




Функция LAMBDA открыла в Google Таблицах возможность создавать собственные вычислительные блоки прямо в ячейке, без кода и скриптов. Если вы еще не знакомы с ней, советую сначала прочитать отдельную статью о LAMBDA на нашем сайте – она станет хорошей отправной точкой, поскольку все четыре функции из этого материала работают именно на ее основе.
Читайте также в Комьюнити: Использование функции LAMBDA в Google Таблицах
MAP, BYROW, BYCOL и SCAN появились в Google Таблицах в 2022-2023 году как вспомогательные инструменты семейства LAMBDA. Задача у них общая: применить заданную логику к массиву данных, не заставляя пользователя писать формулу для каждой строки или столбца отдельно. При этом каждая функция делает это по-своему: MAP работает с отдельными элементами, BYROW и BYCOL – со строками и столбцами целиком, а SCAN накапливает результат по мере обхода массива. Ниже на конкретных примерах разберем, как и когда применять каждую из них.
Таблица для примеров
Все примеры в статье построены на одной таблице с данными о продажах пяти менеджеров. Вы можете воссоздать ее у себя или сразу применять приведенные формулы к собственным диапазонам – важно лишь подставить нужные ссылки на ячейки.
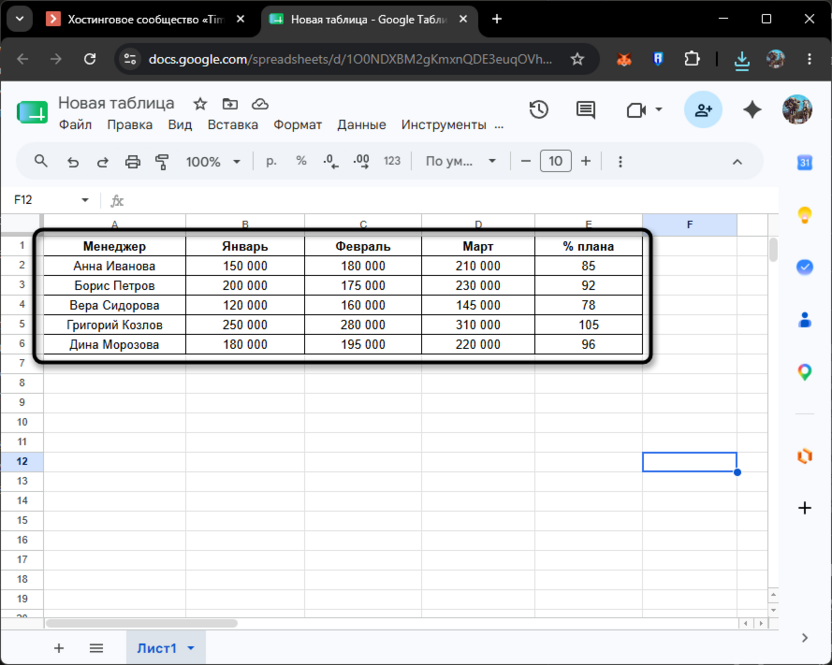
Заголовки расположены в строке 1, данные – в строках 2-6. Имена менеджеров занимают столбец A, продажи по месяцам – столбцы B, C и D, процент выполнения плана – столбец E.
Такая структура удобна для демонстрации сразу нескольких подходов. Три столбца с числами по месяцам дают возможность показать, как работают функции, обходящие данные по строкам и по столбцам. Отдельный столбец с процентами пригодится для поэлементных преобразований. А числа в столбце «Январь», выстроенные в один вертикальный ряд, наглядно покажут, как SCAN накапливает результат шаг за шагом.
Пример 1: Функция MAP
MAP применяет заданную формулу к каждому элементу массива и возвращает новый массив той же формы. Проще всего представить ее как конвейер: данные заходят с одной стороны, на каждый элемент применяется одна и та же операция, и с другой стороны выходит обработанный массив.
Синтаксис функции:
=MAP(массив1; [массив2; ...]; LAMBDA(имя1; [имя2; ...]; формула))
Если передается один массив, LAMBDA принимает один параметр. Если два – два параметра, и формула применяется к соответствующим элементам обоих массивов одновременно.
Допустим, руководителю неудобно смотреть на голые проценты и он хочет видеть рядом с каждым менеджером текстовый статус: «Перевыполнен», «Выполнен» или «Не выполнен». Значения уже есть в столбце E, и MAP пройдет по каждому из них, вынесет вердикт и вернет столбец с готовыми подписями.
=MAP(массив1; [массив2; ...]; LAMBDA(имя1; [имя2; ...]; формула))
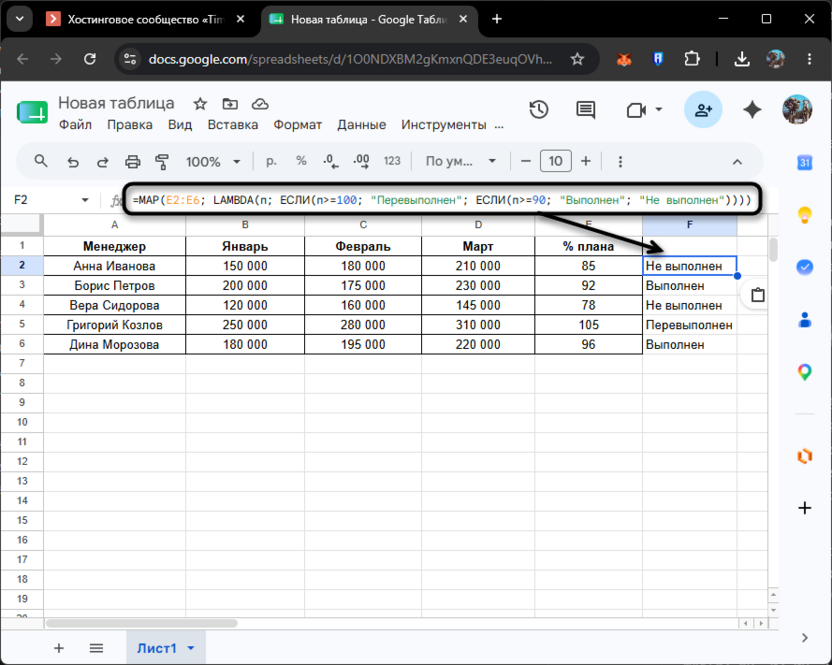
MAP пройдет по каждой ячейке диапазона E2:E6, передаст ее значение в параметр п и вернет соответствующий текст. Ту же задачу можно решить через ARRAYFORMULA с ЕСЛИ, но MAP делает логику нагляднее: видно, что формула работает с одним элементом п, и проще отслеживать вложенные условия.
Если передать два массива, MAP будет обрабатывать соответствующие пары элементов. Допустим, в столбец G добавлены индивидуальные коэффициенты бонуса для каждого менеджера: 1.05, 1.10, 1.00, 1.15, 1.08. Тогда скорректированные продажи за январь с учетом бонуса считаются так:
=MAP(B2:B6; G2:G6; LAMBDA(продажи; коэф; продажи*коэф))
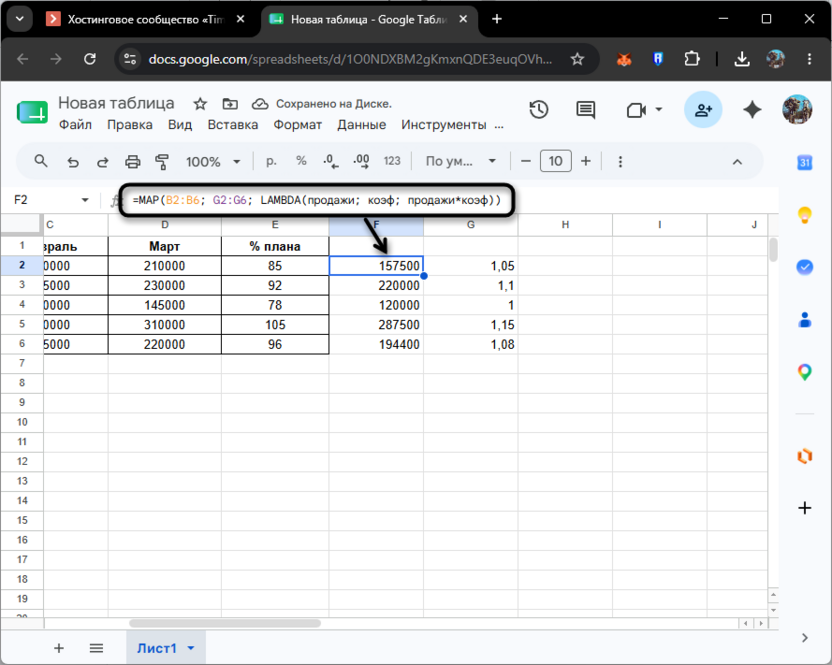
Формула возьмет B2 и G2, затем B3 и G3 – и так по каждой паре, вернув столбец с результатами.
Пример 2: Функция BYROW
BYROW применяет формулу к каждой строке диапазона и возвращает один столбец результатов. Если MAP обрабатывает отдельные ячейки, то BYROW работает сразу со всей строкой как с единицей данных. Параметр внутри LAMBDA – это не одно значение, а одностроковый диапазон, поэтому к нему можно применять агрегатные функции: СУММ, МАКС, МИН, СРЗНАЧ и другие.
Синтаксис функции:
=BYROW(массив; LAMBDA(строка; формула))
Предположим, нужно добавить к таблице столбец с суммарными продажами каждого менеджера за квартал. Стандартный подход – написать =СУММ(B2:D2) в одну ячейку и протянуть формулу вниз на пять строк. BYROW делает то же самое одной формулой без протягивания.
Введите формулу в ячейку F2 – она автоматически заполнит весь столбец вниз на пять строк:
=BYROW(B2:D6; LAMBDA(строка; СУММ(строка)))
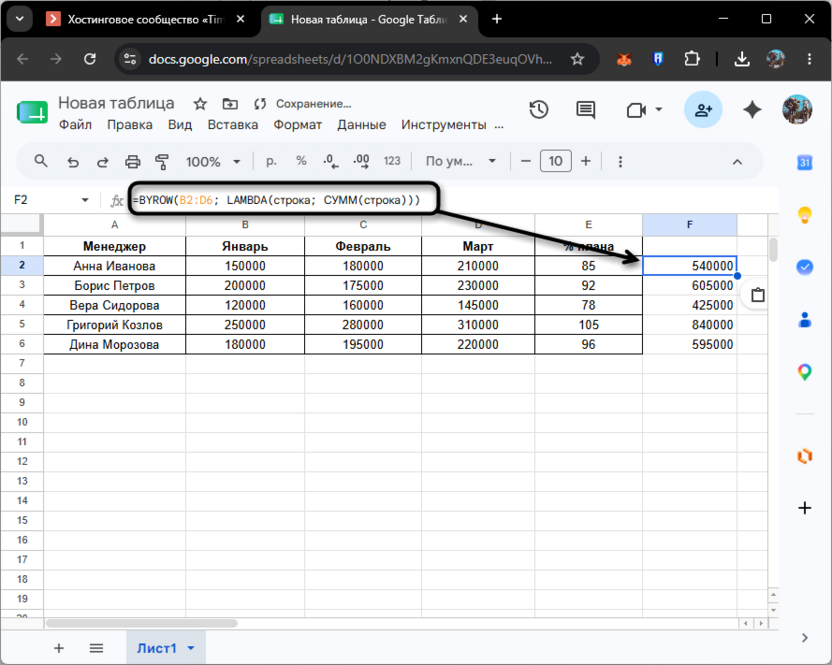
BYROW пройдет по каждой из пяти строк диапазона B2:D6 и применит СУММ к каждой. Формула занимает одну ячейку, а результат расширяется вниз ровно на столько строк, сколько было в исходном диапазоне. Заменив СУММ на МАКС, можно так же быстро найти лучший месяц по каждому менеджеру.
Пример 3: Функция BYCOL
BYCOL работает симметрично BYROW, только в другом направлении: она применяет формулу к каждому столбцу диапазона и возвращает одну строку результатов. Параметр внутри LAMBDA – это весь столбец диапазона как одномерный массив.
Синтаксис функции:
=BYCOL(массив; LAMBDA(столбец; формула))
Разница между BYROW и BYCOL сводится к направлению обхода: первая идет по строкам и возвращает столбец, вторая идет по столбцам и возвращает строку. Если нужно получить итоговую строку в нижней части таблицы, BYCOL – правильный выбор.
Одна из типичных задач – итоговая строка под данными. Допустим, нужно посмотреть, как в среднем продавала команда в каждый из трех месяцев, и добавить эти значения прямо под таблицей.
Введите формулу в ячейку B7 – она автоматически займет три соседних ячейки по горизонтали:
=BYCOL(B2:D6; LAMBDA(столбец; СРЗНАЧ(столбец)))
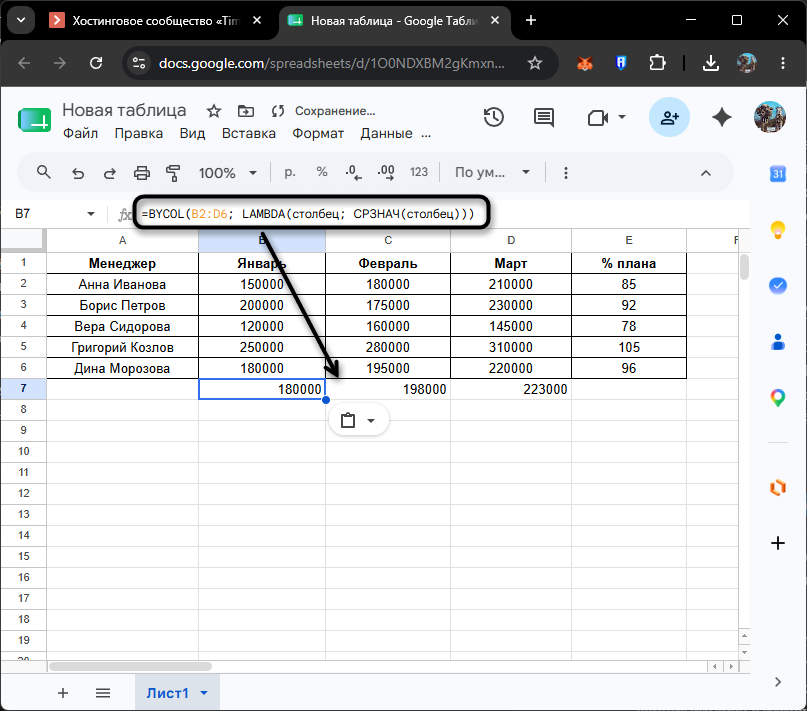
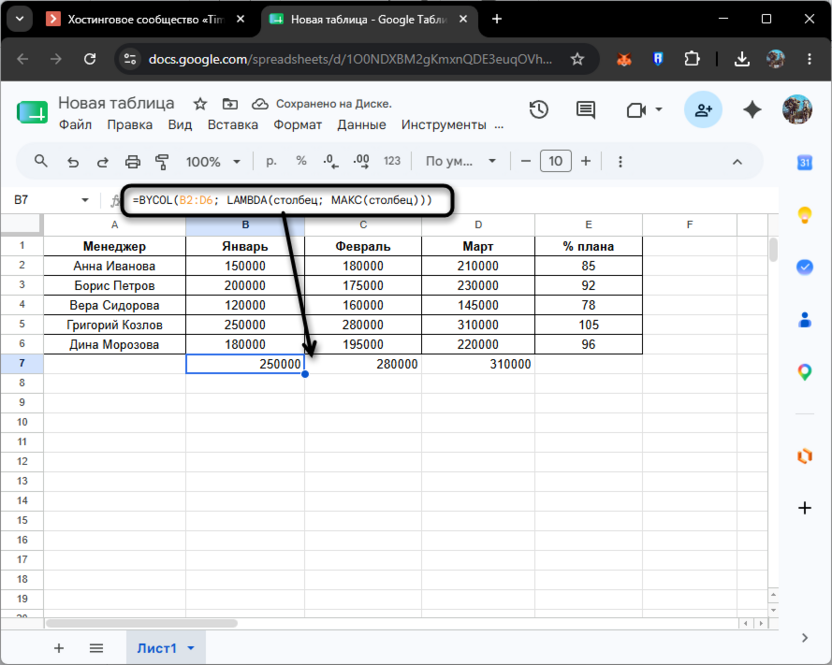
В ячейках B7, C7 и D7 появятся средние значения за январь, февраль и март соответственно. Заменив СРЗНАЧ на МАКС, получите рекорд по каждому месяцу: конкретно в рассматриваемом примере в январе лидирует Григорий Козлов с 250 000, в феврале – с 280 000, в марте – с 310 000.
Пример 4: Функция SCAN
SCAN отличается от трех предыдущих: она не просто применяет формулу к каждому элементу независимо, а накапливает результат по мере обхода массива. На каждом шаге доступно и текущее значение, и то, что накопилось до этого момента. Именно это делает SCAN незаменимой для расчетов нарастающим итогом.
Синтаксис функции:
=SCAN(начальное_значение; массив; LAMBDA(накоп; элемент; формула))
начальное_значение – с чего начинается накопление (обычно 0 для суммы). накоп – текущий накопленный результат, элемент – очередной элемент массива, который функция обрабатывает на этом шаге.
Предположим, руководителю важно видеть не только итог по команде, но и то, как складывается общий объем продаж по мере добавления каждого менеджера в список. Именно для таких расчетов нарастающим итогом SCAN подходит лучше всего – каждая строка результата учитывает все предыдущие.
=SCAN(0; B2:B6; LAMBDA(накоп; x; накоп+x))
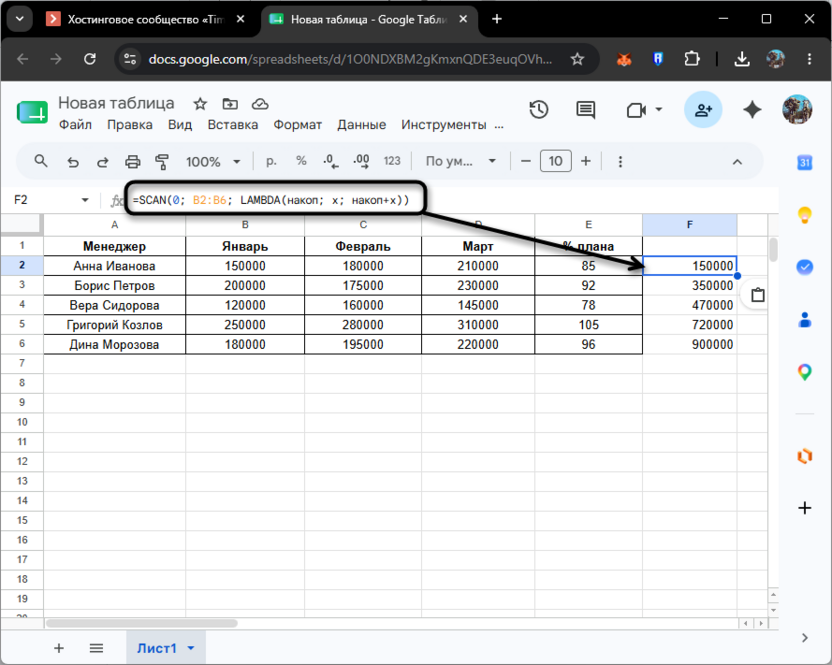
Результат появится в пяти ячейках: первая покажет Каждое следующее значение включает в себя все предыдущие. Начальное значение 0 означает, что накопление начинается с нуля, поэтому первый элемент сразу становится первым результатом.
Заключение
Все четыре функции – MAP, BYROW, BYCOL и SCAN – работают по одному принципу: вы описываете, что нужно сделать с одним элементом, строкой или столбцом, а Google Таблицы самостоятельно применяют это ко всему диапазону. Это делает формулы короче, логику прозрачнее, а таблицы – проще для понимания другими людьми. Большинство задач, которые раньше требовали ARRAYFORMULA, вспомогательных столбцов или Apps Script, теперь решаются в одну строку.





Комментарии