




Когда вам говорят, что 94% тикетов закрыты в рамках SLA, это звучит как хорошая новость. Тикет получил статус «Решен», значит, все в порядке. Но статус в хелпдеске и реальный опыт пользователя живут в разных плоскостях.
Тикет может быть закрыт, а проблема остаться нерешенной. Оператор ответил вовремя, но мимо сути. Пользователь написал в чат, не получил нужного и просто перестал писать. Внутренняя метрика зафиксировала это как успех.
Такой разрыв обходится дорого. Большинство недовольных пользователей не жалуются напрямую, они уходят молча.
91% клиентов, недовольных сервисом, не возвращаются к компании. Большинство из них при этом не сообщают о проблеме и просто уходят к конкуренту (По данным Livework Studio, 2023).
Выход один: измерять поддержку не только изнутри, но и глазами пользователя. Для этого существуют метрики клиентского опыта. Они фиксируют не «сколько задач закрыто», а «насколько человеку было удобно» и «доволен ли он результатом». Ниже разберемся, что измерять, как внедрить с нуля и каких ошибок лучше не допускать.
Пять метрик, которые измеряют поддержку глазами пользователя
Метрики клиентского опыта делятся на две категории: одни фиксируют субъективное ощущение пользователя, другие отражают объективную эффективность команды. Для полной картины нужны обе. Ниже пять метрик, которые охватывают эти категории с минимальным дублированием.
1. CSAT (Customer Satisfaction Score)
Самый прямой способ узнать, доволен ли пользователь конкретным взаимодействием. После закрытия тикета или чата человеку задают один вопрос: «Насколько вы довольны нашей поддержкой?» по шкале от 1 до 5 или от 1 до 10. Считается просто: количество положительных оценок делят на общее число ответов и умножают на 100%.
Есть важная оговорка. CSAT оценивает конкретного оператора и конкретное взаимодействие, а не продукт целиком. Если пользователь недоволен тем, что функция работает не так, как ему хотелось бы, низкая оценка здесь не про поддержку. Поэтому CSAT нельзя смешивать с NPS: это разные вопросы о разном.
2. CES (Customer Effort Score)
Метрику часто недооценивают. CES измеряет не удовлетворенность, а затраченное усилие: насколько легко пользователю было решить свой вопрос. Формулировка примерно такая: «Компания сделала так, что решить вопрос было легко», пользователь оценивает степень согласия по шкале от 1 до 7.
Исследование CEB/Gartner показало, что снижение усилий предсказывает лояльность точнее, чем попытки порадовать клиента дополнительными бонусами.
Пользователи с низким усилием возвращаются, а те, кто столкнулся с трудностями, уходят даже при высоком CSAT. Поэтому CES особенно полезен там, где CSAT стабильно высокий, но отток не снижается.
3. NPS (Net Promoter Score)
NPS измеряет готовность рекомендовать сервис: «С какой вероятностью вы порекомендуете нас другу или коллеге?» по шкале от 0 до 10. Те, кто ставит 9-10, считаются промоутерами, 0-6 критиками, 7-8 нейтралами. NPS равен проценту промоутеров минус процент критиков.
В отличие от CSAT, NPS отражает общее отношение к продукту, а не к отдельному обращению в поддержку. В этом его ограничение при оценке именно сервиса: если пользователь обожает продукт, он поставит 10 даже после посредственного ответа оператора. Лучше всего NPS работает в паре с CSAT как долгосрочный индикатор лояльности.
4. FRT (First Response Time)
Время от обращения до первого ответа оператора. Единственная метрика в списке, которую пользователь не оценивает словами, а ощущает физически: он видит, сколько ждал.
По данным HubSpot, больше половины пользователей ожидают ответа быстрее чем за три часа. В этот промежуток укладываются 67% компаний, а 32% не успевают.
FRT ничего не говорит о качестве ответа. Быстрый, но бесполезный ответ даст хороший FRT и низкий CSAT. Поэтому метрику анализируют в связке с другими показателями, а не отдельно.
5. FCR (First Contact Resolution)
FCR показывает, какой процент обращений закрывается с первого раза, без повторных. Формула: количество вопросов, решенных при первом контакте, делят на общее число обращений и умножают на 100%.
Для большинства онлайн-сервисов и SaaS-компаний хорошим ориентиром считается диапазон 70-80% (Данные Umbrex, 2024; Alexander Jarvis, 2025).
Из всех пяти метрик FCR точнее всего отражает реальное качество работы команды: пользователь получил ответ, который решил его проблему, и ему не пришлось обращаться снова. Но считать FCR по техническому признаку (нет повторного тикета, значит решено) нельзя: человек может просто прекратить писать, так и не получив нужного. Надежнее измерять FCR прямым вопросом в опросе: «Ваш вопрос был решен полностью?»
Какую метрику выбрать под вашу задачу
Пять метрик не равнозначны по назначению, и запускать их все сразу с нуля смысла нет. У каждой своя зона ответственности, свой момент сбора и свой вопрос, на который она отвечает. Таблица ниже помогает сориентироваться.
| Метрика | Что измеряет | Когда собирать | Лучше всего подходит для |
|---|---|---|---|
| CSAT | Удовлетворенность конкретным взаимодействием | Сразу после закрытия тикета | Оценки операторов, контроля точек касания |
| CES | Усилие, потраченное на решение вопроса | Сразу после обращения | Выявления трения в процессе поддержки |
| NPS | Готовность рекомендовать сервис в целом | Через 30–90 дней после старта или ключевого события | Долгосрочной лояльности и общего здоровья продукта |
| FRT | Скорость первого ответа | Автоматически из хелпдеска | Операционного контроля нагрузки на команду |
| FCR | Процент вопросов, закрытых с первого раза | Через опрос после закрытия + технический счетчик | Реального качества работы поддержки |
Связки метрик рассказывают больше, чем каждая по отдельности. Несколько комбинаций дают особенно полезные сигналы:
- Высокий CSAT при низком FCR: операторы общаются вежливо, пользователям нравится тон, но проблемы реально не решаются. Скрытая беда, когда метрики выглядят нормально, а отток растет.
- Высокий CSAT при низком NPS: взаимодействие с поддержкой оценивается хорошо, но продукт в целом разочаровывает. Поддержка тут ни при чем, проблема глубже.
- Низкий CES при любом CSAT: получить помощь сложно независимо от того, доволен ли человек результатом. Сигнал к упрощению процессов, от каналов и формы обращения до маршрутизации.
- FRT в норме, а CSAT падает: отвечают быстро, но не по делу. Повод проверить качество ответов и базу знаний.
Если ресурс ограничен и нужна одна точка входа, логика такая. Начните с CSAT, он дает быструю обратную связь по каждому обращению и сразу показывает проблемных операторов или каналы. Когда CSAT стабилизируется, добавьте FCR, чтобы понять, действительно ли проблемы решаются. NPS и CES имеет смысл подключать на более зрелой стадии, когда базовый процесс уже выстроен.
Полезно держать в голове отраслевые ориентиры: CSAT от 75% считается приемлемым, от 85% сильным результатом; FCR в диапазоне 70-80% норма для онлайн-сервисов и SaaS; NPS от 0 до 30 приемлемо, выше 30 хорошо; CES от 5,5 из 7 комфортный уровень усилий для пользователя.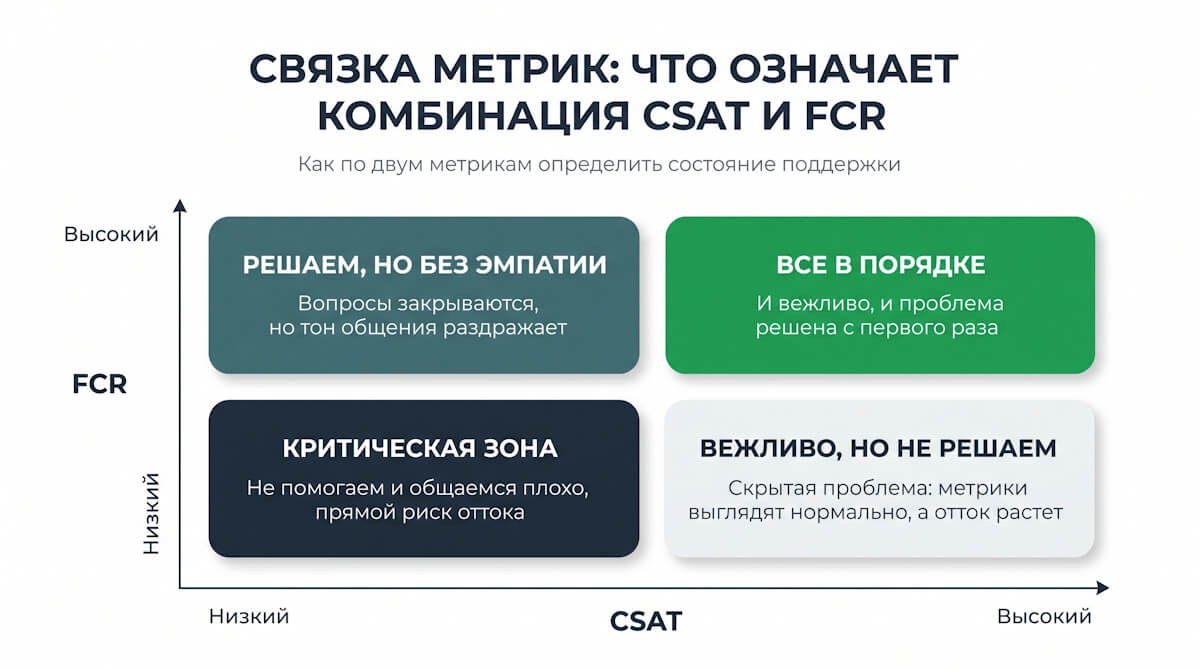
Где и когда спрашивать пользователя
Момент опроса важен не меньше, чем его содержание. Одни и те же вопросы в разное время дают принципиально разные результаты. Пользователь, которого спросили сразу после решения, отвечает по свежим эмоциям. Тот, кого потревожили через неделю, уже не помнит деталей или просто пропустит письмо.
Основной принцип такой: триггер опроса должен совпадать с пиком эмоции, а не с удобством системы. Если хелпдеск отправляет опросы раз в неделю пакетом, это удобно технически, но бесполезно аналитически. Ниже точки сбора под каждую метрику с логикой выбора момента.
- CSAT собирают сразу после закрытия тикета или чата, не позже, чем через 8 часов. В чате опрос лучше показать прямо в том же окне, а не отдельным письмом на почту, потому что переключение канала снижает процент ответов. Оптимальная формулировка: «Насколько вы довольны качеством нашей поддержки?» по шкале от 1 до 5.
- CES задают сразу после завершения обращения, пока пользователь еще в контексте взаимодействия. Вопрос: «Насколько легко вам было решить свой вопрос?» по шкале от 1 до 7, где 7 – значит очень легко. CES хорошо ложится в связку с CSAT: одно обращение, два коротких вопроса.
- FCR измеряют прямым вопросом в том же опросе после закрытия: «Ваш вопрос был решен полностью?» с вариантами да и нет. Это надежнее, чем считать отсутствие повторных обращений, ведь человек может прекратить писать, так и не получив нужного, а система зафиксирует это как успех.
- NPS не привязывают к конкретному обращению. Оптимальный момент наступает через 30-90 дней после начала использования сервиса или после значимого события: апгрейда тарифа, завершения онбординга, крупной покупки. Слишком ранний NPS отражает первое впечатление, а не реальный опыт.
- FRT единственная метрика в списке, которую не нужно собирать опросом. Время первого ответа фиксируется автоматически в любом хелпдеске, и задача здесь сводится к настройке отчета и определению целевого показателя для команды.
Остается вопрос о частоте опросов. Слишком частые раздражают пользователей и снижают качество ответов. Рабочая практика: NPS не чаще одного раза в квартал на пользователя, CSAT после каждого обращения, но только одного типа, без дублирования в чате и на почте одновременно.
Как внедрить измерения. От нуля до первого отчета
Многие команды откладывают запуск метрик, потому что кажется, будто надо сразу настроить все и идеально. На практике достаточно пройти шесть шагов, и первые данные появятся уже через неделю.
- Проведите аудит текущего состояния. До выбора метрики ответьте на три вопроса: какие данные о поддержке у вас уже есть, где чаще всего возникают повторные обращения и в каком канале пользователи жалуются чаще всего. Так вы сфокусируетесь на реальной проблемной зоне, а не будете измерять все подряд.
- Выберите одну метрику для старта. Для большинства онлайн-сервисов логичнее начать с CSAT: он быстро дает обратную связь по каждому обращению и не требует сложной настройки. FCR добавляйте вторым, когда поймете базовый уровень удовлетворенности.
- Сформулируйте вопрос и выберите шкалу. Для CSAT: «Насколько вы довольны качеством нашей поддержки?», шкала 1-5. Для FCR: «Ваш вопрос был решен полностью?», да или нет. Для CES: «Насколько легко вам было решить свой вопрос?», шкала 1-7. Не используйте бинарные варианты вроде лайка и дизлайка для CSAT: они завышают показатель и лишают вас нюансов.
- Настройте точку сбора и триггер. Подключите опрос к хелпдеску так, чтобы он уходил автоматически после закрытия тикета. Большинство популярных систем (Zendesk, Freshdesk, Юздеск, HappyDesk) поддерживают это из коробки. Отправляйте опрос в том же канале, где шло общение.
- Определите целевые показатели. Без ориентира непонятно, что считать хорошим результатом. Для старта возьмите CSAT от 80% и FCR от 70%, а когда накопится месяц данных, скорректируйте цели под контекст своего продукта и аудитории.
- Настройте отчет и назначьте ответственного. Дашборд с ключевыми метриками должен обновляться минимум раз в неделю. Кто-то конкретный в команде смотрит на цифры и инициирует разбор, когда показатель падает. Метрика без ответственного превращается в красивую таблицу, которую никто не читает.
Типичные ошибки, которые делают данные бесполезными
Собрать метрики несложно. Труднее добиться, чтобы они отражали реальный опыт пользователя, а не создавали иллюзию контроля. Вот пять ошибок, которые встречаются чаще всего.
- Неверный момент опроса. Анкета, отправленная через три дня после закрытия тикета, измеряет не качество поддержки, а способность пользователя вспомнить, что вообще происходило. Эмоция остыла, детали размылись, ответ выходит случайным.
- Бинарный CSAT. Если дать пользователю всего два варианта (понравилось или нет), показатель искусственно завысится: большинство выберет «понравилось» по умолчанию, лишь бы не вступать в конфликт. Шкала от 1 до 5 дает заметно более точную картину.
- Смещение выборки. На опросы отвечают преимущественно два типа пользователей: очень довольные и очень недовольные. Нейтральное большинство молчит, поэтому CSAT всегда немного перекошен в крайности, и читать его как абсолютную истину нельзя. Количественные метрики полезно дополнять периодическими качественными интервью с «молчунами».
- FCR по техническому признаку. Если считать FCR как «нет повторного тикета в течение 48 часов», система покажет красивые цифры, но скроет пользователей, которые просто сдались и перестали писать. Их проблема осталась нерешенной, а метрика этого не увидит.
- Сбор без реакции. Если пользователь оставил низкую оценку, а команда никак не отреагировала, следующий опрос он проигнорирует. Метрика без процесса работы с результатами превращается в опрос ради отчетности, а не ради улучшений.
Отдельно стоит выделить частую причину расхождения двух метрик.
По наблюдению аналитиков Feedback24, низкий FCR при высоком CSAT нередко возникает, когда операторы закрывают тикет сразу после отправки ответа, не дожидаясь подтверждения от пользователя. Человек доволен вниманием, но вопрос так и не решен. Разделение в системе оценки двух разных вещей, вежливости оператора и решенности проблемы, устраняет эту слепую зону
Источник: https://feedback24.ru, 2024
Что делать с данными дальше
Измерение лишь первый шаг. Реальная ценность метрик появляется тогда, когда данные запускают конкретные действия, а не просто копятся в дашборде.
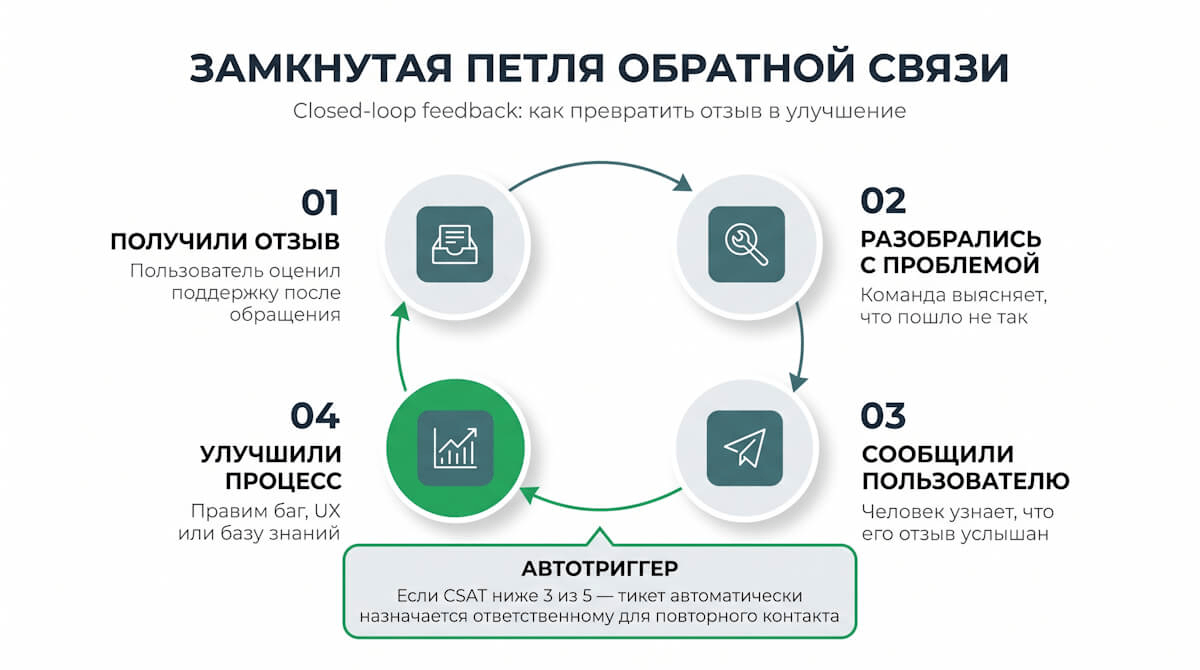
Самая недооцененная практика в работе с обратной связью называется closed-loop feedback: получил отзыв, разобрался с проблемой, сообщил пользователю о результате. Большинство компаний останавливаются на первом шаге. Пользователь написал, что поддержка не помогла, метрика зафиксировала низкий CSAT, команда это увидела и занялась следующим тикетом. О том, что его отзыв услышали, человек так и не узнал.
Замкнуть петлю несложно. Настройте автоматический триггер: если CSAT после обращения оказался ниже 3 из 5, тикет назначается ответственному для повторного контакта. Небольшое усилие со стороны команды дает заметный эффект для восприятия сервиса.
Связь метрик поддержки с оттоком и выручкой проявляется, когда данные копятся несколько месяцев. Низкий FCR коррелирует с ростом повторных обращений, а это прямые операционные затраты. Низкий CES предсказывает отток точнее, чем CSAT: пользователи терпят посредственные ответы, но не терпят лишние усилия.
По данным CEB/Gartner, 96% пользователей, которым пришлось приложить значительные усилия для решения вопроса, в дальнейшем демонстрируют признаки нелояльности. Среди тех, кто прошел взаимодействие легко, таких только 9% (CEB/Gartner, The Effortless Experience).
Поддержка, за которой стоят данные, перестает быть центром затрат и становится источником информации о продукте. Повторяющиеся обращения по одной теме сигналят о баге, неудачном UX или дыре в документации. FCR ниже нормы в конкретной категории вопросов дает повод провести обучение или обновить базу знаний. Так метрики складываются в карту того, где продукт недотягивает.





Комментарии