



Каждый, кто хотя бы однажды пользовался ChatGPT или аналогичными сервисами, рано или поздно задается вопросом: а можно ли сделать что-то подобное прямо на своем компьютере, не отправляя запросы на чужие серверы? Ответ однозначный: да, и сделать это стало гораздо проще, чем кажется. Запуск нейросети локально дает сразу несколько весомых преимуществ – полная конфиденциальность переписки, работа без интернета и отсутствие платных подписок с лимитами на количество запросов. Именно это сочетание привлекает все больше людей, которые хотят иметь собственного ИИ-ассистента под рукой в любой момент.
Ключевое понятие, с которым придется познакомиться в начале, – «оболочка». Это программа, которая берет на себя всю техническую часть: загрузку модели, управление памятью и создание интерфейса для общения. Без нее запуск нейросети потребовал бы установки Python, множества зависимостей и ручной работы в терминале. Актуальные оболочки решают эту проблему, позволяя начать работу с ИИ за несколько минут после скачивания установщика.
LM Studio
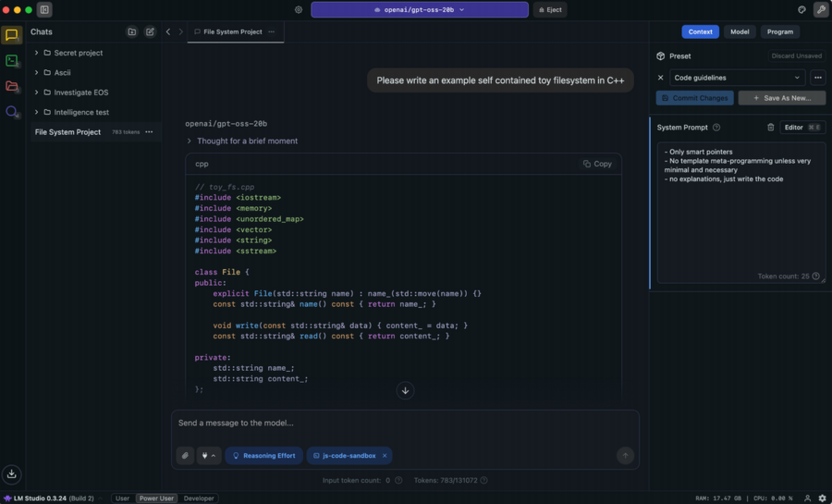
Наибольшую популярность среди оболочек для локальных нейросетей сегодня имеет LM Studio – и это неудивительно. Приложение предлагает отполированный графический интерфейс, встроенный каталог моделей с Hugging Face с фильтрами по размеру файла и требованиям к памяти, а также полноценный чат прямо внутри программы. При этом LM Studio умеет поднимать локальный API-сервер, совместимый с форматом OpenAI, что позволяет подключать нейросеть к другим приложениям или использовать ее как основу для собственных проектов.
Скачать установщик можно с официального сайта LM Studio, доступны версии для Windows, macOS и Linux. Перед установкой стоит убедиться, что на диске достаточно свободного места: даже компактные модели занимают от 4 до 8 ГБ, а более крупные – от 15 ГБ и выше.
-
Скачайте установщик с официального сайта и запустите его.
-
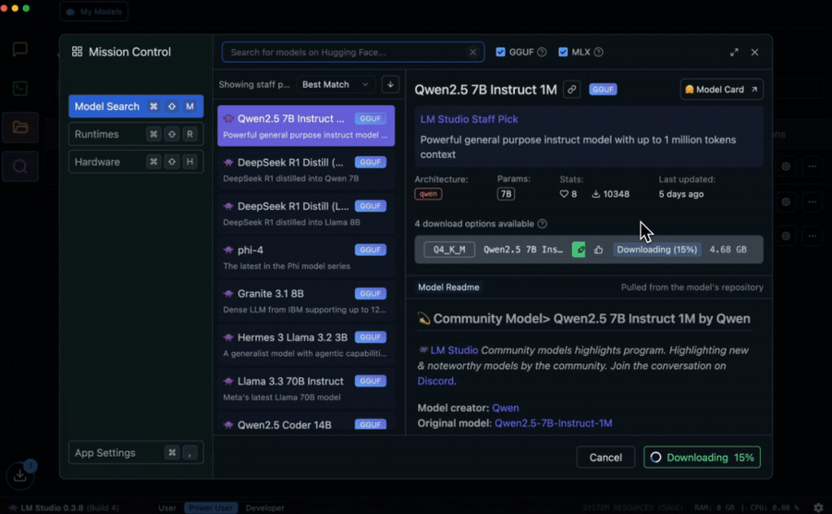
После первого запуска перейдите во вкладку поиска моделей и введите название нужной модели или отфильтруйте список по доступному объему памяти.
-
Нажмите кнопку загрузки напротив выбранной модели и дождитесь завершения скачивания.
-
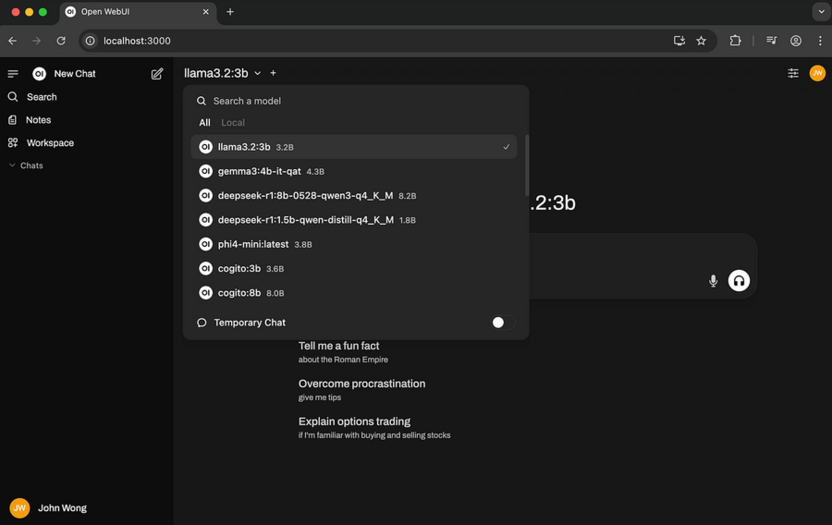
Перейдите в раздел чата, выберите загруженную модель в верхнем меню и начните общение.
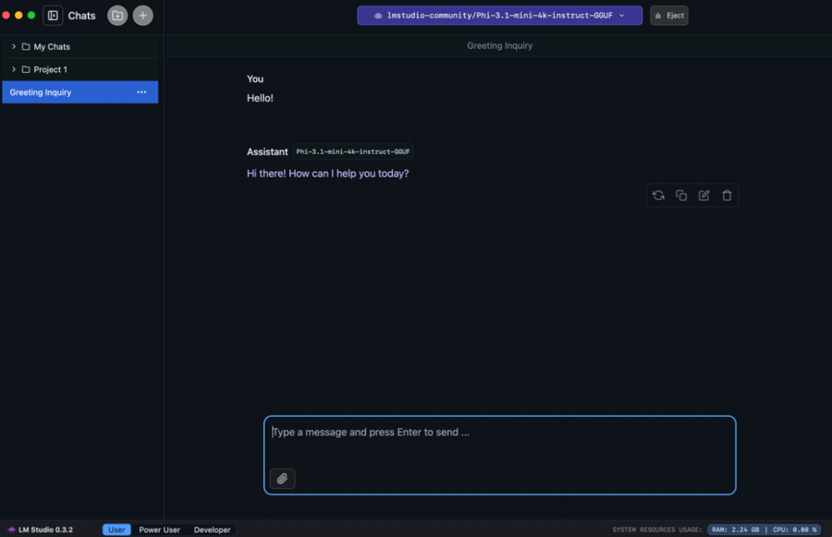
После запуска модели интерфейс напоминает привычный мессенджер: поле для ввода, история сообщений и возможность создавать отдельные беседы. Из популярных моделей хорошо зарекомендовали себя Qwen 3.5, Gemma 4 и дистиллированные версии DeepSeek – они показывают качественные результаты при разумных требованиях к железу. На боковой панели доступны дополнительные настройки: температура генерации, длина контекста и системный промпт, задающий поведение модели. API-сервер запускается одним переключателем в соответствующем разделе и после этого принимает запросы от внешних программ.
Закрытый исходный код – главный минус LM Studio. Вдобавок анонимная аналитика включена по умолчанию, и отключить ее можно вручную в разделе «Настройки» – «Privacy». Для большинства пользователей оба момента несущественны, однако тем, кому важна полная прозрачность, их стоит учитывать при выборе.
Ollama
Подход Ollama принципиально отличается от LM Studio: здесь нет полноценного графического интерфейса в привычном понимании, хотя начиная с версий 2025-2026 года у Ollama появился собственный базовый чат с возможностью прикреплять файлы и регулировать уровень «размышления» у поддерживаемых моделей. Основная мощь инструмента по-прежнему сосредоточена в терминале и API: именно этот формат подходит тем, кто хочет использовать нейросеть внутри своего проекта, подключить ее к редактору кода или встроить в чат-бота.
Ollama поддерживает видеокарты NVIDIA, AMD и Apple Silicon, причем на устройствах Apple с чипами серии M по умолчанию используется оптимизированный движок MLX, что дает заметный прирост скорости по сравнению с предыдущими версиями.
Установщик доступен на официальном сайте Ollama для всех основных операционных систем. После установки сервис автоматически запускается в фоне и готов принимать команды.
-
Скачайте установщик с официального сайта Ollama и запустите его.
-
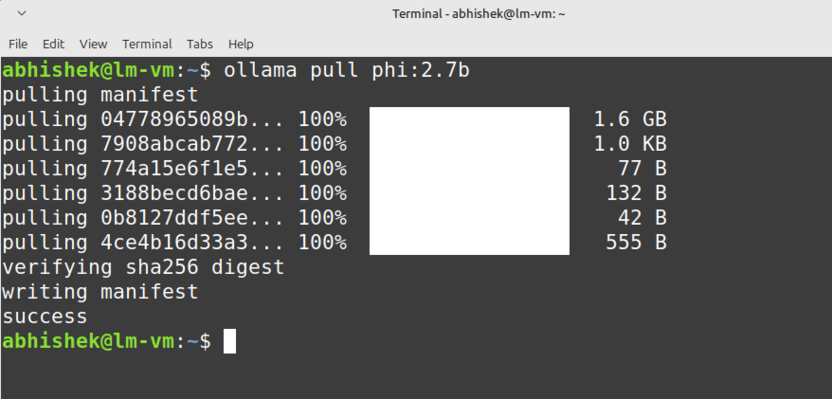
Откройте терминал и выполните команду ollama pull название_модели – например, ollama pull qwen3.5:9b – чтобы загрузить нужную модель.
-
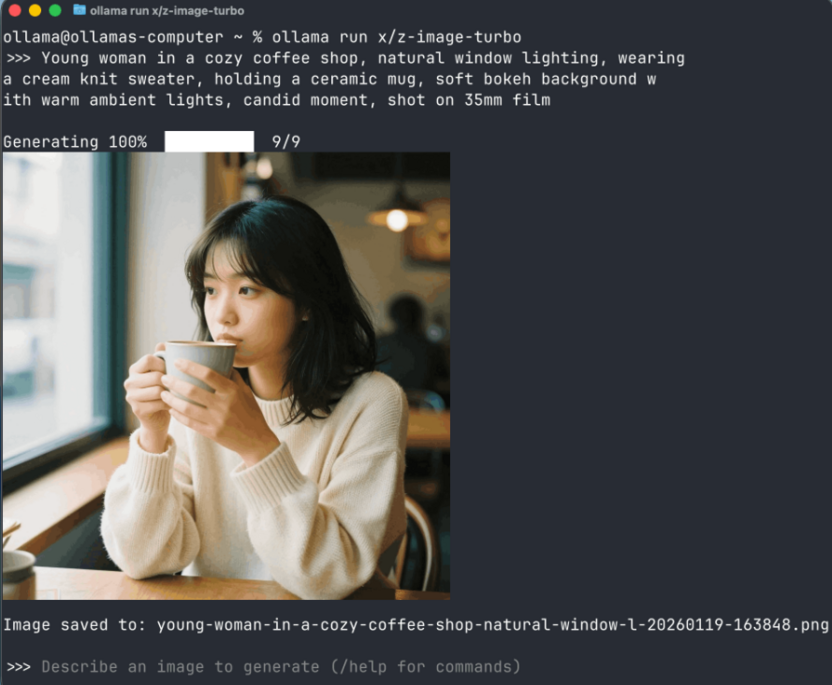
Для запуска чата прямо в терминале введите ollama run название_модели.
-
Если удобнее работать через браузер, установите Open WebUI – это отдельный проект, который подключается к Ollama и превращает его в полноценный аналог ChatGPT с привычным интерфейсом.
Библиотека поддерживаемых моделей у Ollama очень широкая: Qwen, Gemma, Mistral, DeepSeek и многие другие скачиваются одной командой. Модели хранятся во внутреннем формате Ollama и не читаются напрямую другими оболочками, поэтому при необходимости сменить инструмент модель придется скачать заново. API работает по умолчанию на порту 11434 и совместим с форматом OpenAI, что делает Ollama удобной основой для подключения к VS Code, Cursor и другим инструментам разработки.
Без стороннего фронтенда вроде Open WebUI работа через терминал может показаться непривычной тем, кто ожидал оконное приложение. Вместе с тем встроенного каталога с описаниями и карточками моделей здесь нет, поэтому стоит заранее изучить, какие именно модели подходят для нужных задач.
GPT4All
Если предыдущие инструменты предполагали хоть какую-то техническую подготовку, GPT4All построен по принципу «поставил и работаешь». Программа устанавливается как обычное приложение, после первого запуска сразу предлагает выбрать и скачать модель из встроенного каталога, а общение начинается в несколько кликов без каких-либо дополнительных действий. Отдельного внимания заслуживает встроенная функция LocalDocs: она позволяет подключить папку с документами и задавать по ним вопросы, не прибегая к ручной настройке RAG-систем, которая в других оболочках требует дополнительных усилий.
Скачать GPT4All можно с официального сайта проекта, доступны версии для Windows, macOS и Linux. Программа полностью открытая и не собирает данные по умолчанию.
-
Загрузите установщик с официального сайта GPT4All и выполните стандартную установку.
-
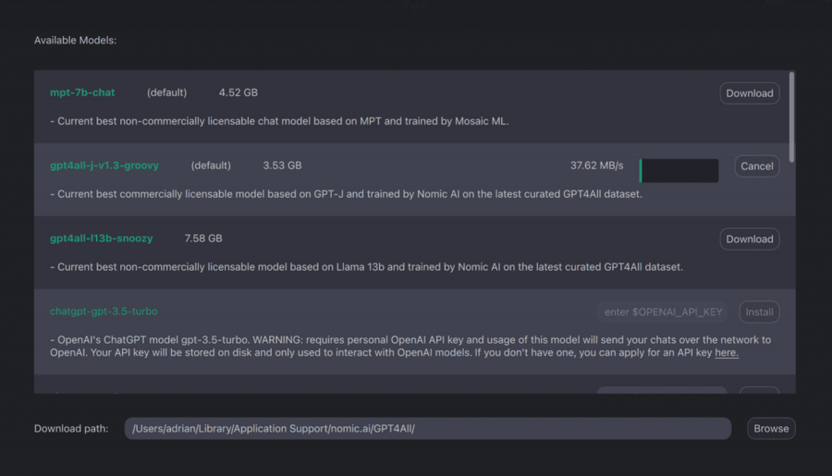
При первом запуске откроется каталог моделей с указанием размера файла, необходимого объема RAM и кратким описанием каждой из них.
-
Выберите подходящую модель и нажмите кнопку загрузки, после чего дождитесь завершения скачивания.
-
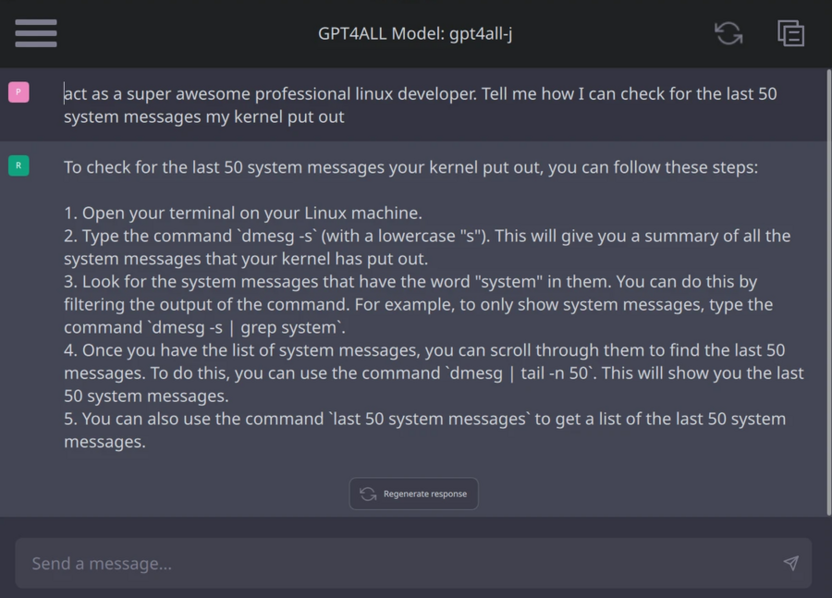
Перейдите в раздел чата, убедитесь, что нужная модель выбрана в верхней части окна, и начните диалог.
-
Для работы с документами откройте раздел LocalDocs, добавьте папку с нужными файлами и выберите ее в настройках текущего чата.
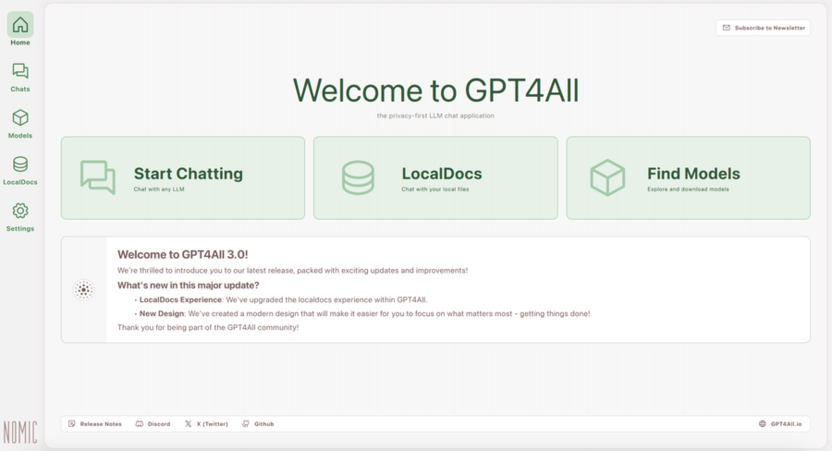
GPT4All уверенно работает даже на слабом железе, поскольку встроенный каталог изначально ориентирован на компактные и хорошо оптимизированные модели. Полностью открытый исходный код, отсутствие телеметрии и поддержка офлайн-режима делают его удобным вариантом для тех, кто ценит автономность. Из нюансов стоит учитывать, что по широте выбора моделей каталог уступает LM Studio, а работа с файлами в разделе LocalDocs иногда ведет себя непредсказуемо – не все форматы документов обрабатываются одинаково стабильно.
Jan
Jan создавался с акцентом на полную прозрачность и независимость, и это ощущается во всем. Исходный код проекта открыт под лицензией AGPLv3, телеметрия отсутствует полностью, а вся история общения хранится в локальных JSON-файлах на вашем компьютере в читаемом формате – ее можно открыть и проверить в любой момент. По функциональности Jan вполне сопоставим с LM Studio: тот же графический интерфейс, каталог моделей, встроенный чат и локальный API-сервер, поэтому переходить придется скорее по принципиальным соображениям, чем из-за нехватки возможностей.
Установщик Jan доступен на официальном сайте проекта для Windows, macOS и Linux.
-
Скачайте установщик с официального сайта Jan и установите программу.
-
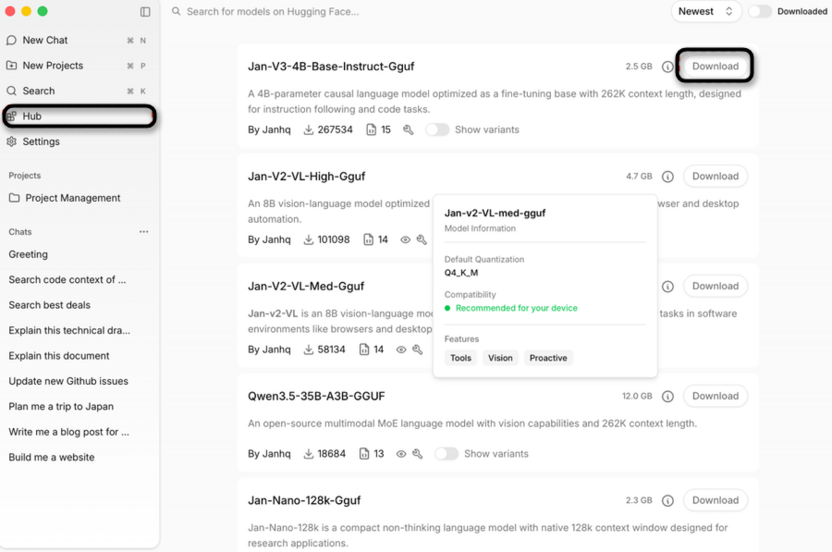
В разделе «Hub» найдите нужную модель через поиск или фильтры и нажмите кнопку загрузки.
-
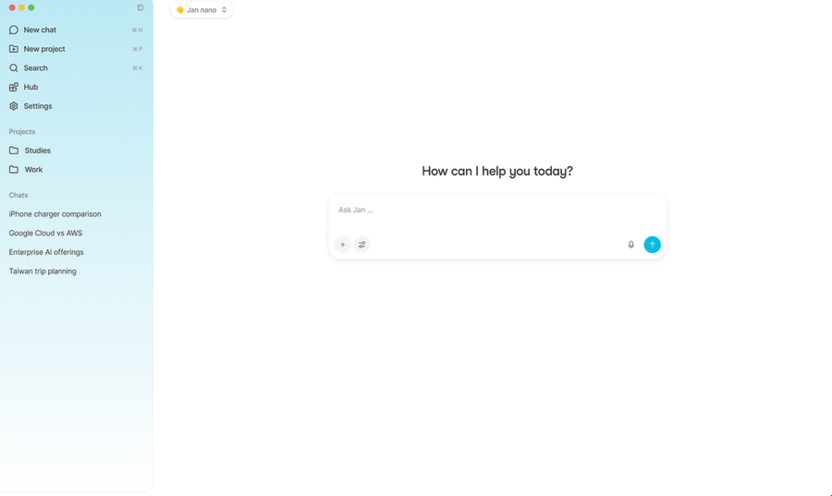
Перейдите в раздел «Thread», создайте новую беседу и выберите скачанную модель.
-
При желании подключите облачный провайдер в настройках: Jan поддерживает OpenAI, Anthropic и другие API, что позволяет переключаться между локальной и облачной моделью прямо в интерфейсе.
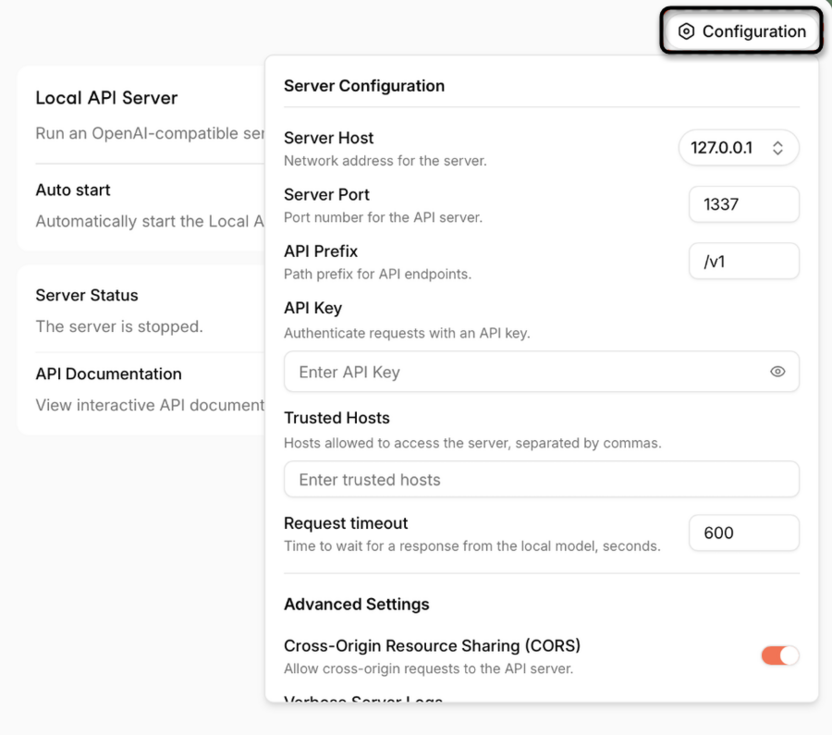
Интересная особенность Jan – возможность совмещать локальную и облачную работу в одном приложении. Если локальная модель не справляется со сложной задачей, достаточно переключить беседу на облачный API и продолжить без смены инструмента.
Управление беседами здесь организовано более аккуратно, чем у LM Studio: разговоры сортируются по дате, поддерживаются поиск и экспорт истории. При этом нужно учитывать, что проект активно развивается и отдельные функции иногда работают нестабильно от версии к версии.
ComfyUI
Все рассмотренные выше инструменты работали с текстом, тогда как ComfyUI относится к принципиально другой категории: это оболочка для нейросетей, которые генерируют изображения. В основе интерфейса лежит система нод – визуальных блоков, соединяющихся в цепочки и описывающих каждый этап обработки: загрузку модели, применение настроек, собственно генерацию и улучшение качества результата. Выглядит это сложнее привычного чата, зато дает полный контроль над процессом и позволяет строить любые нестандартные пайплайны – от простой генерации по тексту до сложных сценариев с несколькими моделями.
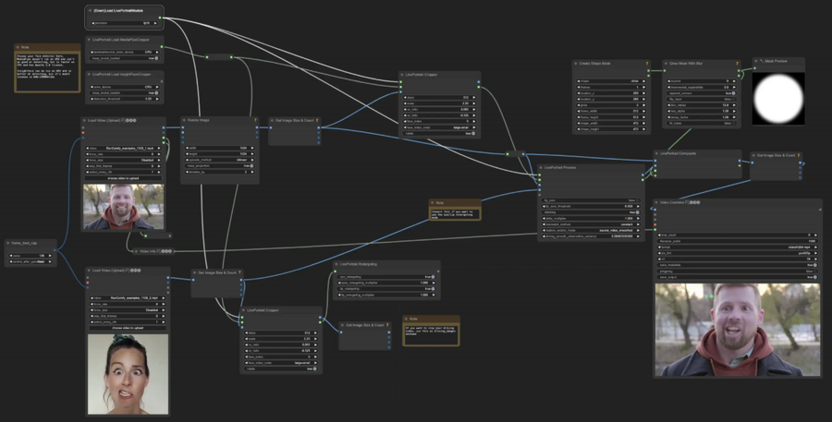
Для комфортной работы с ComfyUI понадобится видеокарта NVIDIA с минимум 6 ГБ VRAM. Генерация на меньших объемах возможна, но будет заметно медленнее. Перед установкой стоит выделить под программу и модели несколько десятков гигабайт на диске.
-
Перейдите на страницу проекта ComfyUI на GitHub и скачайте архив с последней версией для Windows или воспользуйтесь установочным скриптом для macOS и Linux.
-
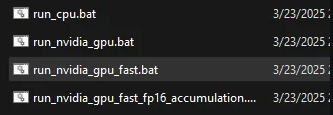
Распакуйте архив и запустите файл run_nvidia_gpu.bat для систем с видеокартой NVIDIA или run_cpu.bat для работы только на процессоре.
-
ComfyUI откроется в браузере по локальному адресу. Скачайте модель в формате .safetensors с Hugging Face или CivitAI и поместите ее в папку models/checkpoints внутри директории ComfyUI.
-
Загрузите готовый воркфлоу из примеров или настройте ноды вручную, указав нужную модель и параметры генерации, затем нажмите «Queue Prompt».
В отличие от более простых генераторов изображений, ComfyUI позволяет комбинировать несколько моделей в одном процессе, применять LoRA-адаптеры и использовать ControlNet для точного управления позой или стилем объектов. Сообщество активно создает готовые воркфлоу под конкретные задачи, которые можно просто импортировать и использовать без глубокого изучения всей системы нод.
Порог входа здесь объективно выше, чем у оболочек для текстовых моделей, поэтому если цель – быстро попробовать генерацию изображений без лишних сложностей, стоит сначала рассмотреть более простые альтернативы.
Заключение
Все описанные инструменты решают одну задачу, но делают это по-разному, ориентируясь на разные сценарии использования. LM Studio подойдет большинству пользователей, которым нужен удобный старт. Ollama будет полезен тем, кто планирует встраивать нейросеть в свои проекты или подключать ее к редактору кода. GPT4All выручит на слабом железе и там, где нужна быстрая работа с документами. Jan станет разумным выбором, если открытый исходный код и отсутствие телеметрии принципиально важны. ComfyUI – отдельная история для тех, кто хочет работать с генерацией изображений и готов потратить время на изучение нод-интерфейса.
Изображение на обложке: Magnific






Комментарии