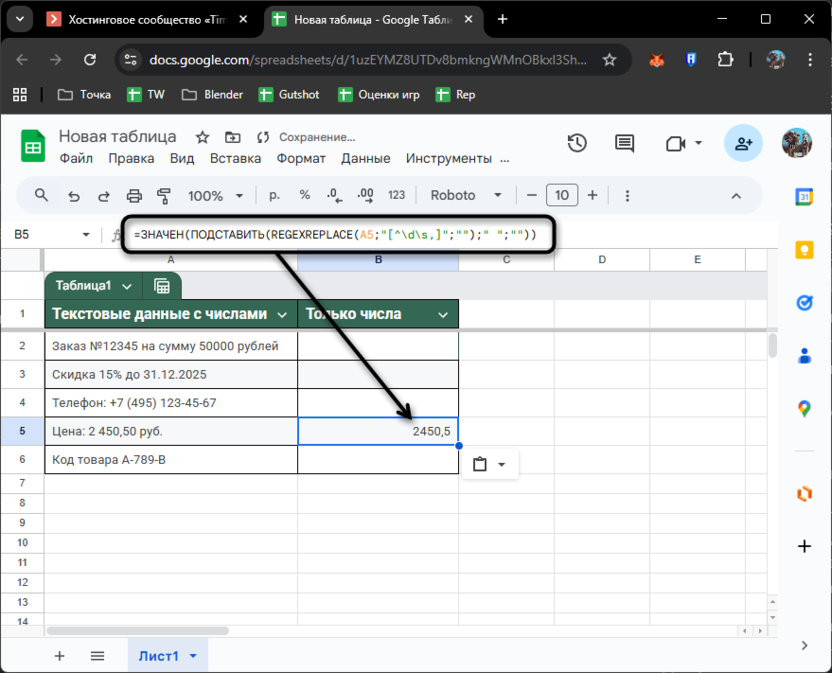
Формула работает в три шага: REGEXREPLACE оставляет только цифры, пробелы и запятые, ПОДСТАВИТЬ удаляет пробелы, ЗНАЧЕН преобразует текст в число. Результат для A5 – число 2450,5, готовое для математических операций.
Метод 5: Текстовые функции для известных позиций
Регулярные выражения бывают довольно полезными и применимы во многих случаях, но иногда избыточные. Если точно знаете, где в строке находится число, текстовые функции справятся быстрее, особенно если мы говорим об обработке огромных массивов с данными.
Взгляните на A2: «Заказ №12345 на сумму 50000 рублей». Номер заказа всегда после символа № и состоит ровно из 5 цифр. Формула =ЗНАЧЕН(ПСТР(A2;НАЙТИ("№";A2)+1;5)) делает следующее: НАЙТИ определяет позицию №, ПСТР вырезает 5 символов после этой позиции, ЗНАЧЕН превращает текст в число.
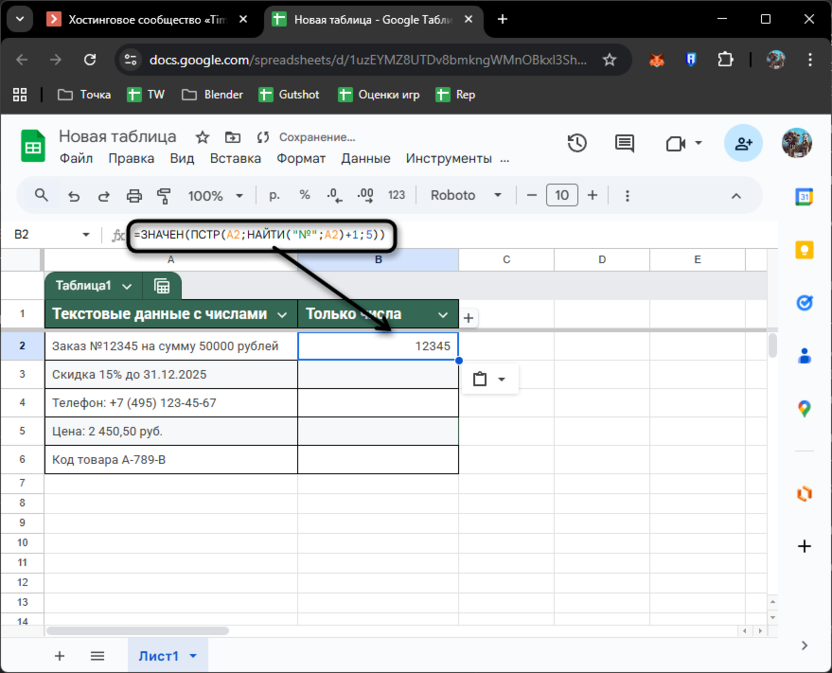
Метод работает безотказно, когда данные структурированы. Допустим, все артикулы начинаются с «A-» и содержат 3 цифры, тогда ничего сложного. Но стоит структуре немного измениться (вместо 5 цифр окажется 6 или артикул будет написан иначе), и формула сломается. Регулярные выражения в этом плане гибче, поэтому нужно понимать, когда применить тот или иной метод.
Метод 6: Извлечение конкретного числа из нескольких
Самая частая задача: в строке несколько чисел, нужно второе. Например, из «Заказ №12345 на сумму 50000 рублей» вытащить именно сумму, а не номер.
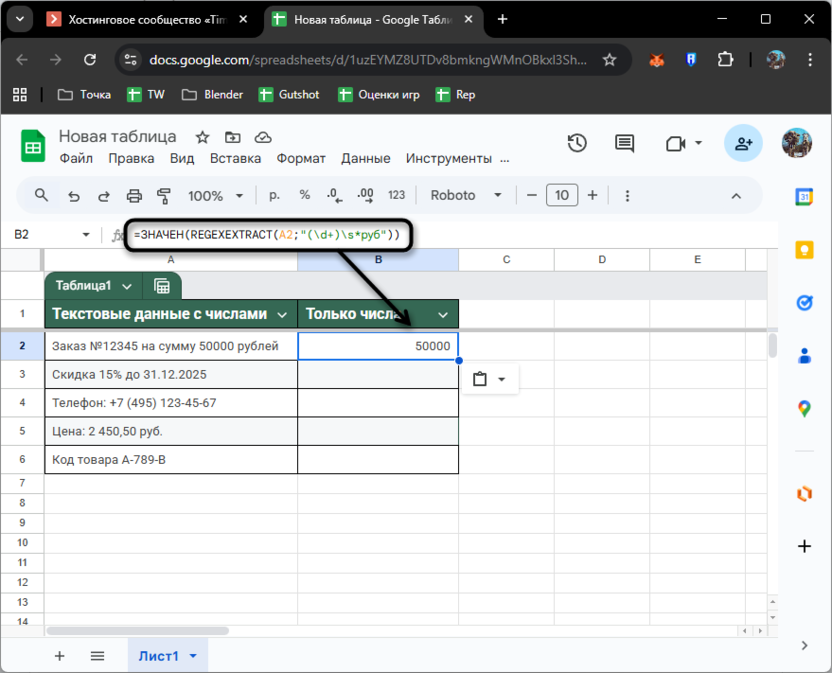
Формула =ЗНАЧЕН(REGEXEXTRACT(A2;"(\d+)\s*руб")) найдет число перед словом «руб» и вернет 50000. Скобки вокруг \d+ создают группу захвата – REGEXEXTRACT вернет только содержимое группы, без самого слова «руб». Шаблон \s* означает «возможно пробелы», что учитывает варианты написания «50000руб» и «50000 руб». Аналогично можно искать числа рядом с любыми маркерами: «%», «шт.», «кг» и так далее.
Другой способ – разбить строку на части и взять нужную. Формула =ЗНАЧЕН(INDEX(SPLIT(СЖПРОБЕЛЫ(REGEXREPLACE(A2;"[^\d ]";" "));" ");2)) сложная, но универсальная.
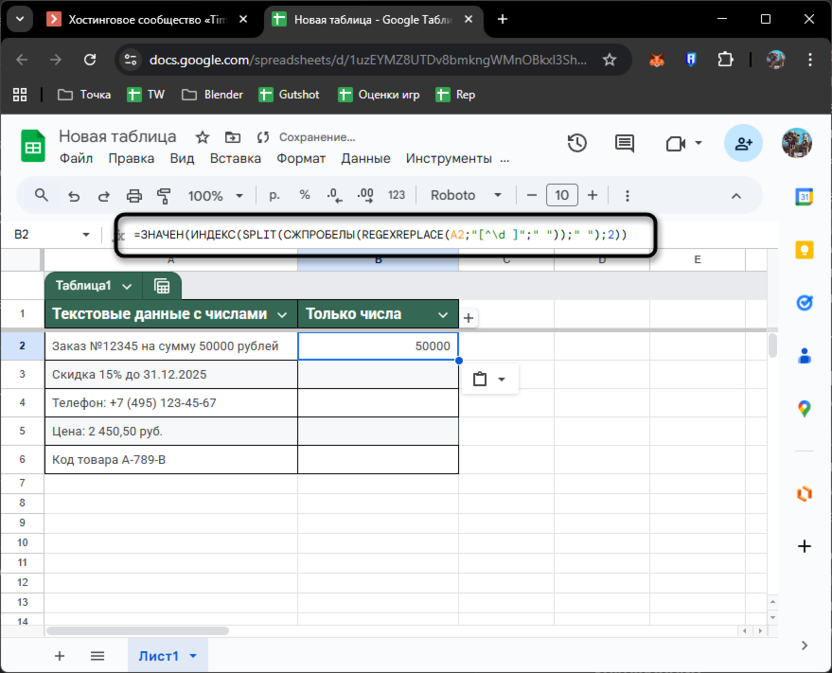
REGEXREPLACE заменяет все нечисловое (кроме пробелов) на пробелы, СЖПРОБЕЛЫ убирает лишние пробелы, SPLIT разбивает строку по пробелам, INDEX берет второй элемент. Получается 50000 – вторая по счету группа цифр.
Метод 7: Массовая обработка
Когда данных много, копировать формулу в каждую ячейку не совсем целесообразно, поскольку просто потратите много времени. Использование ARRAYFORMULA применит формулу сразу ко всему столбцу.
В ячейку B2 впишите =ARRAYFORMULA(ЕСЛИ(A2:A<>"";REGEXEXTRACT(A2:A;"\d+");"")). Конструкция проверяет весь диапазон A2:A: если ячейка не пустая, извлекает первое число, если пустая – оставляет пустой. Результаты мгновенно появятся во всем столбце B, и при добавлении новых строк в столбец A обработка произойдет автоматически.
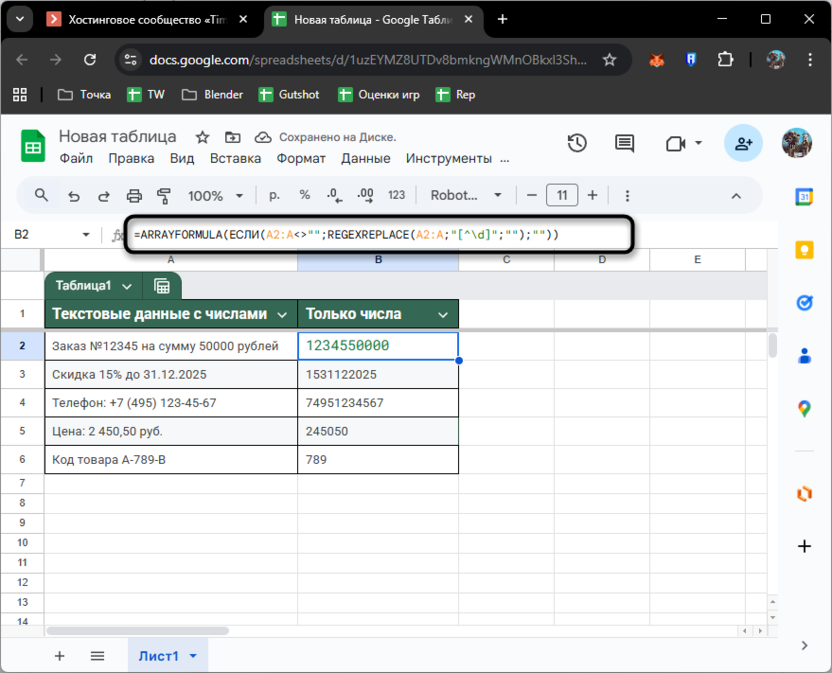
Замените REGEXEXTRACT на любую другую формулу из описанных выше. Если же при этом хотите удалить все нечисловые значения, тогда примените =ARRAYFORMULA(ЕСЛИ(A2:A<>"";REGEXREPLACE(A2:A;"[^\d]";"");"")). Для работы с дробными числами адаптируйте шаблон под свою задачу. Главное – один раз написать формулу, и она заработает для всего массива данных.
Читайте также в Комьюнити:
Заключение
Выбор метода зависит от конкретной задачи. Для извлечения первого попавшегося числа достаточно REGEXEXTRACT с простым шаблоном \d+. Когда нужны все цифры разом, REGEXREPLACE удалит все лишнее. Работа с дробными числами требует добавления запятой или точки в шаблон. В случаях, когда числа всегда находятся в одном месте, текстовые функции ПСТР и НАЙТИ работают быстрее. При наличии нескольких чисел в строке помогут комбинации через INDEX и SPLIT. Большие объемы данных обрабатываются через обертку в ARRAYFORMULA.
Ключевой момент – понимание структуры данных. Несколько минут на анализ расположения чисел, окружающих символов и регулярно встречающихся паттернов помогут выбрать правильный инструмент и сэкономят часы ручной работы.





Комментарии