



![Нейросети для транскрибации аудио и видео в текст: 10 лучших сервисов [Подборка]](/ru/community/article/fb/fbd027130074c0218430c0e4e0ee5ab3.jpg)
Нейросети для транскрибации аудио и видео в текст – это не просто тренд, а реальный инструмент, который экономит время и упрощает работу. Они способны быстро преобразовать речь в текст с высокой точностью, даже если в записи есть шумы или акценты.
Такие технологии используют журналисты, блогеры, юристы, маркетологи и представители других профессий, где важна работа с информацией. Современные нейросети учатся на ходу, адаптируясь к новым задачам и языкам.
В этой статье мы рассмотрим лучшие нейросети для транскрибации аудио и видео в текст. Отдельно поговорим о том, кому нужны подобные инструменты, какие задачи они решают и как расшифровывают речь.
ТОП-6: Лучшие нейросети для транскрибации аудио и видео в текст
В основном списке – 6 лучших ИИ, которые помогут быстро и эффективно перевести речь в аудио или видео в текстовый формат. Все платформы поддерживают русский язык.
«Транскрипт» от GPTunneL
«Транскрипт» – это инструмент, который доступен на платформе GPTunneL. Он быстро и эффективно обрабатывает аудио и видео файлы – извлекает транскрипцию речи с возможностью диаризации говорящих.
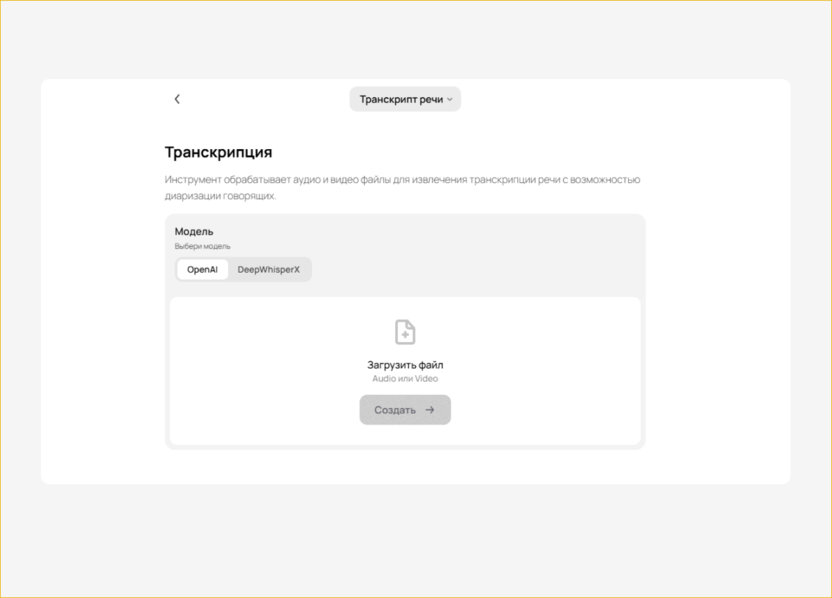
Стоимость: оплата за токены; цена зависит от выбранной нейросети
Как использовать сервис:
- Зайдите на платформу GPTunneL. Обязательно зарегистрируйтесь на платформе или войдите в личный кабинет через Яндекс, VK, Google, Telegram. Без регистрации сервис не сможет начать расшифровку аудио/видео в текст.
- Инструмент транскрибации доступен в разделе «Инструменты AI» → «Транскрипт».
- Выберите модель. Доступны две модели: OpenAI (установлена по умолчанию) и DeepWhisperX. При выборе второй модели также укажите язык распознавания либо оставьте функцию автоматического определения языка.
- Загрузите файл. Это может быть аудио или видео, где вы хотите распознать текст.
- Нажмите кнопку «Создать», чтобы начать работу.
Еще GPTunneL открывает доступ к популярным нейросетям – они все работают в России:
- Suno. Нейросеть для создания музыки с помощью искусственного интеллекта.
- ChatGPT. Самая продвинутая и мощная нейросеть от OpenAI с поддержкой зрения и анализа изображений.
- Claude Sonnet. Новейшая модель для создания качественных текстов.
В личном кабинете вы найдете различных ассистентов, которые решают разные задачи: написание рефератов, создание логотипов и презентаций, написание кода и программирование.
***
Any to Text
Any to Text – это онлайн-преобразователь аудио и видео в текст на базе искусственного интеллекта. Процесс транскрибации выполняется за считанные секунды; максимальная длина аудио или видео для преобразования не ограничена: поэтому вы можете загрузить двухчасовой подкаст и получить текстовую расшифровку материала.
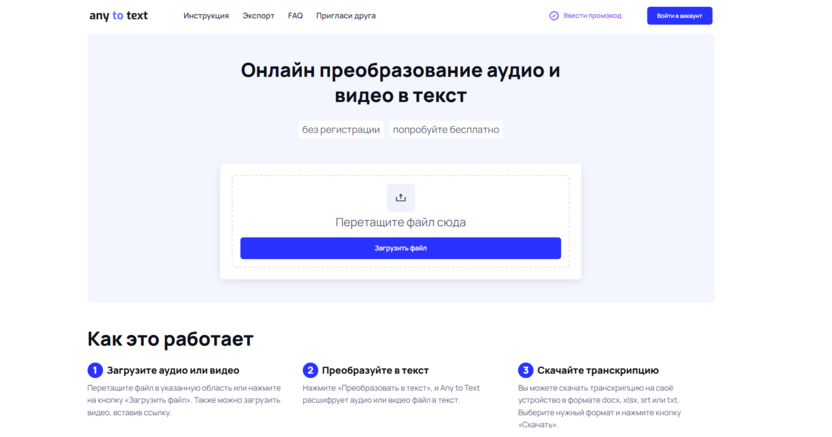
Как это работает:
-
Зайдите на официальный сайт нейросети и загрузите аудио или видео. Можете просто перетащить нужный файл в специальную область или нажмите кнопку «Загрузить файл». Еще можно указать ссылку на видео.
-
Преобразуйте в текст. Для этого нажмите кнопку «Преобразовать в текст» – ИИ расшифрует аудио или видео.
-
Скачайте транскрипцию. Полученный результат – расшифрованное аудио или видео – можно скачать в текстовом формате: docx, txt, xlsx, srt.
Платформа поддерживает разные форматы аудио и видео (более 100 форматов): MP4, M4A, MP3, WMV, FLAC, WMA, OGG, MOV, AVI, AAC, FLV. Еще искусственный интеллект автоматически определяет язык речи – он поддерживает более 50 языков, включая русский, английский, итальянский, турецкий, немецкий.
***
Писец
Писец – нейросеть, которая переводит любые аудио- и видеофайлы в текст. Платформа разделит текст на спикеров, расставит таймкоды и знаки препинания.
Особенности онлайн-сервиса:
- Поддержка всех популярных форматов аудио и видео. Вы можете загрузить файлы разных форматов: FLV, WMA, MP4, OGG, AAC, AVI, MOV, WMV, MKV, MP3, M4A, FLAC. Главное, чтобы в файле был звук.
- Работа с разными языками. Писец умеет делать транскрибацию как на русском, так и на английском языке.
- Без ошибок. Частота ошибок в словах при транскрибации – 2%. Исходный текст получается грамотным: ИИ делит его на абзацы, ставит точки и запятые. Еще платформа умеет указывать спикеров: например, при диалоге двух людей в подкасте.
- Простота использования. Просто загрузите файл – аудио или видео, – укажите количество спикеров и введите электронную почту. На почту вам придет транскрибация в формате Word; также расшифровка будет доступна в личном кабинете – он создается автоматически.
- Высокая скорость работы. Транскрибация и расшифровка аудио или видео на один час займет не больше 10 минут.
***
Speech2Text
Speech2Text – удобный и функциональный сервис для быстрого и качественного распознавания речи. Расшифровка аудио и видео выполняется на базе искусственного интеллекта – со знаками препинания, абзацами и разделением на спикеров.
Особенности онлайн-сервиса:
- Высокое качество распознавания. Речь в аудио или видео распознается с невероятной точностью – даже при плохом звуке.
- Деление на спикеров. В расшифровке можно разделить речь спикеров – и даже переименовать их.
- Высокая скорость работы. Часовой подкаст, лекцию или видео можно расшифровать за 10 минут.
- Мультиязычность. Сервис может распознать аудио и видео на русском, английском, французском, испанском языках. Всего платформа поддерживает более 20 языков.
- Субтитры. Вы можете скачать субтитры и добавить их в свое видео на монтаже.
Также сервис позволяет расшифровывать записи с диктофона, даже если говорящего плохо слышно. Распознавание и транскрибация производится на базе нейросетей.
***
Teamlogs
Teamlogs – удобный сервис транскрибации аудио и видео в текст с высокой точностью. Алгоритм преобразования речи в текст поможет быстро расшифровать подкаст или лекцию, расставит знаки препинания, разделит на реплики участников.
Особенности сервиса:
- Удобный редактор. В личном кабинете можно прослушать материал, выделить важные моменты в расшифровке, подписать спикеров.
- Teamlogs AI. Искусственный интеллект для ваших расшифровок: отвечает на вопросы по расшифровке, делает выжимку фактов, упрощает работу с текстом.
- Экспорт. Полученный результат можно скачать в docs, xlsx, srt.
- Легко использовать. Загрузите файл → дождитесь окончания расшифровки → отредактируйте расшифровку прямо в браузере → скачайте результат.
Сервис поддерживает файлы разных форматов: MP3, MP4, M4A, OGG, WAV, FLAC, WMA, M4A, FLAC, AAC, WEBM.
***
Wonderscribe
Wonderscribe – это функциональная платформа для транскрибации аудио в режиме онлайн. Вы можете загрузить файлы любого размера и длины – у сервиса нет никаких ограничений.
Особенности платформы:
- Интерактивные редакторы, аналитика текста. Они анализируют текст и облегчают взаимодействие с файлом.
- Поддержка разных форматов. Транскрибируйте аудиофайлы любых форматов: MP4, MP3, M4A, FLAC, WAV, AAC, MPEGPS, AIFF, DSD.
- Удобный экспорт. Расшифровку можно скачать в pdf, docx, txt, xlsx.
- Поиск ключевых слов. Есть инструмент для автоматического поиска – он поможет найти и зафиксировать любые ключевые слова и словосочетания.
- Моно и стерео. Сервис автоматически определяет моно и стерео записей, разделяет на аудиодорожки.
***
Дополнительный список: еще 4 нейросети для перевода аудио и видео в текст
В дополнительном списке мы собрали еще 4 платформы, которые помогут перевести аудио или видео в текст. Также здесь вы найдете инструменты, которые можно использовать для расшифровки онлайн-встреч.
- RealSpeaker. Удобный и простой инструмент для транскрибации медиа. Можно перевести аудио и видео в текст. Есть поддержка разных языков: английский, русский, французский, испанский и другие. Максимальная длительность аудио- или видеофайла – около 180 минут.
- SaluteSpeech. Синтез и распознавание речи от Сбера. Есть удобное приложение для Windows и MacOS. Технология считывает не только слова, но и смысл написанного – и задает вопросы с органичной интонацией. Сервис понимает, какое поставить ударение. Нейросеть игнорирует разговоры других людей или бормотание телевизора.
- MyMeet. Искусственный интеллект для онлайн-встреч. Поможет расшифровать встречу, учтет спикеров, поделит транскрипт на умные главы.
- Otter.ai. Удобный помощник, который используется для расшифровки онлайн-встреч. Инструмент умеет разделять речь спикеров. Поддерживает только английский язык.
Как нейросети переводят аудио и видео в текстовый формат: основные особенности
Нейросети переводят аудио и видео в текстовый формат с помощью технологий автоматического распознавания речи – Automatic Speech Recognition, ASR.
Процесс транскрибации можно разделить на шесть этапов:
1. Предобработка данных:
- Извлечение аудио. Если исходный материал – видео, сначала извлекается аудиодорожка.
- Нормализация звука. Аудио очищается от шумов, нормализуется громкость и частота дискретизации.
2. Преобразование звука в спектрограмму. Аудиосигнал разбивается на небольшие временные отрезки (фреймы) и преобразуется в спектрограмму – визуальное представление звука, где по осям отложены время, частота и амплитуда.
3. Извлечение признаков. На этом этапе используются разные методы: MFCC (Mel-Frequency Cepstral Coefficients) или фильтры мел-шкалы, чтобы выделить ключевые акустические признаки, которые нейросеть сможет анализировать.
4. Распознавание речи с помощью нейросетей:
- Рекуррентные нейронные сети (RNN): например, LSTM (Long Short-Term Memory) или GRU (Gated Recurrent Units) используются для обработки последовательностей данных (аудиофреймов).
- Сверточные нейронные сети (CNN). Они применяются для анализа спектрограмм.
- Трансформеры. Современные модели ИИ используют архитектуру трансформеров для более точного распознавания речи.
5. Постобработка текста:
- Языковое моделирование. Нейросети используют языковые модели (например, GPT или BERT) для исправления ошибок и улучшения грамматики.
- Расстановка пунктуации. Добавляются знаки препинания: точки, запятые и так далее.
- Контекстная коррекция. Учитывается контекст для исправления омофонов (слов, которые звучат одинаково, но пишутся по-разному: например, «плод» и «плот»).
6. Вывод текста. Обработанный текст выводится в виде транскрипции, он может быть сохранен в файл или использован для дальнейшего анализа.
Кому может понадобиться транскрибация аудио и видео в текст
Транскрибация аудио и видео в текст – это полезный инструмент, который может быть востребован в самых разных сферах. Вот несколько примеров, кому может понадобиться перевод аудио и видео в текстовый формат:
- Журналисты. Для расшифровки интервью, пресс-конференций или записей встреч.
- Редакторы. Чтобы быстро создать текстовую версию аудио- или видеоматериалов.
- Подкастеры. Для создания текстовых расшифровок выпусков подкастов, что улучшает SEO и доступность контента.
- Студенты. Для конспектирования лекций или семинаров.
- Преподаватели. Чтобы создать текстовые материалы на основе записанных уроков или вебинаров.
- Предприниматели. Для документирования обсуждений и принятых решений.
- Юристы. Для расшифровки аудиозаписей переговоров или судебных заседаний, допросов или показаний свидетелей.
- HR-специалисты. Для анализа интервью с кандидатами или записи тренингов.
- Аналитики и маркетологи. Для обработки фокус-групп, интервью или опросов.
- Копирайтеры. Чтобы создать текстовый контент на основе аудио- или видеоматериалов.
Итоги
Нейросети для перевода аудио и видео в текст – это не просто удобный инструмент, а шаг в будущее, где рутинные задачи выполняются за считанные минуты. Они продолжают развиваться, становясь точнее и доступнее для каждого.
Уже сейчас такие технологии меняют подход к работе с аудио- и видеоконтентом, экономя время и ресурсы. Остается только выбрать подходящее решение и начать использовать его в своих проектах.
Изображение на обложке: Freepik





Комментарии