




Проводим небольшую уборку в коде нашего SvelteKit-блога. Рефакторинг в его базовом проявлении и наглядное пособие по тому, зачем вообще нужно пересматривать код, время от времени чистить его, а также делить на части.
Предыдущая статья: Блог на Svelte. Часть 10: Комментарии
Начало цикла: Блог на Svelte. Часть 1: Окружение
Что такое рефакторинг?
Рефакторинг – это процесс изменения кода, позволяющий без изменения функциональности приложения упростить его читаемость и сделать более податливым для модификации. Рефакторинг помогает большие, неаккуратные и неповоротливые приложения превратить в более гибкие, удобные и быстро развивающиеся.
Это помогает не только создателю ПО, но и всем тем, кто будет заниматься его доработкой в будущем. Хорошо оформленный код – это благо для всех.
Используются различные методики и концепции, выработанные программистами, чтобы упростить программный код и из хаоса сделать порядок. Мы не будем сильно углубляться в эту тему, так как ранее в Комьюнити выходила статья на эту тему, да и рефакторинг в нашем случае будет весьма базовым. Без четкой стратегии.
Зачем нам рефакторить код?
Затем, что он «грязный» и намеренно написан не особо аккуратно. Многое делалось на скорую руку, чтобы продемонстрировать различные возможности SvelteKit и Supabase, а также показать, как на практике могут быть реализованы привычные функции.
Но многие вещи можно сделать красивее и логичнее. В реальности вам придется заниматься подобным довольно часто, поэтому я решил наглядно продемонстрировать абстрактный процесс рефакторинга и те результаты, что он дает. Удалось удалить внушительный кусок кода – несколько сотен строчек точно исчезло из и без того компактного сайта.
Где-то мы будем использовать новые функции SvelteKit, где-то мы просто сократим количество кода, а некоторых местах просто изменим принцип оформления функций.
Приступаем к рефакторингу
Мы будем идти по порядку. Пройдемся по всем файлам проекта и в каждом из них сделаем пару-тройку изменений, позволяющих взглянуть на код без проступания холодного пота.
index.svelte
Начнем с заглавной страницы. Здесь не очень много кода, да и в целом все принципы рефакторинга, что мы будем использовать, будут понятны после работы уже с этой страницей. Как я уже говорил выше, одна из ключевых вещей для упрощения и упорядочивания кода в нашем случае – вывод функций и большого количество логики в отдельные файлы.
С этого и начнем. Уже на главной странице спрячем часть логики в сторонние файлы.
Вот простейший пример – функция getData, в которой прописана распространенная логика. Мы берем все статьи из базы данных. Но эта функция выглядит громоздко и не очень удобна. Мы можем ее сократить и часть кода вообще убрать из index.svelte.
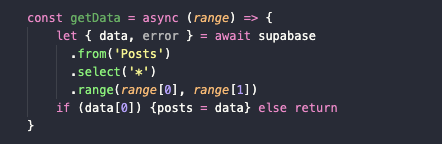
Мы создадим файл data.js в директории /api. Там будут храниться функции, связанные с получением различной информации из базы данных (а иногда и связанные с загрузкой данных в БД).
Вот какой код там будет в начале:
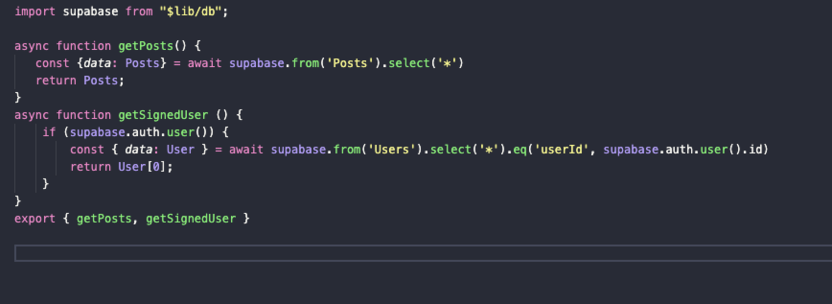
Описание функции getPosts:
-
Мы делаем асинхронный запрос к базе данных Supabase.
const {data: Posts} = await supabase.from('Posts').select('*') -
А потом возвращаем результат работы функции return Posts.
Изначально все выглядит привычно. Такой же запрос, как и раньше, но появился возврат данных. Он нам нужен, так как функцию мы будем запускать из внешних компонентов, и просто так вытащить информацию из БД уже не получится.
Описание функции getSignedUser:
-
Мы проверяем, залогинен ли пользователь: if (supabase.auth.user()) { }
-
В теле проверки прописываем запрос к базе данных, а конкретно к таблице Users.
const { data: User } = await supabase.from('Users').select('*').eq('userId', supabase.auth.user().id) -
И возвращаем полученную информацию с помощью return User.
Эта функция нужна для сопоставления данных о вас с информацией в таблице Users, где есть nickname, который часто используется в других компонентах приложения.
В конце файла мы экспортируем обе функции во внешнюю среду:
export { getPosts, getSignedUser }
Теперь их можно использовать в других компонентах, экспортировав, как и любую другую функцию. Проделаем это в компоненте index.svelte. Скопируем туда сразу обе функции:
import { getPosts, getSignedUser } from './api/data'
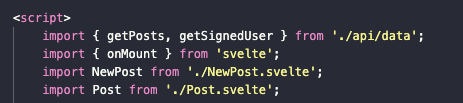
Далее мы используем обе функции, чтобы объявить в нашем приложении пользователя (его имя для приветствия на главной странице вместе со ссылкой на профиль) и полный список постов, как было на самых ранних этапах разработки.
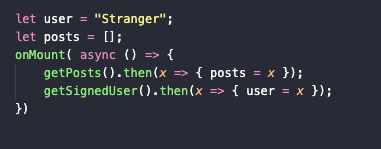
-
Создаем функцию onMount таким образом: onMount(( ) => { })
-
В теле onMount обращаемся к нашему методу getPosts. Тут важный момент заключается в том, что функция getPosts – асинхронная. То есть return из нее всегда будет возвращать обещание вернуть данные, а чтобы возвращались сами данные, нужно во внешней среде использовать синтаксис для асинхронных функций. Отсюда и слово then, обозначающее, что после выполнения getPosts надо выполнить еще какую-то работу:
getPosts().then(x => { posts = x }) -
То же повторяем с getSignedUser:
getSignedUser().then(x => { user = x })
Готово. Нам удалось удалить внушительный кусок кода и сделать важные функции базового компонента приложения понятнее. К тому же такой код гораздо легче переиспользовать, обращаясь к полученным из Supabase данным.
При желании логику этой функции можно сделать еще проще. Перепишем ее так, чтобы можно было самому выбирать, какую таблицу мы будем обрабатывать.

-
Заменим название функции на get.
-
Добавим аргумент typeOfData, отвечающий за тип информации в поле from:
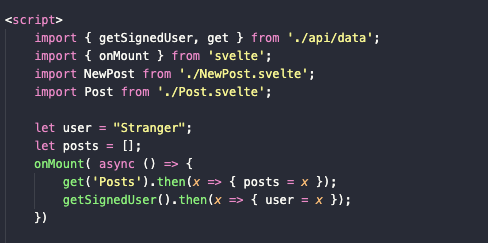
Затем переносим этот код в index.svelte. Теперь здесь будет не getPosts, а get('Posts') для постов (или get('Users') для пользователей).
NewPost
Новую универсальную функцию для запроса в Supabase можно применить уже в следующем компоненте. В NewPost она позволит быстро добывать теги и добавлять их в соответствующую переменную. Вот как мы добавим ее в функцию toggleInput (бывшая toggleInputVisibility):

-
Мы заменили стандартный запрос к базе на функцию get:
get('Tags').then(x => { tags = x }) -
А еще вы могли заметить, что мы убрали отсюда просто гору кода и ту же логику заменили аккуратной записью:
inputShown = ! inputShown
Получилась компактная и аккуратная функция, делающая все то же, что и раньше.
Еще один сложный момент с точки зрения кода – загрузка изображений. У нас просто катастрофически большие методы для выгрузки картинок в базу и их подключения к отдельным элементам в интерфейсе приложения. Абсолютно все, что связано с загрузкой картинок, можно упростить.
Мы поступим следующим образом:
-
Выведем во внешнюю среду функцию загрузки изображений в БД.
-
Заставим ее там же разыскивать publicURL только что выгруженной картинки и возвращать как результат работы метода.
Так мы сэкономим время и много строчек кода. Вот как может быть устроена такая функция:
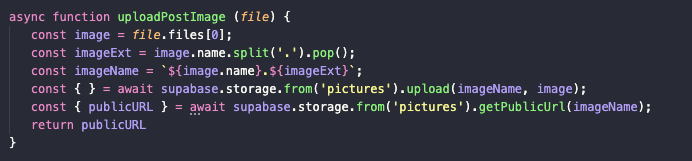
-
Создаем в файле data.js асинхронную функцию uploadPostImage:
async function uploadPostImage (file) { } -
В ее теле создаем объект image (это будет картинка из элемента, загруженного в качестве аргумента):
const image = file.files[0]
-
Потом генерируем расширение файла:
const imageExt = image.name.split('.').pop() -
Следом формируем имя картинки:
const imageName = `${image.name}.${imageExt}` -
Делаем запрос к Supabase, чтобы выгрузить туда новый файл:
const { } = await supabase.storage.from('pictures').upload(imageName, image) -
Сразу ищем публичную ссылку на картинку:
const { publicURL } = await supabase.storage.from('pictures').getPublicUrl(imageName) -
И возвращаем получившееся значение:
return publicURL
Теперь мы можем использовать этот метод внутри других функций во внешних компонентах. Например, ниже мы создали addPicture, чтобы внутри нее активировать uploadPostImage и получившееся значение присвоить переменной uploadedImage (в ней будет храниться ссылка на картинку, которую мы только что загрузили).
uploadPostImage(file).then(x => { uploadImage = x })
Также обратите внимание на то, что в uploadPostImage в качестве аргумента передается ветвь file. Это input с типом file для загрузки картинок.

Следующий этап – зачистка кода внутри метода addPost. Он у нас был слишком громоздкий, хотя из него можно вытащить большую часть строк без каких-либо потерь. Проанализируем то, что осталось:
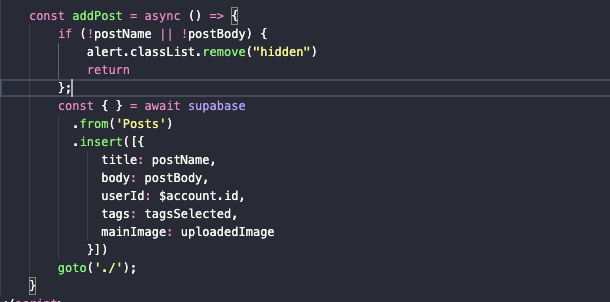
А осталась только проверка на наличие текста в полях postName и postBody и запрос к базе с просьбой добавить туда новую статью. В этом запросе мы заменили значение mainImage на uploadedImage, чтобы к статье сразу прикреплялась ссылка на картинку, а не ее название (да, это поможет избавить от жуткого алгоритма поиска изображений в Supabase, который мы реализовали в одном из прошлых уроков). А момент с обновлением контента я заменил на простую функцию goto('./'). Она перезагрузит роут и покажет актуальные данные после создания нового поста.
Post
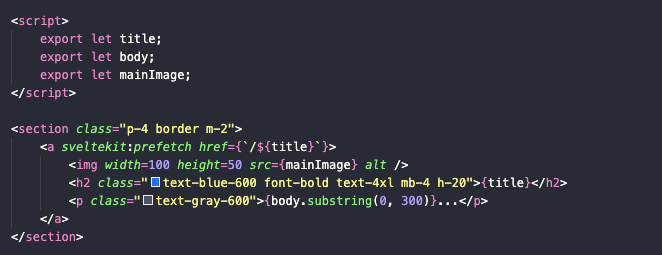
Изменение поведения функции загрузки картинки поможет избежать загрузки дополнительного контента при генерации каждого поста. Мы просто будем вставлять ссылку на картинку, которая хранится в mainImage.
<img width=100 height=50 src={mainImage} alt />
login
Еще один способ упросить код – чаще использовать фишки Svelte. Мы, конечно, далеко не все из них знаем и используем, но вот одна из тех, что может пригодиться уже сейчас. svelte:component – это универсальный компонент, который может отображать различный контент в зависимости от значения внешних переменных.
-
Конкретно в нашем интерфейсе мы изменим большую часть логики. Поместим два компонента signIn и signUp в отдельный объект:
let loginMenus = { signIn: SignIn, signUp: SignUp } -
Также создадим переменную, отвечающую за конкретный тип логин-страницы (по умолчанию ее значение будет равно компоненту SignIn в объекте loginMenus).
let loginMenu = loginMenus.signIn
-
Добавляем логику переключения, добавив кнопкам функцию для смены значения logicMenu.
-
Ну и в конце добавляем svelte:component, привязанный к loginMenu:
<svelte:component this={loginMenu} />
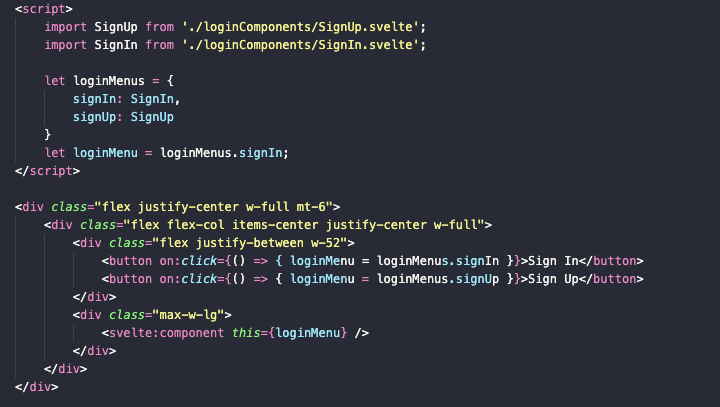
Теперь у нас всего лишь одна строка отвечает за рендеринг нужного компонента, а раньше была гора проверок на соответствие переменных нужным значениям.
signIn/signUp
Одна из важных вещей, которую нужно понимать – с рефакторингом не стоит перебарщивать. В некоторых случаях не стоит что-то упрощать и выводить во внешние компоненты. Например, в случае с блоками, отвечающими за регистрацию и вход, нет никакого смысла выносить их за пределы SignUp.svelte или SignIn.svelte. Там не так много кода. Надо его лишь немного причесать, убрав лишние строки, а некоторые и вовсе просто выровняв. Эти компоненты и так получились достаточно компактными и в целом понятными.
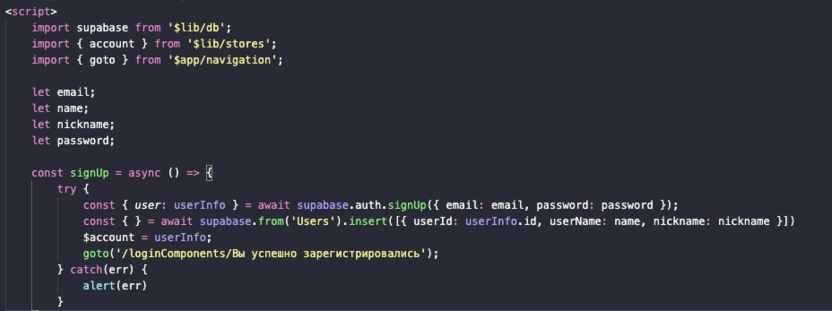
Можно было бы изменить подход к сохранению пользовательских данных, но пока нас устраивает то, что есть.
Что стоило бы сделать – сохранять в хранилище полный список данных пользователя, включая почту и никнейм, чтобы было проще обращаться к ним из других компонентов, но это необязательная опция, и мне она не кажется такой уж важной на данном этапе.
authors
Запросы к базе данных, которые мы прописали в файле data, можно поделить на части.
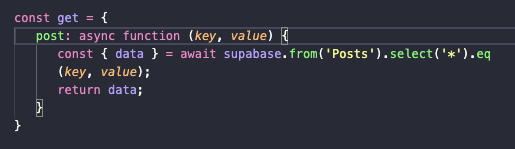
Один из методов «упаковки» функций – помещение их в объекты. Таким образом, они начинают напоминать классы и их методы, но в более простом облике. Чтобы вы лучше понимали, что я имею в виду, сделаем функцию get, которая берет не все данные, а конкретный тип данных и на конкретных условиях, описанных внутри объекта.
-
Сначала создаем объект get.
-
В его теле создаем ключ post:
post:
-
А значением этого ключа делаем асинхронную функцию со своими ключом и значением:
async function (key, value) { } -
В теле этой функции мы делаем запрос к базе на поиск постов, соответствующих нашим критериям (критерии мы передаем через аргументы key и value):
const { data } = await supabase.from('Posts').select('*').eq(key, value); -
И потом возвращаем полученные данные.
Теперь мы можем использовать эту функцию в компоненте authorFilter, чтобы добывать нужную информацию из Supabase. Поместим в onMount новый метод:
get.post('userId', id).then(x => { posts = x })
Получилось компактнее и логичнее, чем было прежде. Такие функции проще переиспользовать.
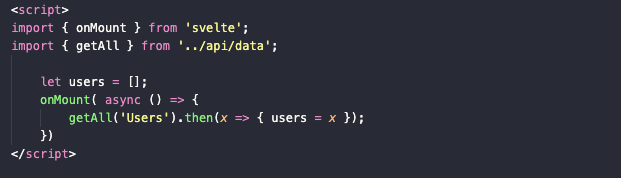
tags
Сейчас у нас нет отдельной странички с тегами, но я ее создал. Она полностью копирует такую для авторов и с помощью функции getAll собирает в себе все существующие теги из соответствующей таблицы. И в таком же интерфейсе эти теги отображаются на странице.

Что интересно, мы можем переделать непосредственно страницу-фильтр, упростив код и сократив его количество. Для этого нам понадобится еще один метод в объекте get. На этот раз создадим опцию не для поиска конкретных материалов, а для поиска постов, содержащих один или несколько искомых тегов.
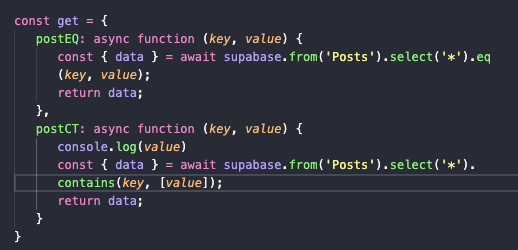
-
Добавляем в объект get метод postCT.
-
В качестве значения для этого метода указываем асинхронную функцию со своим ключом и значением:
async function (key, value) { } -
Внутри вписываем обращение к базе данных. Только на этот раз выбираем не конкретный объект, а целый массив:
const { data } = await supabase.from('Posts').select('*').contains(key, [value]) -
А потом возвращаем полученное значение.
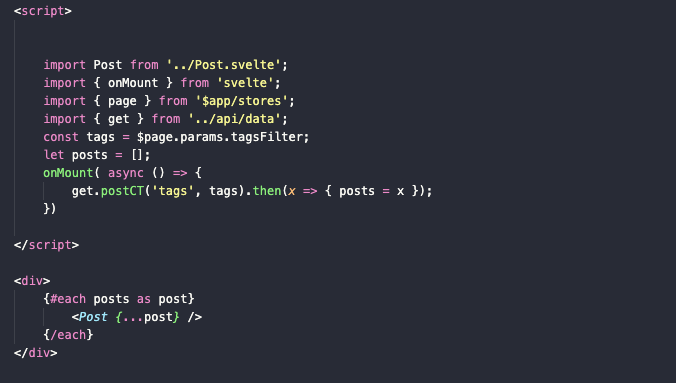
Теперь этот метод можно задействовать в [tagsFilter].svelte:
get.postCT('tags', tags).then(x => { posts = x});
profile
В профиле не нужно что-то менять. Лишь уложим основную логику добычи данных в один onMount-блок.

-
Сначала вызовем функцию getSignedUser, чтобы получить информацию о текущем пользователе (о нас самих), а затем переназначим переменные:
getSignedUser().then( x => { } ) -
Берем полученную переменную x и ее параметры присваиваем к description, nickname и imageSource.
-
Здесь же делаем второй запрос к базе, чтобы получить посты пользователя и отобразить их ниже.
Еще из больших изменений тут стоит отметить измененный принцип загрузки изображений (аватарок). Мы используем метод uploadUserImage, полностью копирующий uploadPostImage. Отличается только внутренняя функция, присваивающая новое значение не переменной в каком-либо из постов, а переменной в списке атрибутов пользователя.
uploadUserImage(file).then(async (x) => { const { } = await supabase.from('Users').update({profilePicture: x}).eq('userId', user.userId) })

По завершении работы этой функции нужно сделать переадресацию на ту же страницу, чтобы обновить информацию в интерфейсе.
articles
Добрались до нашего [slug].svelte. Здесь нужно поработать основательно – у нас там лютая каша, которую очень трудно читать.
Поэтому первое, что мы сделаем – перенесем большую часть информации в отдельные файлы. Вот так должна выглядеть примерная структура новой папки articles:
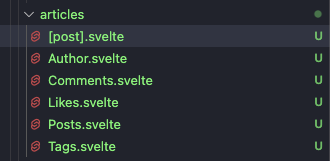
Я не буду описывать логику каждого компонента, но на примере тегов и лайков поясню основной принцип деления интерфейса на отдельные компоненты. Вы, естественно, можете выбрать свой стиль и поделить код на еще более мелкие куски.
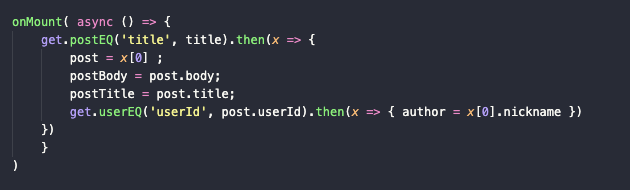
Из логики в компоненте [post].svelte (да, можно выбрать более лаконичное название) остались только запросы к базе с поиском поста и его автора.
-
Создаем блок onMount.
-
В тело закидываем метод get.postEQ, чтобы достать основную информацию об открытом посте:
get.postEQ('title', title).then(x => { post = x[0]; postBody = post.body; postTitle = post.title } -
Туда же стоит добавить поиск автора открытой статьи:
get.userEQ('userId', post.userId).then(x => { author = x[0].nickname })
А вот как в интерфейсе должны выглядеть отдельные компоненты этой части приложения:
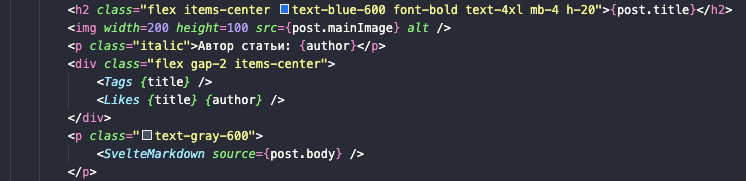
Tags
В тегах просто делаем запрос к базе и обновляем переменную tags. Фактически мы скопировали уже существующий код и перенесли его в отдельный файл, параллельно сменив стандартный запрос к БД на наш новый метод из data.js.
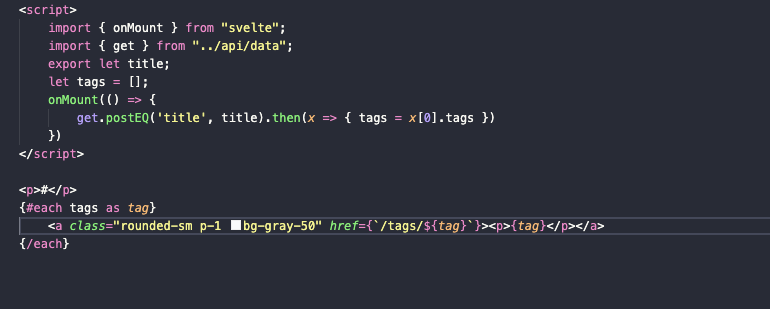
Likes
С лайками аналогичная ситуация. Разница только в том, что у нас здесь есть отдельный метод для обновления информации в базе данных (о количестве лайков), но он вообще никак не изменился, а запрос к количеству лайков теперь делается так:
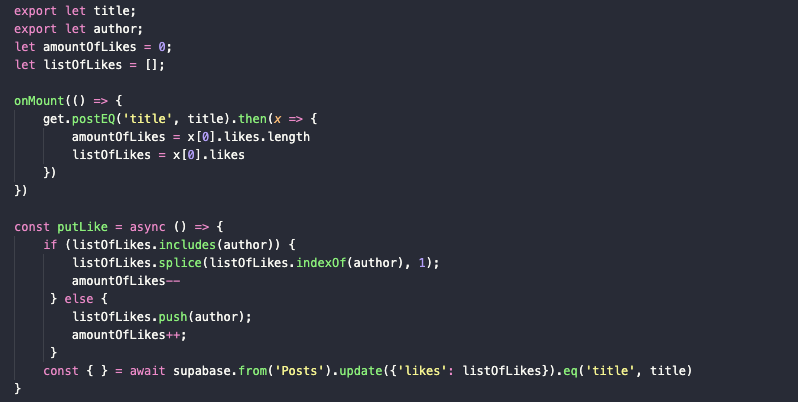
-
Прописываем метод get.postEQ:
get.postEQ('title', title).then(x => { amountOfLikes = x[0].likes.length; listOfLikes = x[0].likes }
Comments
Похожая ситуация в комментариях – заменяем стандартные запросы к базе на методы из data.js исключительно с целью сократить количество символов в файле, чтобы компонент легче читался и его было проще модифицировать, если нам понадобится расширить функциональность блока с комментариями.
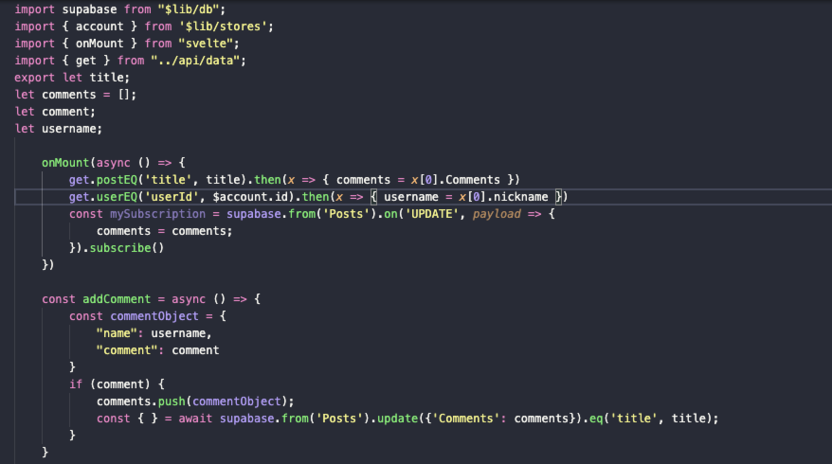
Вместо заключения
В теории ваше приложение может разрастись еще сильнее, секция комментариев может стать намного крупнее. Представьте, что появятся методы для удаления комментариев, аватарки пользователей, вложенность и возможность отвечать конкретным людям. Получится, что компонент снова сильно увеличится в размерах и станет нечитаемым. В этот момент нужно будет снова делить программу на части и упрощать.
Это я к тому, что рефакторинг – бесконечный процесс, который нужно запомнить как концепцию. И не стоит воспринимать эту статью как четкую инструкцию. Думайте шире и используйте идеи из материала для упрощения своего ПО.
На этом все! И не забывайте про коммиты.





Комментарии