



Индексирование сайта – это процесс, с помощью которого поисковые системы, подобные Google и Yandex, анализируют страницы веб-ресурса и вносят их в свою базу данных. Индексация выполняется специальным ботом, который заносит всю необходимую информацию о сайте в систему – веб-страницы, картинки, видеофайлы, текстовый контент и прочее. Корректное индексирование сайта помогает потенциальным клиентам легко найти нужный сайт в поисковой выдаче, поэтому важно знать обо всех тонкостях данного процесса.
В сегодняшней статье я рассмотрю, как правильно настроить индексацию, какие страницы нужно открывать для роботов, а какие нет.
Почему важно ограничивать индексацию страниц
Заинтересованность в индексации есть не только у собственника веб-ресурса, но и у поисковой системы – ей необходимо предоставить релевантную и, главное, ценную информацию для пользователя. Чтобы удовлетворить обе стороны, требуется проиндексировать только те страницы, которые будут интересны и целевой аудитории, и поисковику.
Прежде чем переходить к списку ненужных страниц для индексации, давайте рассмотрим причины, из-за которых стоит запрещать их выдачу. Вот некоторые из них:
- Уникальность контента – важно, чтобы вся информация, передаваемая поисковой системе, была неповторима. При соблюдении данного критерия выдача может заметно вырасти. В противном случае поисковик будет сначала искать первоисточник – только он сможет получить доверие.
- Краулинговый бюджет – лимит, выделяемый сайту на сканирование. Другими словами, это количество страниц, которое выделяется каждому ресурсу для индексации. Такое число обычно определяется для каждого сайта индивидуально. Для лучшей выдачи рекомендуется избавиться от ненужных страниц.
В краулинговый бюджет входят: взломанные страницы, файлы CSS и JS, дубли, цепочки редиректов, страницы со спамом и прочее.
Что нужно скрывать от поисковиков
В первую очередь стоит ограничить индексирование всего сайта, который еще находится на стадии разработки. Именно так можно уберечь базу данных поисковых систем от некорректной информации. Если ваш веб-ресурс давно функционирует, но вы не знаете, какой контент стоит исключить из поисковой выдачи, то рекомендуем ознакомиться с нижеуказанными инструкциями.
PDF и прочие документы
Часто на сайтах выкладываются различные документы, относящиеся к контенту определенной страницы (такие файлы могут содержать и важную информацию, например, политику конфиденциальности).
Рекомендуется отслеживать поисковую выдачу: если заголовки PDF-файлов отображаются выше в рейтинге, чем страницы со схожим запросом, то их лучше скрыть, чтобы открыть доступ к наиболее релевантной информации. Отключить индексацию PDF и других документов вы можете в файле robots.txt.
Разрабатываемые страницы
Стоит всегда избегать индексации разрабатываемых страниц, чтобы рейтинг сайта не снизился. Используйте только те страницы, которые оптимизированы и наполнены уникальным контентом. Настроить их отображение можно в файле robots.txt.
Копии сайта
Если вам потребовалось создать копию веб-ресурса, то в этом случае также необходимо все правильно настроить. В первую очередь укажите корректное зеркало с помощью 301 редиректа. Это позволит оставить прежний рейтинг у исходного сайта: поисковая система будет понимать, где оригинал, а где копия. Если же вы решитесь использовать копию как оригинал, то делать это не рекомендуется, так как возраст сайта будет обнулен, а вместе с ним и вся репутация.
Веб-страницы для печати
Иногда контент сайта требует уникальных функций, которые могут быть полезны для клиентов. Одной из таких является «Печать», позволяющая распечатать необходимые страницы на принтере. Создание такой версии страницы выполняется через дублирование, поэтому поисковые роботы могут с легкостью установить копию как приоритетную. Чтобы правильно оптимизировать такой контент, необходимо отключить индексацию веб-страниц для печати. Сделать это можно с использованием AJAX, метатегом <meta name="robots" content="noindex, follow"/> либо в файле robots.txt.
Формы и прочие элементы сайта
Большинство сайтов сейчас невозможно представить без таких элементов, как личный кабинет, корзина пользователя, форма обратной связи или регистрации. Несомненно, это важная часть структуры веб-ресурса, но в то же время она совсем бесполезна для поисковых запросов. Подобные типы страниц необходимо скрывать от любых поисковиков.
Страницы служебного пользования
Формы авторизации в панель управления и другие страницы, используемые администратором сайта, не несут никакой важной информации для обычного пользователя. Поэтому все служебные страницы следует исключить из индексации.
Личные данные пользователя
Вся персональная информация должна быть надежно защищена – позаботиться о ее исключении из поисковой выдачи нужно незамедлительно. Это относится к данным о платежах, контактам и прочей информации, идентифицирующей конкретного пользователя.
Страницы с результатами поиска по сайту
Как и в случае со страницами, содержащими личные данные пользователей, индексация такого контента не нужна: веб-страницы результатов полезны для клиента, но не для поисковых систем, так как содержат неуникальное содержание.
Сортировочные страницы
Контент на таких веб-страницах обычно дублируется, хоть и частично. Однако индексация таких страниц посчитается поисковыми системами как дублирование. Чтобы снизить риск возникновения таких проблем, рекомендуется отказаться от подобного контента в поисковой выдаче.
Пагинация на сайте
Пагинация – без нее сложно представить существование любого крупного веб-сайта. Чтобы понять ее назначение, приведу небольшой пример: до появления типичных книг использовались свитки, на которых прописывался текст. Прочитать его можно было путем развертывания (что не очень удобно). На таком длинном холсте сложно найти нужную информацию, нежели в обычной книге. Без использования пагинации отыскать подходящий раздел или товар также проблематично.
Пагинация позволяет разделить большой массив данных на отдельные страницы для удобства использования. Отключать индексирование для такого типа контента нежелательно, требуется только настроить атрибуты rel="canonical", rel="prev" и rel="next". Для Google нужно указать, какие параметры разбивают страницы – сделать это можно в Google Search Console в разделе «Параметры URL».
Помимо всего вышесказанного, рекомендуется закрывать такие типы страниц, как лендинги для контекстной рекламы, страницы с результатами поиска по сайту и поиск по сайту в целом, страницы с UTM-метками.
Какие страницы нужно индексировать
Ограничение страниц для поисковых систем зачастую становится проблемой – владельцы сайтов начинают с этим затягивать или случайно перекрывают важный контент. Чтобы избежать таких ошибок, рекомендуем ознакомиться с нижеуказанным списком страниц, которые нужно оставлять во время настройки индексации сайта.
- В некоторых случаях могут появляться страницы-дубликаты. Часто это связано со случайным созданием дублирующих категорий, привязкой товаров к нескольким категориям и их доступность по различным ссылкам. Для такого контента не нужно сразу же бежать и отключать индексацию: сначала проанализируйте каждую страницу и посмотрите, какой объем трафика был получен. И только после этого настройте 301 редиректы с непопулярных страниц на популярные, затем удалите те, которые совсем не эффективны.
- Страницы смарт-фильтра – благодаря им можно увеличить трафик за счет низкочастотных запросов. Важно, чтобы были правильно настроены мета-теги, 404 ошибки для пустых веб-страниц и карта сайта.
Соблюдение индексации таких страниц может значительно улучшить поисковую выдачу, если ранее оптимизация не проводилась.
Как закрыть страницы от индексации
Мы детально рассмотрели список всех страниц, которые следует закрывать от поисковых роботов, но о том, как это сделать, прошлись лишь вскользь – давайте это исправлять. Выполнить это можно несколькими способами: с помощью файла robots.txt, добавления специальных метатегов, кода, сервисов для вебмастеров, а также с использованием дополнительных плагинов. Рассмотрим каждый метод более детально.
Способ 1: Файл robots.txt
Данный текстовый документ – это файл, который первым делом посещают поисковики. Он предоставляет им информацию о том, какие страницы и файлы на сайте можно обрабатывать, а какие нет. Его основная функция – сократить количество запросов к сайту и снизить на него нагрузку. Он должен удовлетворять следующим критериям:
- наименование прописано в нижнем регистре;
- формат указан как .txt;
- размер не должен превышать 500 Кб;
- местоположение – корень сайта;
- находится по адресу URL/robots.txt, при запросе сервер отправляет в ответ код 200.
Прежде чем переходить к редактированию файла, рекомендую обратить внимание на ограничивающие факторы.
- Директивы robots.txt поддерживаются не всеми поисковыми системами. Большинство поисковых роботов следуют тому, что написано в данном файле, но не всегда придерживаются правил. Чтобы полностью скрыть информацию от поисковиков, рекомендуется воспользоваться другими способами.
- Синтаксис может интерпретироваться по-разному в зависимости от поисковой системы. Потребуется узнать о синтаксисе в правилах конкретного поисковика.
- Запрещенные страницы в файле могут быть проиндексированы при наличии ссылок из прочих источников. По большей части это относится к Google – несмотря на блокировку указанных страниц, он все равно может найти их на других сайтах и добавить в выдачу. Отсюда вытекает то, что запреты в robots.txt не исключают появление URL и другой информации, например, ссылок. Решить это можно защитой файлов на сервере при помощи пароля либо директивы noindex в метатеге.
Файл robots.txt включает в себя такие параметры, как:
- User-agent – создает указание конкретному роботу.
- Disallow – дает рекомендацию, какую именно информацию не стоит сканировать.
- Allow – аналогичен предыдущему параметру, но в обратную сторону.
- Sitemap – позволяет указать расположение карты сайта sitemap.xml. Поисковый робот может узнать о наличии карты и начать ее индексировать.
- Clean-param – позволяет убрать из индекса страницы с динамическими параметрами. Подобные страницы могут отдавать одинаковое содержимое, имея различные URL-страницы.
- Crawl-delay – снижает нагрузку на сервер в том случае, если посещаемость поисковых ботов слишком велика. Обычно используется на сайтах с большим количеством страниц.
Теперь давайте рассмотрим, как можно отключить индексацию определенных страниц или всего сайта. Все пути в примерах – условные.
Пропишите, чтобы исключить индексацию сайта для всех роботов:
User-agent: * Disallow: /
Закрывает все поисковики, кроме одного:
User-agent: * Disallow: / User-agent: Google Allow: /
Запрет на индексацию одной страницы:
User-agent: * Disallow: /page.html
Закрыть раздел:
User-agent: * Disallow: /category
Все разделы, кроме одного:
User-agent: * Disallow: / Allow: /category
Все директории, кроме нужной поддиректории:
User-agent: * Disallow: /direct Allow: /direct/subdirect
Скрыть директорию, кроме указанного файла:
User-agent: * Disallow: /category Allow: photo.png
Заблокировать UTM-метки:
User-agent: * Disallow: *utm=
Заблокировать скрипты:
User-agent: * Disallow: /scripts/*.js
Я рассмотрел один из главных файлов, просматриваемых поисковыми роботами. Он использует лишь рекомендации, и не все правила могут быть корректно восприняты.
Способ 2: HTML-код
Отключение индексации можно осуществить также с помощью метатегов в блоке <head>. Обратите внимание на атрибут «content», он позволяет:
- активировать индексацию всей страницы;
- деактивировать индексацию всей страницы, кроме ссылок;
- разрешить индексацию ссылок;
- индексировать страницу, но запрещать ссылки;
- полностью индексировать веб-страницу.
Чтобы указать поискового робота, необходимо изменить атрибут «name», где устанавливается значение yandex для Яндекса и googlebot – для Гугла.
Пример запрета индексации всей страницы и ссылок для Google:
<html>
<head>
<meta name="googlebot" content="noindex, nofollow" />
</head>
<body>...</body>
</html>
Также существует метатег под названием Meta Refresh. Он предотвращает индексацию в Гугле, однако использовать его не рекомендуется.
Способ 3: На стороне сервера
Если поисковые системы игнорируют запрет на индексацию, можно ограничить возможность посещения ботов-поисковиков на сервере. Для этого в корне сайта нужно найти файл .htaccess и добавить в него следующий код.
Для Google:
SetEnvIfNoCase User-Agent "^Googlebot" search_bot
Для Яндекс:
SetEnvIfNoCase User-Agent "^Yandex" search_bot
Способ 4: Для WordPress
На CMS запретить индексирование всего сайта или страницы гораздо проще. Рассмотрим, как это можно сделать.
Как скрыть весь сайт
Открываем административную панель WordPress и переходим в раздел «Настройки» через левое меню. Затем перемещаемся в «Чтение» – там находим пункт «Попросить поисковые системы не индексировать сайт» и отмечаем его галочкой.
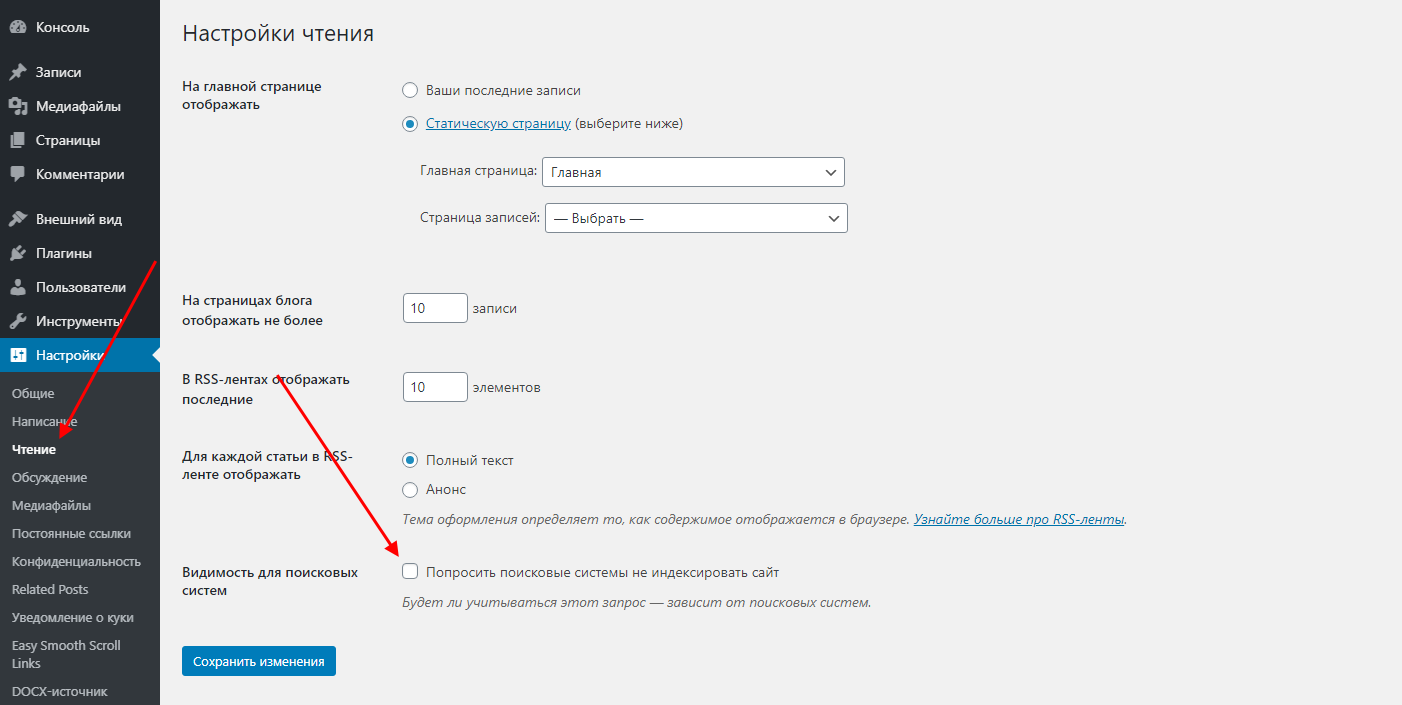
В завершение кликаем по кнопке «Сохранить изменения» – после этого система автоматически отредактирует файл robots.txt.
Как скрыть отдельную страницу
Для этого необходимо установить плагин Yoast SEO. После этого открыть страницу для редактирования и промотать в самый низ – там во вкладке «Дополнительно» указать значение «Нет».
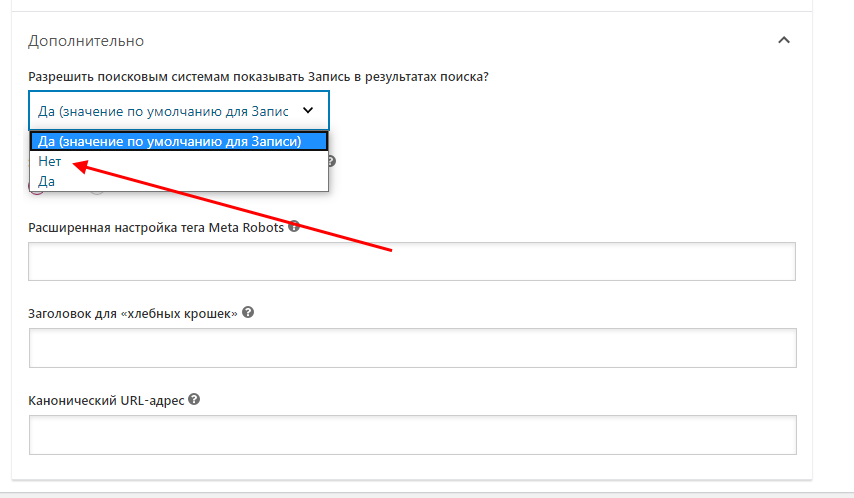
Способ 5: Сервисы для вебмастеров
В Google Search Console мы можем убрать определенную страницу из поисковика. Для этого достаточно перейти в раздел «Индекс Google» и удалить выбранный URL.
Процедура запрета на индексацию выбранной страницы может занять некоторое время. Аналогичные действия можно совершить в Яндекс.Вебмастере.
На этом статья подходит к концу. Надеюсь, что она была полезной. Теперь вы знаете, что такое индексация сайта и как ее правильно настроить. Удачи!




Комментарии
При проверке сайта в .google.search.console по всем страницам категорий выдал ошибку:
Задайте значение для одного из следующих элементов данных: "offers", "review" или "aggregateRating".
Как я понял - он ругается на ссылки товаров в этих категориях.
Нужно просто поставить ссылкам атрибут No Follow, чтобы это исправить?
Вариант - закрыть категории от индексации не годится.
Знаю, что везде рекомендуют закрывать страницы категорий и меток, но у меня эти страницы настроены на конкретные ключевики и поэтому я не хочу их закрывать.
P,S, seo плагин Rank Math SEO
Еще вы пишите, что нужно закрывать для индексации личный кабинет, корзина пользователя, форма обратной связи или регистрации. А что для этого нужно прописать в робот?