



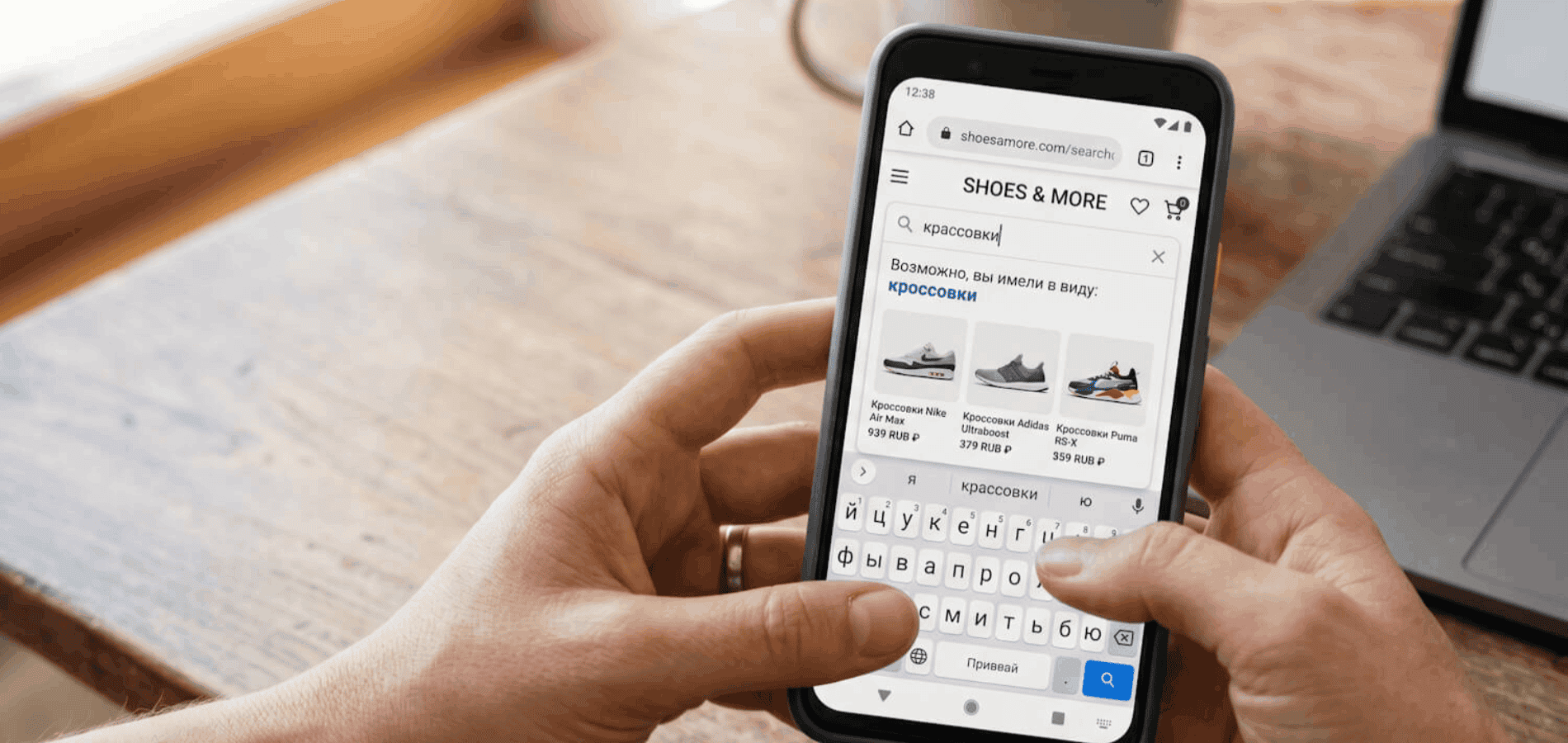
Представьте обувной интернет-магазин. Покупатель торопится, набирает в строке поиска «адидас крассовки» и нажимает Enter. На складе сотни пар Adidas, но в ответ он видит пустую страницу: «Ничего не найдено». Через секунду этот человек уже в соседней вкладке у конкурента, и заказ ушел туда.
История бытовая, но за ней стоят деньги. Внутренним поиском пользуется около 30% посетителей магазина, и конвертируются они в покупателей в 2-3 раза чаще остальных (по данным Cimulate, 2024). Это самая горячая аудитория: человек уже знает, чего хочет, и прямым текстом об этом сообщает. Терять его на опечатке обиднее всего, тем более что слабый поиск – проблема массовая, а не единичная.
По оценке Baymard Institute, у 56% сайтов поиск работает «посредственно или хуже».
Хороший поиск умеет прощать опечатки, понимать разные формы слова и подбирать синонимы. «Крассовки» он соотнесет с «кроссовками», запрос «кеды» дополнит близкими моделями, а «адидас» свяжет с латинским Adidas. Со стороны это выглядит почти как чтение мыслей, хотя никакой магии здесь нет: за результатом стоит несколько понятных механизмов, которые обрабатывают запрос по очереди. Дальше разберем их по шагам, без погружения в код и устройство баз данных, на уровне принципов, которые полезно понимать любому, кто отвечает за сайт или магазин.
Почему обычный поиск не находит «крассовки»
Чтобы понять, в чем фокус умного поиска, полезно сначала посмотреть, как ищет «обычный». Самый наглядный пример буквального поиска – сочетание клавиш Ctrl+F в браузере или текстовом редакторе. Оно перебирает символы на странице и подсвечивает только точные вхождения. Набрали «кроссовки» – найдутся «кроссовки», но не «кросовки» с опечаткой и не «кроссовкам» в другом падеже. Для строчки текста этого достаточно, для каталога с тысячами товаров и живыми людьми за клавиатурой – уже нет.
Долгое время поиск по сайтам устроен был похоже. Система сравнивала запрос с названиями товаров буквально, символ в символ, и возвращала только то, что совпало точно. Любое отклонение от «идеального» написания ломало результат.
Покупатель вводил «kola» латиницей вместо «кола», «рюзак» вместо «рюкзак» или «шампун сухие волосы» без падежей, и магазин честно отвечал, что ничего такого у него нет, хотя товар лежал на складе. Проблема не в покупателе: люди торопятся, печатают с телефона одним пальцем, путают раскладку и просто не знают, как именно назван товар в вашей базе.
Умный поиск решает ровно эту задачу. Вместо требования «напиши точно» он исходит из вопроса «что человек, скорее всего, имел в виду».
Нечеткий поиск (от англ. fuzzy search, «приблизительный поиск») – это набор приемов, которые позволяют находить подходящие результаты, даже когда запрос не совпадает с тем, что хранится в базе, буквально: есть опечатки, другая форма слова или синоним.
Само слово «нечеткий» сбивает с толку: кажется, будто такой поиск работает неаккуратно. На деле наоборот. Он строже подходит к тому, что нужно человеку, и мягче – к тому, как именно человек это написал. Из чего складывается эта мягкость и почему она не превращается в хаотичную выдачу, разберем дальше по шагам, начиная с самого первого: что происходит с запросом сразу после нажатия Enter.
Шаг первый: как запрос приводят к единому виду
Прежде чем что-то искать, систему нужно понять, что именно ей дали. Человек вводит запрос как придется: с заглавными буквами и лишними пробелами, в спешке оставляет хвост вроде «купить недорого», иногда вообще набирает в неправильной раскладке. Если сравнивать такую строку с базой напрямую, совпадений почти не будет. Поэтому первый шаг любого поиска – нормализация, то есть приведение запроса к единому, «причесанному» виду, с которым уже можно работать.
Сначала запрос разбивают на отдельные слова. Этот шаг называется токенизацией: строка «зимние ботинки мужские» превращается в три самостоятельных элемента, каждый из которых дальше обрабатывается отдельно. После этого над словами выполняют несколько чисто технических операций:
- Приведение к нижнему регистру, чтобы «Ботинки», «БОТИНКИ» и «ботинки» считались одним и тем же словом.
- Очистка от лишнего: повторяющихся пробелов, знаков препинания и «мусорных» слов вроде «купить», «цена», «недорого», которые не помогают сузить поиск.
- Исправление раскладки клавиатуры, когда человек забыл переключить язык и набрал русское слово латинскими клавишами.
Последний пункт стоит показать на примере, потому что выглядит он почти волшебно. Если набрать слово «привет» на клавиатуре, не переключив раскладку с английской на русскую, получится «ghbdtn». Для буквального поиска это бессмыслица, но система знает, какая русская буква стоит под каждой латинской клавишей, и способна восстановить исходный запрос. Тот же механизм спасает и обратную ситуацию, когда латинское название бренда случайно набрано в русской раскладке.
В крупнейшем исследовании набора текста (Aalto University совместно с Кембриджем и ETH Zürich, 37 000 участников) выяснилось, что на смартфоне люди делают примерно в пять раз больше ошибок, чем на компьютере: около 42 опечаток на каждые 100 слов против 8
Данные ScienceDaily, 2019.
Сюда же примыкает автодополнение – подсказки, которые выпадают по мере ввода. Стоит набрать «крос», как магазин предлагает «кроссовки», «кроссовки мужские», «кроссовки Adidas». Это та же работа над сырым запросом, только на опережение: система помогает человеку сформулировать запрос правильно, не дожидаясь опечатки. На выходе из этого шага вместо хаотичной строки получается чистый набор слов в едином формате. Только теперь начинается собственно поиск, и первым делом он учится прощать ошибки.
Как поиск прощает опечатки
Теперь у системы на руках чистый набор слов, но в одном из них покупатель ошибся: написал «крассовки» вместо «кроссовки». Буквального совпадения в базе нет. Чтобы все-таки найти товар, поиск перестает требовать точного совпадения и начинает мерить, насколько одно слово похоже на другое. Если непохожесть невелика, слова считаются одним и тем же.
Меру непохожести придумали давно, она называется расстоянием Левенштейна. Идея простая: это количество мелких правок, которые нужно внести в одно слово, чтобы получить другое. Под правкой понимают одно из четырех действий с буквами:
- Пропуск буквы: «кросовки» вместо «кроссовки» (потеряна одна «с»).
- Лишняя буква: «крассовки» вместо «кроссовки» (добавлена лишняя «с»).
- Перестановка соседних букв: «кроссовик» вместо «кроссовки».
- Неправильная буква: «кроссовкы» вместо «кроссовки».
В случае с «крассовки» достаточно убрать одну лишнюю букву и поправить гласную, чтобы получить «кроссовки». Это близко, поэтому система уверенно соотносит запрос с товаром.
«Крассовки» → «кроссовки»: расстояние Левенштейна равно 2. Слова различаются всего двумя правками, и при стандартном пороге поиск считает их совпадением
Чтобы поиск не находил откровенно чужие слова, у этой меры есть порог. Обычно он равен двум: слова, отличающиеся на две правки и меньше, считаются совпадением, на три и больше – уже нет. Порог защищает от мусора. Если разрешить слишком большое расстояние, по запросу «кот» начнут находиться «код», «рот», «ком» и десяток других слов, к товару отношения не имеющих.
Расстояние Левенштейна – основной, но не единственный прием. Длинные слова часто сверяют по кусочкам из нескольких букв (их называют n-граммами): если у запроса и товара совпадает большинство таких кусочков, слова считаются родственными. А для имен собственных и брендов иногда подключают фонетические алгоритмы, которые сравнивают слова по звучанию, а не по написанию, и помогают, когда человек пишет название так, как слышит. Вместе эти приемы дают поиску запас прочности к человеческим ошибкам. Но опечатка – не единственная причина, по которой буквальное совпадение не срабатывает. Чаще мешает то, что русский язык изменяет слова по форме.

Как поиск понимает словоформы и синонимы
С опечатками поиск справляется, но это лишь половина задачи. Вторая сложность в том, что одно и то же слово в русском языке выглядит по-разному: «кроссовки», «кроссовок», «кроссовкам», «кроссовками». Покупатель пишет «купить кроссовок», а в карточке товара значится «кроссовки», и для буквального сравнения это два разных слова, хотя речь об одном. Здесь поиску помогает морфология, то есть знание о том, как слова меняют форму.
Работают с морфологией двумя способами. Первый, попроще, называется стеммингом: у слова грубо отсекают окончание и оставляют основу, «кроссовк-». Все формы сводятся к этому огрызку, и они начинают совпадать между собой. Способ быстрый, но прямолинейный: основа получается не всегда красивой и иногда склеивает слова, которые лучше бы различать.
Второй способ, лемматизация, аккуратнее: он приводит слово к словарной форме, то есть к тому виду, в каком слово стоит в словаре («кроссовки» в именительном падеже, «бежать» в инфинитиве). Лемматизация требует словаря и понимания грамматики, зато реже ошибается.
Цена непонятого запроса высока: 68% интернет-магазинов превращают страницу «ничего не найдено» в тупик, не предлагая покупателю ни альтернатив, ни подсказок, куда идти дальше
Остается случай, когда человек называет товар совсем другим словом. Один ищет «газировку», другой «лимонад», третий «колу», а в каталоге товар записан как «напиток газированный». Морфология тут бессильна, потому что это не формы одного слова, а разные слова с близким смыслом. Для них заводят словарь синонимов: список групп слов, которые магазин считает равнозначными. Наглядно разница между уровнями видна на сравнении.
| Что ввел покупатель | Найдет буквальный поиск | Найдет умный поиск |
| кроссовок | ничего (нет точного слова) | кроссовки (морфология) |
| газировка | ничего (товар назван иначе) | напиток газированный (синонимы) |
| Adidas адидас | по-разному в зависимости от раскладки | один и тот же бренд |
Со словарем синонимов важно не переусердствовать. Чем шире списки, тем больше товаров поиск считает «подходящими», и тем легче в выдачу попадает лишнее. Если объявить синонимами «чехол» и «телефон», по запросу про чехлы магазин начнет подмешивать смартфоны, и человек решит, что поиск сломан. Поэтому синонимы обычно настраивают точечно, под конкретный ассортимент, а не берут готовый словарь целиком. К этому разговору о балансе мы еще вернемся, когда дойдем до подводных камней. Пока же у нас накопилось много кандидатов в ответ, и их нужно как-то выстроить по порядку.
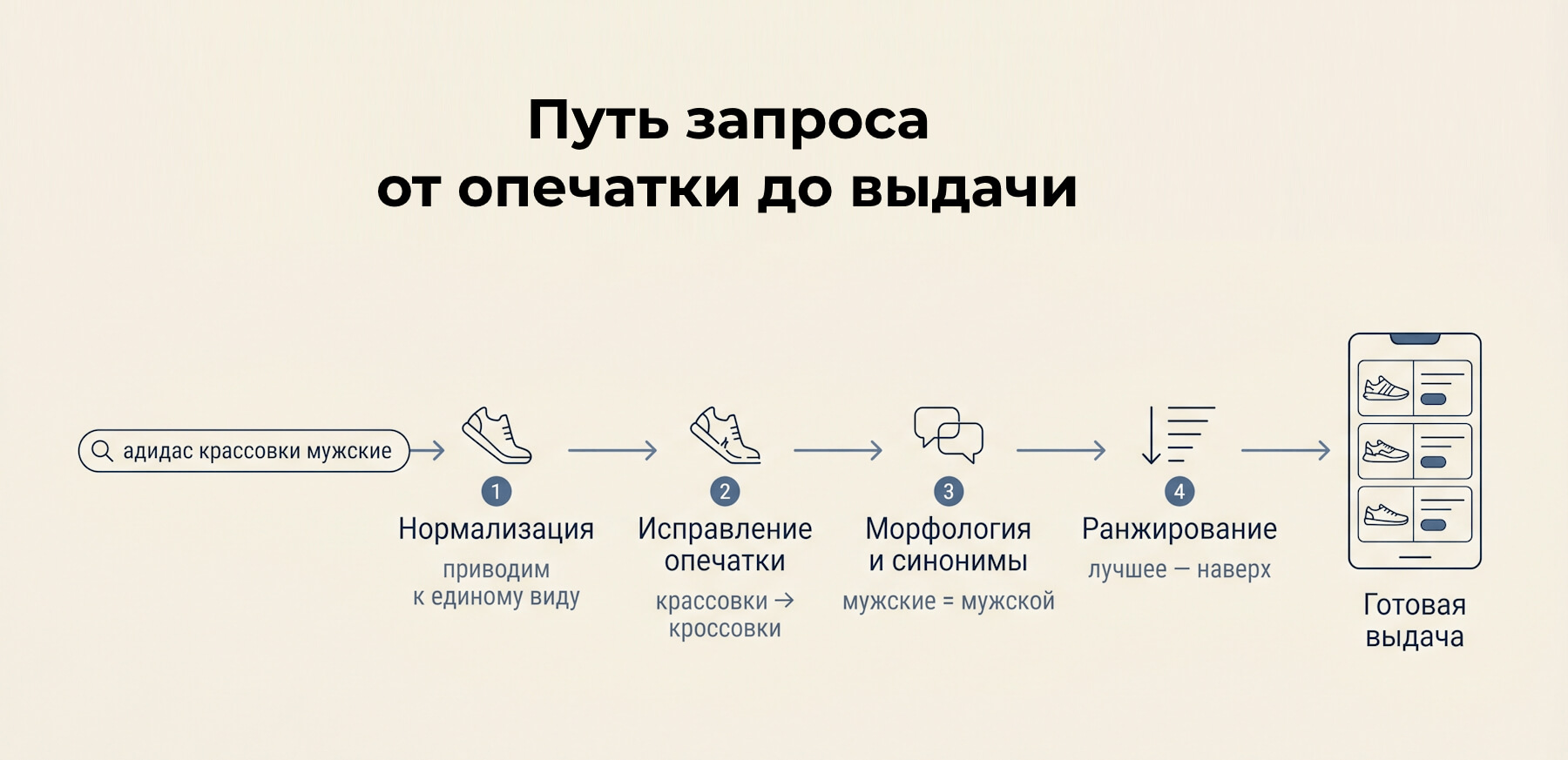
Как из десятков совпадений выбирается то, что нужно
После всех послаблений система обычно находит не один товар, а десятки. По запросу «кроссовки» подходят и точные совпадения, и формы слова, и синонимы, и модели с легкой опечаткой в названии. Показать их в случайном порядке – почти то же самое, что не найти ничего: нужное утонет на третьей странице. Поэтому финальный шаг поиска – ранжирование, расстановка результатов по убыванию релевантности, то есть по тому, насколько каждый товар соответствует запросу.
Главный принцип ранжирования – чем точнее совпадение, тем выше место.
Выстраивается своего рода лесенка приоритетов:
- Точное совпадение слова стоит выше всего: человек написал ровно то, что есть в базе.
- Другая форма того же слова идет следом, она почти так же надежна.
- Совпадение с одной опечаткой ниже, с двумя опечатками – еще ниже.
- Совпадение по синониму замыкает список: смысл близкий, но слово человек выбрал другое.
За этим стоит понятное соображение: даже если опечатка очевидна человеку, точное совпадение все равно остается для системы более надежным сигналом, чем исправленное. Но одной близости текста мало. Два товара могут одинаково точно подходить под запрос, а показать вперед стоит тот, что принесет пользу и покупателю, и магазину. Поэтому к текстовой релевантности добавляют другие факторы: есть ли товар в наличии (нет смысла поднимать наверх то, что нельзя купить), насколько он популярен и хорошо продается, какой у него рейтинг. Так чисто языковое совпадение превращается в осмысленную выдачу.
Соберем все шаги в один пример и проследим, как живой запрос проходит конвейер целиком. Покупатель вводит «адидас крассовки мужские». Сначала нормализация приводит фразу к нижнему регистру, разбивает на слова и связывает «адидас» с брендом Adidas. Затем нечеткое сопоставление исправляет «крассовки» на «кроссовки» по расстоянию Левенштейна. Морфология понимает, что «мужские» и «мужской» – одно и то же. После этого находятся все подходящие модели, и ранжирование поднимает наверх те, что есть в наличии и хорошо продаются. На пустую страницу из начала статьи человек уже не попадет.
Иногда покупателю, наоборот, нужно точное совпадение без всех этих послаблений. На такой случай многие сайты позволяют взять запрос в кавычки: это сигнал поиску отключить исправление опечаток и синонимы и искать ровно то, что написано. Удобно, когда человек ищет конкретный артикул или редкое название, которое поиск иначе попытается «исправить».
Что это дает бизнесу и как оценить свой поиск
Из механики складывается прямая выгода. Поиск, который прощает ошибки и понимает синонимы, превращает несостоявшиеся пустые выдачи в показы товаров, а значит, удерживает ту самую горячую аудиторию, что конвертируется в покупателей в 2-3 раза чаще обычных посетителей (по данным Cimulate, 2024). Параллельно он снимает нагрузку с поддержки: человек сам находит «цемент М500 в мешках» или нужный артикул вместо того, чтобы писать в чат и спрашивать менеджера.
Чтобы понять, насколько хорошо работает поиск в конкретном магазине, на него полезно посмотреть глазами покупателя и сверить по нескольким пунктам:
- Введите название популярного товара с явной опечаткой. Хороший поиск все равно его найдет; буквальный вернет пустую страницу.
- Поищите товар в другой форме слова и через разговорный синоним. Проверяете морфологию и словарь синонимов.
- Наберите запрос в неправильной раскладке. Система должна догадаться, что вы имели в виду.
- Посмотрите, есть ли подсказки и автодополнение по мере ввода.
- Проверьте, поднимаются ли наверх товары в наличии, а не распроданные позиции.
Кроме ручной проверки, качество поиска видно по цифрам в аналитике. Главная из них – доля нулевых выдач, то есть процент запросов, по которым магазин не нашел ничего. Высокое значение прямо указывает на потерянные продажи и подсказывает, чего людям не хватает: иногда товара действительно нет в ассортименте, а иногда он есть, но поиск его не находит из-за опечаток или незнакомого синонима. Вторая важная цифра – конверсия из поиска: сравните, как часто покупают те, кто пользовался поиском, и остальные посетители. Если разрыв небольшой или поисковая аудитория покупает не лучше прочих, поиск недорабатывает, ведь обычно эти люди заметно активнее.

У умного поиска есть и обратная сторона, про которую легко забыть в погоне за «находит все». Слишком высокая терпимость к опечаткам и раздутый словарь синонимов засоряют выдачу: по запросу про чехлы всплывают телефоны, по запросу про конкретную модель добавляются отдаленно похожие. Покупатель видит кашу из нерелевантных товаров и доверяет поиску меньше, чем если бы тот честно показал немного, но по делу. Поэтому настройка поиска – это поиск баланса между «прощать ошибки» и «не выдумывать лишнего», и этот баланс стоит периодически перепроверять по той же доле нулевых выдач и по тому, что реально покупают из поисковой выдачи.
Куда движется поиск
Все, о чем шла речь, работает на уровне слов: система сопоставляет написанное с тем, что лежит в базе, и прощает человеку неточности. Следующий шаг, который уже входит в обиход, поднимается на уровень смысла. Что такое семантический поиск, заслуживает отдельного разговора, но, если коротко: он пытается понять не буквы запроса, а намерение за ним. Человек вводит «что надеть на пробежку зимой», не называя ни одного товара напрямую, а поиск выводит утепленные кроссовки и термобелье, потому что улавливает смысл фразы, а не ищет в ней знакомые слова.
Разница с привычным поиском принципиальная. Нечеткое сопоставление считает, насколько похожи написания слов, а семантический поиск оценивает, насколько близки их значения, и связывает запрос с товаром даже без единого общего слова. Опечатки и синонимы он переносит как само собой разумеющееся: «газировку» и «лимонад» он сближает не по словарю, который кто-то завел вручную, а потому что в текстах они встречаются в похожих контекстах. В ту же сторону движется и весь способ общения с магазином.
Помимо текстового запроса покупатели все чаще обращаются к магазину голосом, ищут товар по фотографии и задают вопросы чат-ботам обычными словами, как живому консультанту.
При этом разобранные сегодня механизмы никуда не денутся. Исправление опечаток, морфология, словари синонимов и ранжирование остаются фундаментом, на который более умные технологии надстраиваются сверху, а не заменяют его. Понимание этого фундамента и есть практическая ценность: оно позволяет говорить с подрядчиком на одном языке, осмысленно читать аналитику поиска и видеть в пустой выдаче не каприз покупателя, а конкретную задачу, у которой есть решение. А начинается все по-прежнему с малого: с того, чтобы магазин нашел человеку кроссовки, даже когда тот написал «крассовки».






Комментарии