



Нейросети сейчас повсюду: с их помощью можно находить ответы на вопросы, генерировать картинки в разных стилях и со всевозможным содержанием. Даже крупные бренды используют их при создании контента для соцсетей или сайтов. Наблюдая за этим, невольно задаешься вопросом – как же удалось обучить нейросети выполнять самые разные задачи?
В этой статье мы рассмотрим, с помощью каких методов и алгоритмов обучают нейросети.
На чем основано обучение нейросетей
Под обучением нейросетей понимается настройка их параметров таким образом, чтобы они смогли с максимальной точностью выполнить поставленную задачу. Для этого программа обрабатывает большое количество данных и следует жестко заданным алгоритмам.
Для обучения нейросетей нужно много информации. Данные при этом могут быть размеченными или неразмеченными. Ключевым отличием их является соответственно наличие или отсутствие метки или тега – описательного элемента, с помощью которого модуль при распознавании определяет, чем является тот или иной объект.

Приведем простейший пример: нейросеть учат определять, что изображено на фото. Для этого собирают кучу изображений с разными элементами и помечают их (скажем, человек, животное, автомобиль). Нейросеть этот массив данных изучает, и по пометкам понимает, как выглядит тот или иной объект и что ему внешне свойственно.
Тип используемых данных зависит от методов обучения, и чуть позже мы поговорим об этих методах подробнее.
Помимо данных, в обучении важным являются веса нейросети. Это ее ключевые параметры, которые определяют силу связи между нейронами, также наиболее важные признаки и то, как они повлияют на итоговое решение. С их помощью выстраивается архитектура нейросети, а разработчики подбирают оптимальные параметры.
Методы обучения нейросетей
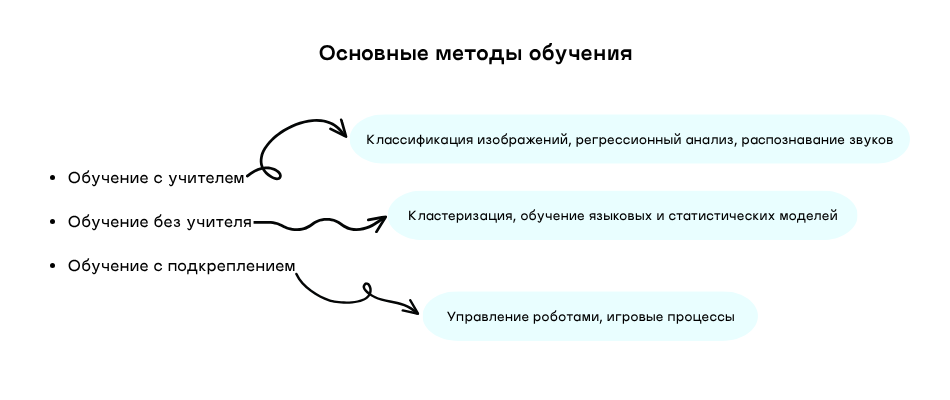
Существует три основных метода обучения нейросетей. Они применяются для разных задач, далее опишем ключевые отличия.
Обучение с учителем (Supervised Learning)
В этот методе для обучения используются размеченные данные. А именно, нейросети подается набор данных, где к каждому примеру прикреплена метка.
В основном такой метод обучения применяют для обучения нейросетей классификации изображений, регрессионному анализу или распознаванию звуков. То есть в данном случае подразумевается решение вопросов, в которых известен требуемый результат.
Обучение без учителя (Unsupervised Learning)
В этой разновидности обучения нейросети подают неразмеченные данные. Анализируя их, ИИ должен выявить скрытые закономерности, кластеры или же структуры. Нейросеть самостоятельно выстраивает логическую цепочку на основании предоставленного материала.
Применяется этот вид для обучения нейросетей кластеризации, языковых или же статистических моделей.
Обучение с подкреплением (Reinforcement Learning)
В этом методе обучение происходит путем взаимодействия нейросети в окружающей средой. За правильно выполненные действия она получает «награду», а за неправильные – «штрафы».
Этот метод больше подходит для задач, требующих выполнение четкой последовательности действий – это управление роботами или же игровые процессы.
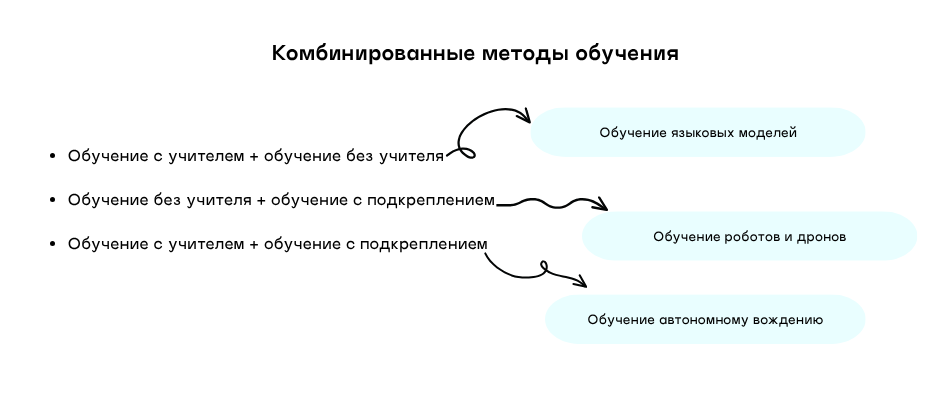
Дополнительно – комбинирование методов обучения (Hybrid Learning)
Известно, что в современных условиях для обучения нейросетей используют сочетание различных методов.
Например, для обучения автономному вождению нейросеть сначала анализирует видеозаписи с вождением человека, а затем начинает практиковаться самостоятельно на симуляторе. В этом случае применяется сочетание методов обучения с учителем и с подкреплением.
Можно еще комбинировать методы обучения с учителем и без учителя. К примеру, при обучении языковых моделей сначала проводится анализ огромного количества текста без пометок, где алгоритм учится предсказывать следующее или пропущенное слово. Следующим этапом идет обучение выполнению конкретной задачи на основе помеченных данных.
Если заходит речь про обучение роботов и дронов, то в этом случае подойдет комбинация методов обучения без учителя и с подкреплением. К примеру, на базе массивов данных нейросеть построит модель среды или узнает, как объекты взаимодействуют в мире. Затем при обучении с подкреплением выполняются конкретные задачи и выбирается стратегия действий.
Алгоритмы оптимизации нейросетей
Механизм обучения у всех нейросетей практически один – обратное распространение ошибки (Backpropagation). Его применяют для обучения практически всех нейросетей. Используя его, можно понять, где именно происходит ошибка при генерации ответа.
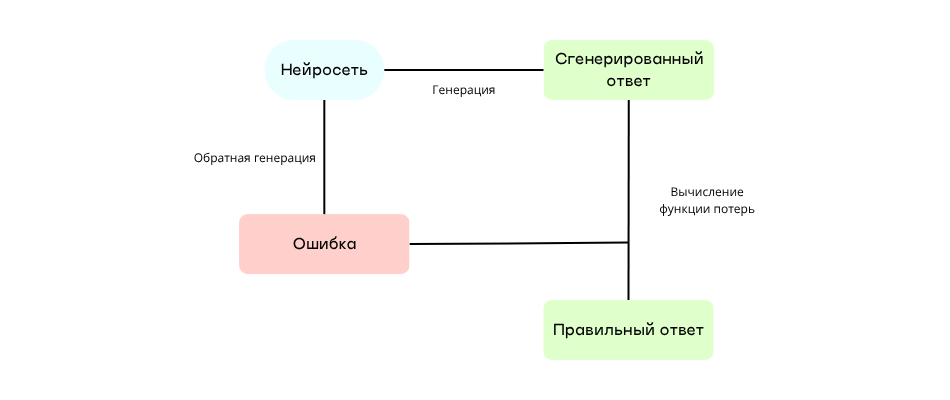
Суть механизма такова: нейросеть генерирует ответ, а затем результат сравнивает с правильным значением – этот процесс называют вычислением функции потерь. Если будет найдена ошибка, ее запустят в обратном порядке – это нужно чтобы понять, какой нейрон повлиял на ошибку. В зависимости от его степени влияния будут вноситься соответствующие изменения. Таким образом нейросеть скорректирует веса, чтобы в следующий раз выдать прогноз ближе к правильному значению.
Еще есть алгоритмы оптимизации – это разные способы настройки весов нейросети. На данный момент выделяют несколько основных алгоритмов:
- Градиентный спуск (Gradient Descent). Этот алгоритм определяет один из основных способов исправления ошибок. Он вычисляет градиент – степень отклонения каждого веса от правильного значения. Вычислив все градиенты, алгоритм выравнивает веса и повторно проводит вычисление. Дальнейшие действия зависят от результата, то есть стал процент ошибок больше или меньше. Такой алгоритм применяют редко и для маленьких наборов данных. Связано такое решение с тем, что вычисления проводятся сразу по всем базам данных, а в такой ситуации все процессы при многократном повторении занимают слишком много времени и оперативной памяти.
- Стохастический градиентный спуск (Stochastic Gradient Descent, сокращенно SGD). В отличие от обычного градиентного спуска, в этом случае сеть обновляет веса после обработки каждого отдельного веса. И когда нейросеть закончит корректировку по первому примеру, то сразу приступит к анализу следующего. В остальном же принцип действия не сильно отличается. Этот способ применяют чаще при обработке больших данных.
- Мини-батч (Mini-batch Gradient Descent). Этот алгоритм является чем-то средним между обычным и стохастическим градиентными спусками. При работе он делит всю выборку на небольшие группы, называемые батчами, содержащими от 32 до 64 примеров. Затем он постепенно анализирует каждую группу и обновляет веса после каждого батча. Уже этот способ применяется при обучении почти всех нейросетей.
- Метод импульса (Momentum). Алгоритм представляется как расширенная версия градиентного спуска. При обучении он учитывает, какими были предыдущие шаги, и при возникновении аналогичных задач выполняет их в разы быстрее.
- Упругое распространение (Resilient Propagation, сокращенно RProp). Данный алгоритм тоже считается улучшенной версией градиентного спуска. При работе учитывается только значение градиента, но не его величина. В процессе обучения при повторных операциях алгоритм делает «шаги» в нужном направлении до тех пор, пока значение не изменится на противоположное или же не достигнет оптимального показателя. В сравнении с градиентным спуском, этот алгоритм считается более стабильным, но в то же время не подходит для обучения глубоких сетей.
- Генетический алгоритм (Genetic Algorithm, сокращенно GA). Этот метод в обучении основывается на принципе естественной эволюции. При обработке данных происходит отбор лучших решений, по аналогии с селекцией. Затем происходит скрещивание параметров лучших решений. В процессе возникают случайные мутации, то есть небольшие изменения ряда значений. Весь цикл повторяется, пока не будет получено оптимальное значение. Работает этот алгоритм медленно, но в то же время он подходит для решения сложных задач – именно этот алгоритм применяют в различных исследованиях.
Отдельно я упомяну здесь про адаптивные методы оптимизации. Сюда относят множество алгоритмов, являющиеся усовершенствованными версиями градиентного спуска. А объединяет их автоматический подбор скорости обучения для каждого параметра. При этом, по аналогии с алгоритмом Momentum, они учитывают и прошлые шаги.
- Адаптивный градиент (Adaptive Gradient, сокращенно Adagrad). Этот алгоритм вычисляет наиболее часто изменяемые веса и уменьшает для него шаги. Он подходит для обучения простых моделей, в том числе текстовых.
- RMSProp (Root Mean Square Propagation). Данный алгоритм, являясь улучшенным вариантом Adagrad, учитывает историю изменения градиентов. Применяется он при обучении рекуррентных нейросетей.
- Adam (Adaptive Moment Estimation). Принцип его работы – сочетание алгоритмов Momentum и RMSProp. Этот алгоритм более распространен и используется при обучении нейросетей самых разных архитектур.
- AdamW – это модифицированная версия алгоритма Adam. Данный алгоритм имеет больше регуляризации для предотвращения слишком частого переобучения. Его используют в большинстве современных фреймворков и больших моделей.
По итогу, выбор алгоритма зависит чаще от того, какого типа нейросеть необходимо обучить и каким способом. Особое внимание стоит обратить на скорость обучения с использованием каждого алгоритма.
Этапы обучения нейросетей
Обучение нейросетей проводится приблизительно в одинаковой последовательности, соответствующей алгоритму обратного распространения ошибки. Представить ее можно следующим образом.
- Сбор данных. В зависимости от метода обучения, на этом этапе может осуществляться сбор информации как с расстановкой меток, так и без их расстановки. При этом чем больше и качественнее будут эти данные, тем лучше в дальнейшем обучится нейросеть.
- Выбор архитектуры нейросети. В зависимости от целей дальнейшего использования нейросети могут иметь несколько типов архитектур. Среди основных разновидностей отмечают перцептрон и многослойный перцептрон, и помимо этого существует множество типов архитектур в зависимости от задач – начиная от сверточных и заканчивая трансформерами.
- Выбор алгоритма оптимизации. Указанные алгоритмы мы подробно рассмотрели в прошлом разделе.
- Обучение. На этом этапе происходит начальная установка весов нейросети, после начинается обработка данных. На выходе получаются определенное выходное значение.
- Оценка. Полученное на выходе значение сопоставляют с фактическими данными, и на основании этого производится расчет ошибки. Чтобы начать пользоваться нейросетью, предполагается, в среднем на 10-20 примеров должно приходиться около 80-90% правильных ответов.
- Корректировка. Если количество ошибок превышает допустимое значение, можно действовать по трем сценариям. Первый – это проведение дополнительного обучения, а реализовать это можно добавлением новых примеров в базы данных. Второй сценарий – смена алгоритмов обучения. Третий же – изменение структуры нейросети.
- Повторение итераций. Пока нужный результат не будет достигнут, нейросеть будет проходить обучение дальше. Когда же количество ошибок уменьшится до допустимых значений, можно запускать нейросеть и начать пользоваться ей для поставленных задач.
А чтобы сократить количество итераций, часто применяются различные методы регуляризации. Это способы «сдерживания» нейросети, чтобы она не запоминала предыдущие данные слишком точно, не потеряла способность к обобщению информации, при этом могла обрабатывать и новые сведения достаточно быстро. Среди основных методов регуляризации сегодня выделяют прореживание, L1 и L2-регуляризацию, раннюю остановку, нормализацию батчей и так далее.
Основное обучение нейросетей происходит до их официального запуска. После релиза их база данных остается статичной, не изменяется и не дополняется информацией из интернета. Чтобы актуализировать ее, проводится дополнительное обучение, после чего выпускаются обновленные версии моделей – это можно наглядно увидеть по тому, как обновляют ChatGPT от OpenAI. Только нужно учитывать, что дообучение – долгий процесс, требующий огромных вычислительных мощностей и времени.
Заключение
В зависимости от целей создания нейросети, обучить ее можно разными способами. Временные затраты и требуемые вычислительные мощности при этом будут тоже отличаться – все зависит только от ожидаемого результата.






Комментарии