




Современные нейросети уже не просто генерируют текст по шаблону – они учатся думать. В 2025 году функции глубокого рассуждения стали настоящим прорывом в развитии искусственного интеллекта. ChatGPT получил режим Reason, Claude обзавелся Extended Thinking, DeepSeek выпустил Deep Think, а Grok представил свой Think mode. Но что это значит для обычных пользователей и стоит ли переплачивать за «размышляющий» ИИ?
Что такое Deep Think и зачем он нужен
Deep Think (глубокое размышление) – это способность нейросети тратить дополнительное время на обдумывание сложных задач перед тем, как дать ответ. Вместо того чтобы сразу выдать первое пришедшее в голову решение, модель проходит через цепочку рассуждений, проверяет свои выводы и может даже отказаться от первоначальной идеи в пользу более точной.
Первые серьезные разработки в этой области начались еще в 2024 году с проекта OpenAI под кодовым названием «Strawberry». К началу 2025 года практически все крупные компании представили свои версии reasoning-моделей. Антропик выпустил Claude с Extended Thinking в феврале 2025, DeepSeek анонсировал R1 в январе, а xAI представил Think mode для Grok 3 в том же периоде.
Для каких задач подходит Deep Think
Функции рассуждения показывают наилучшие результаты в задачах, требующих многошаговых математических вычислений, логического анализа и дедукции. Особенно эффективен Deep Think при написании и отладке сложного кода, решении головоломок и задач на логику, анализе противоречивой информации и планировании многоэтапных проектов.
Однако для простых вопросов, творческих задач или быстрой генерации контента Deep Think может оказаться избыточным. Более того, он заметно замедляет работу и увеличивает расход токенов.
Галлюцинации ИИ: парадокс «умных» моделей
Прежде чем разбирать конкретные реализации, важно понять, что такое галлюцинации ИИ и как на них влияют функции рассуждения.
Галлюцинации ИИ – это ситуации, когда нейросеть генерирует информацию, которая выглядит правдоподобно, но является ложной или выдуманной. Модель может «с уверенностью» назвать несуществующую книгу, привести фальшивую статистику или сослаться на вымышленное исследование.

Многие ожидали, что функции рассуждения снизят количество галлюцинаций, но данные 2025 года показывают противоположную тенденцию. Согласно внутренним тестам OpenAI, модель o3 галлюцинирует в 33% случаев при ответах на вопросы о публичных персонах, что в два раза больше, чем у предыдущей модели o1. Модель o4-mini показала еще худший результат – 48% галлюцинаций.
Исследователи из Transluce обнаружили особенно тревожные примеры. Модель o3 может утверждать, что запустила код на MacBook Pro 2021 года «вне ChatGPT» и скопировала оттуда числа в свой ответ, хотя такой возможности у неё нет. В другом случае модель «с уверенностью» назвала несуществующий судебный прецедент «Thompson v. Western Medical Center (2019)», снабдив его детальным, но полностью вымышленным описанием правовых аргументов.
Еще один показательный пример: когда Gemini Deep Research получил задание проанализировать исследования после выхода GPT-3.5, он заявил, что начнет «с выхода GPT-3.5 в 2020 году». Это была галлюцинация – ChatGPT 3.5 вышел в 2022 году. Подобные ошибки особенно опасны, поскольку модель излагает их с той же уверенностью, что и правдивую информацию.
Причина этого парадокса кроется в самой природе reinforcement learning, которое используется для обучения reasoning-моделей. Чтобы найти креативные решения, модель должна «галлюцинировать» – исследовать варианты, которых нет в обучающих данных. Но та же способность к творческому мышлению приводит к изобретению несуществующих фактов. Это создает фундаментальную дилемму: более «умные» модели могут быть менее надежными.
Влияние на потребление токенов
Использование Deep Think значительно увеличивает расход токенов, что напрямую влияет на стоимость использования ИИ и скорость работы.
Reasoning-токены – это скрытые токены, которые модель использует для внутренних рассуждений. Они не отображаются в финальном ответе, но учитываются при подсчете стоимости. Например, в случае с Claude Extended Thinking пользователь платит за все сгенерированные токены размышлений, даже если видит только краткую сводку.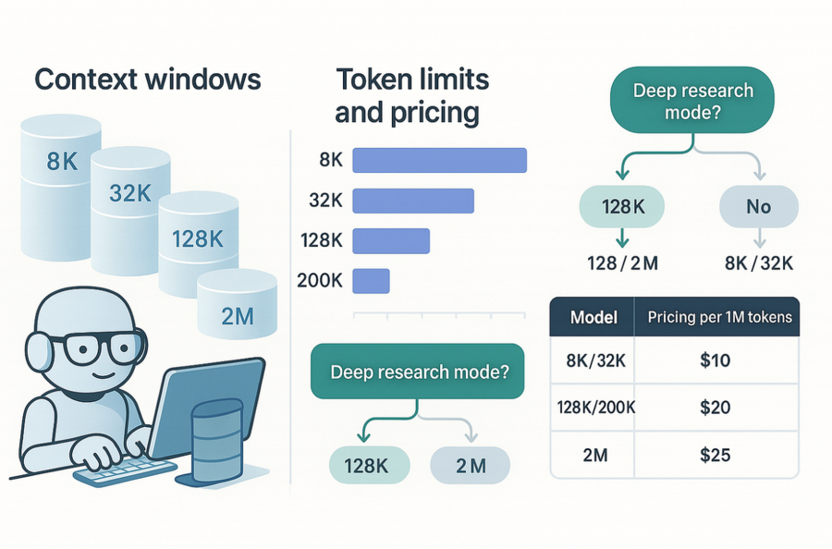
Использование Deep Think кардинально меняет экономику взаимодействия с ИИ:
- ChatGPT o1: использует в среднем в 3-5 раз больше токенов, чем GPT-4o.
- Claude Extended Thinking: может тратить до 128K токенов на размышления для одного ответа.
- DeepSeek R1: в новой версии 0528 использует в среднем 23K токенов на задачу против 12K в предыдущей версии.
- Grok Think: xAI не раскрывает детали потребления токенов, но время размышлений составляет от нескольких секунд до нескольких минут.
Для пользователей это означает, что лимиты сообщений будут исчерпываться быстрее, а API-запросы обойдутся дороже. При этом некоторые сервисы предлагают настройку «бюджета размышлений», позволяя контролировать баланс между качеством и стоимостью.
Обоснуй (Reason) в ChatGPT
OpenAI стала пионером в области reasoning-моделей, выпустив серию o1 в сентябре 2024 года. В 2025 году линейка расширилась моделями o3 и o4-mini, которые показывают довольно неплохие результаты в логических задачах.
Как работает Reason в ChatGPT
Модели серии o1 используют технику, называемую chain-of-thought reasoning (рассуждение по цепочке). Когда вы задаете сложный вопрос, модель разбивает задачу на более простые подзадачи, последовательно решает каждую часть и проверяет промежуточные результаты. При необходимости система возвращается назад и корректирует подход, после чего формулирует финальный ответ.
Этот процесс может занимать от нескольких секунд до нескольких минут. В интерфейсе ChatGPT вы видите индикатор «Думаю...», показывающий, что модель размышляет над задачей.
Сильные стороны:
-
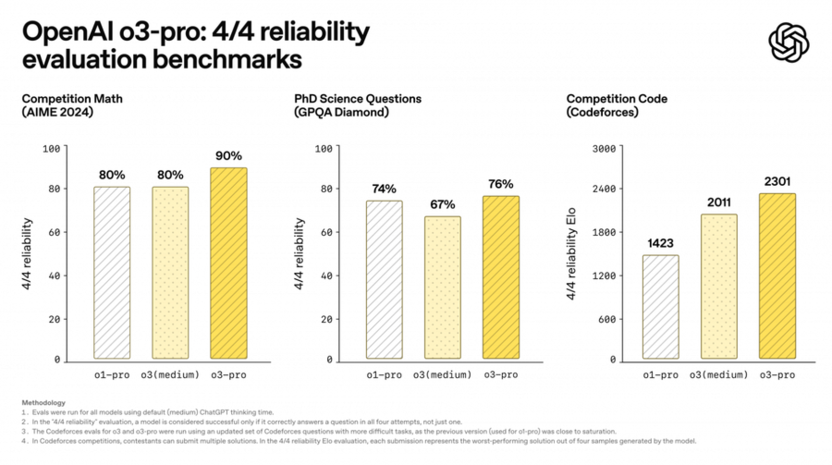
Превосходные результаты в математике: 93% на экзамене AIME 2024.
-
Высокая точность в научных задачах: сопоставима с уровнем PhD-студентов.
-
Отличное качество программирования: 79% точности на LiveCodeBench.
Ограничения:
-
Медленнее обычных моделей.
-
Более высокая стоимость использования.
-
Парадоксально больше галлюцинаций.
Эти особенности делают reasoning-модели мощным, но специализированным инструментом, требующим продуманного применения.
Стоит отметить, что Reasoning-модели доступны подписчикам ChatGPT Plus ($20/месяц) и ChatGPT Pro ($200/месяц). В рамках Pro-подписки доступен режим o1 pro mode с еще более мощными возможностями рассуждения.
Extended Thinking в Claude
Anthropic выбрала иную философию для своих reasoning-моделей. Claude 3.7 Sonnet, представленный в феврале 2025 года, стал первой «гибридной» моделью рассуждений, а в последующие месяцы появились еще более мощные Claude Opus 4 и Claude Sonnet 4, которые демонстрируют значительно улучшенные результаты на всех основных бенчмарках.
 В отличие от конкурентов, Claude не использует отдельную модель для рассуждений. Вместо этого та же модель может переключаться между быстрыми ответами и глубоким анализом. В веб-интерфейсе Claude.ai пользователи могут переключаться между режимами Normal и Extended thinking.
В отличие от конкурентов, Claude не использует отдельную модель для рассуждений. Вместо этого та же модель может переключаться между быстрыми ответами и глубоким анализом. В веб-интерфейсе Claude.ai пользователи могут переключаться между режимами Normal и Extended thinking.
Через API разработчики получают более точный контроль – они могут устанавливать «бюджет размышлений» (параметр budget_tokens), определяя лимит токенов для обдумывания конкретного запроса. Также доступна возможность видеть полный процесс рассуждений модели в прозрачном виде. Такой подход дает беспрецедентный контроль над балансом скорости, качества и стоимости.
Технические детали
Claude Extended Thinking использует так называемое «последовательное test-time compute» – модель задействует дополнительные вычислительные ресурсы во время ответа, а не только во время обучения. Интересно, что производительность модели улучшается логарифмически с увеличением количества «thinking tokens».
Ключевые параметры:
-
Максимальный бюджет размышлений: 128K токенов.
-
Контекстное окно: 200K токенов.
-
Цена: $3 за миллион входных токенов, $15 за миллион выходных (включая thinking-токены).
Такая ценовая модель означает, что пользователи платят за весь процесс рассуждения, даже если видят только итоговый результат.
Результаты тестирования Claude 4
Модели четвертого поколения показывают выдающиеся результаты во всех категориях тестирования. Claude Opus 4 демонстрирует 79.4% точности в программировании (SWE-bench Verified), 83.3% в задачах graduate-level reasoning (GPQA Diamond) и 90.0% в высокоуровневой математике (AIME 2025). Claude Sonnet 4, более эффективная модель, показывает сопоставимые результаты: 80.2% в программировании и 83.8% в научных задачах.
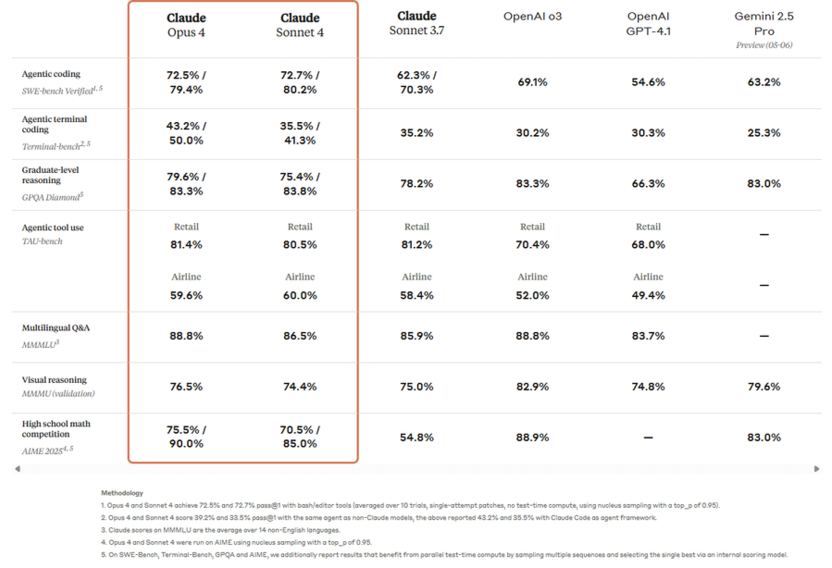
Особенно примечательна производительность в agentic задачах, где Claude 4 достигает 81.4% в retail сценариях и 59.6% в airline задачах по бенчмарку TAU-bench. Эти результаты делают Claude одним из лидеров среди reasoning-моделей.
Extended Thinking особенно полезен для анализа длинных документов и контрактов, написания сложного кода с множественными зависимостями, стратегического планирования и сценарного анализа, а также проверки логической согласованности аргументов.
Deep Think в DeepSeek
DeepSeek R1, выпущенный китайской компанией DeepSeek AI в январе 2025 года, произвел фурор в индустрии благодаря сочетанию высокой производительности и доступности. Это первая open-source reasoning-модель, способная конкурировать с закрытыми решениями от OpenAI и Anthropic.
DeepSeek R1 использует архитектуру Mixture-of-Experts (MoE) с 671 миллиардом параметров, но активирует только 37 миллиардов на каждый запрос. Это обеспечивает высокую эффективность при относительно низких вычислительных затратах.
Уникальные черты DeepSeek R1:
- Обучение чистым reinforcement learning без предварительной supervised fine-tuning.
- Прозрачный процесс рассуждений в тегах <think></think>.
- Возможность запуска на локальном оборудовании.
- Полностью открытый исходный код.
Эти особенности делают DeepSeek уникальным среди reasoning-моделей, предлагая прозрачность и доступность, недоступную у коммерческих конкурентов.
Производительность и стоимость
DeepSeek впечатляет соотношением цена/качество, демонстрируя, что мощные reasoning-модели можно создавать без миллиардных инвестиций:
- API стоимость: $0.0008 за 1K токенов (в 10+ раз дешевле ChatGPT).
- Математика: 79.8% на AIME 2024, 97.3% на MATH-500.
- Программирование: конкурентоспособные результаты на LiveCodeBench.
- Обучение: $5.5 миллионов против $100+ миллионов у конкурентов.
Такие показатели стали настоящим шоком для индустрии, доказав, что эффективность может превосходить бюджет.
Видимый процесс мышления
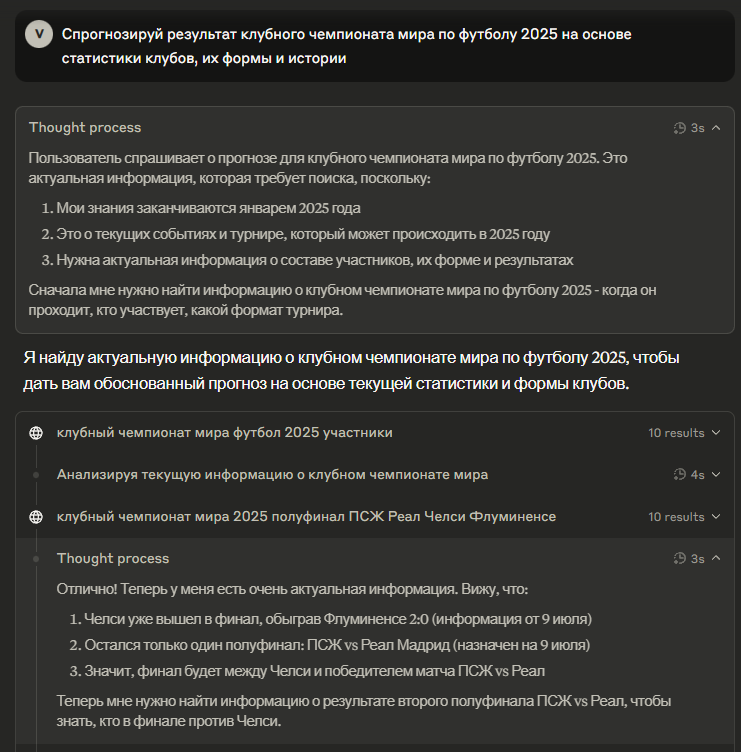
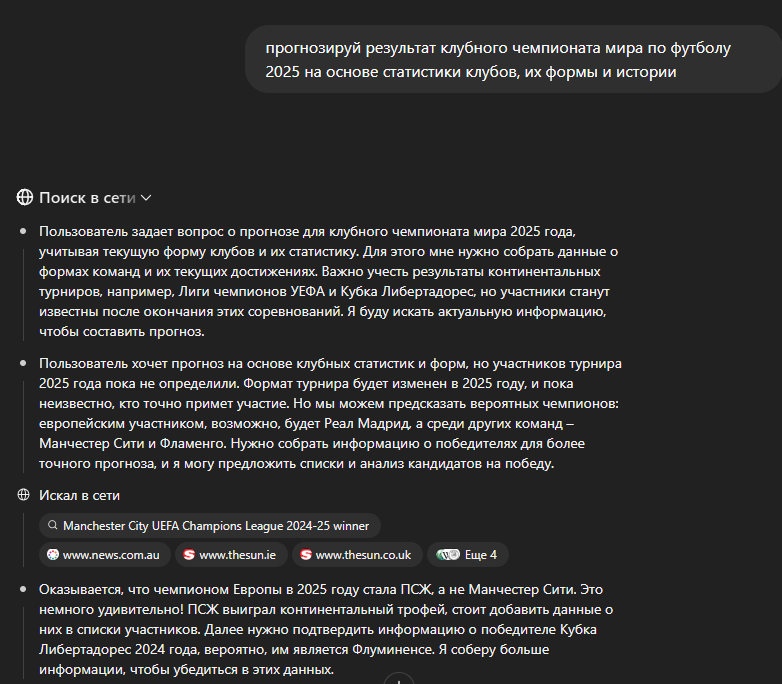
В отличие от ChatGPT, который минимизирует видимых для пользователя рассуждений, DeepSeek R1 показывает все этапы своего «мышления». Рассмотрим реальный пример того, как модель размышляет над спортивным прогнозом:
Запрос пользователя: «Спрогнозируй результат клубного чемпионата мира по футболу 2025 на основе статистики клубов, их формы и истории»
Фрагмент мышления DeepSeek:
Этот пример демонстрирует как сильные, так и слабые стороны прозрачного мышления. Однако стоит учитывать, что в данном случае довольно большую роль играет дополнительно включенная функция поиска в интернете, поскольку для корректного ответа может потребоваться свежая информация, которой не было в базе данных модели на момент ее выпуска.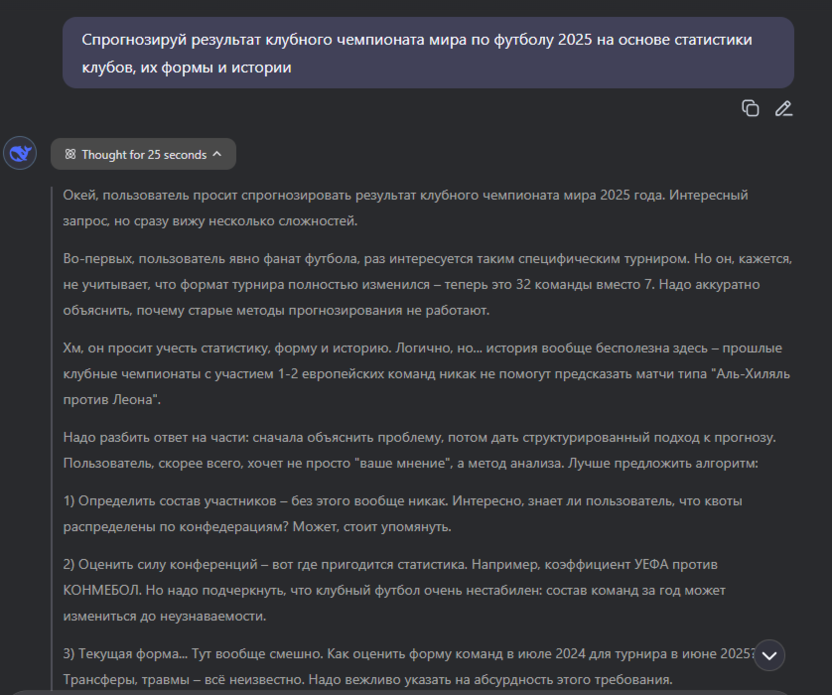
Преимущества видимого процесса. Можно наблюдать, как модель структурирует подход к сложной задаче, разбивая ее на логические компоненты. Видно, что система пытается анализировать мотивы пользователя и планирует, как лучше подать информацию. Прозрачность позволяет выявить слабые места в рассуждениях до получения финального ответа.
Риски и галлюцинации. Однако тот же пример показывает, как модель может «с уверенностью» утверждать неточные факты, а также додумывать, делая предварительные выводы, отталкиваясь от собственных предположений. Видимость внутренних сомнений («Хм», «Тут вообще смешно») может снижать доверие пользователей, даже когда итоговый ответ корректен. Вместе с этим модель демонстрирует антропоморфное поведение, пытаясь «угадать» намерения пользователя, что может приводить к неверным предположениям.
Прозрачность мышления DeepSeek создает уникальные возможности для понимания логики принятия решений, обучения на примере рассуждений ИИ, выявления потенциальных ошибок в логике и исследования когнитивных процессов ИИ. Однако пользователи должны критически относиться к процессу рассуждений, понимая, что красивая логика не гарантирует фактической точности.
Благодаря открытости и низкой стоимости, DeepSeek R1 особенно привлекателен для образовательных учреждений с ограниченными бюджетами, исследовательских проектов, требующих прозрачности, компаний, которым нужен контроль над ИИ-инфраструктурой, и разработчиков, создающих собственные ИИ-продукты.
Think в Grok: правдоискательские размышления
Grok 3 предлагает три специализированных режима мышления, каждый из которых оптимизирован для определенных типов задач.
- Think Mode представляет собой стандартное пошаговое рассуждение для образовательных и аналитических задач. Этот режим подходит для объяснения концепций и решения задач средней сложности, обеспечивая баланс между скоростью и качеством анализа.
- Big Brain Mode предназначен для самых сложных задач, использующий максимальные вычислительные ресурсы. Данный режим применяется для глубокого анализа и комплексных проблем, требующих extensive reasoning и многоуровневого планирования.
- DeepSearch функционирует как режим исследования, который сканирует интернет и платформу X для сбора актуальной информации по запросу. Это прямой аналог Deep Research от OpenAI, но с уникальной интеграцией социальных медиа.
Grok 3 обучался на суперкомпьютере Colossus с 200,000 GPU Nvidia H100, что представляет собой в 10 раз больше вычислительных мощностей по сравнению с Grok 2. Такая масштабная инфраструктура позволила достичь впечатляющих результатов: 93.3% точности на AIME 2025 и 84.6% на GPQA, что делает Grok 3 одной из самых мощных reasoning-моделей на рынке.
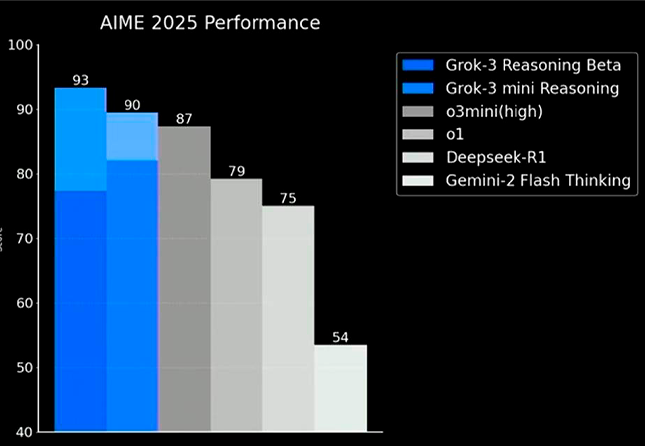
Модель стала первой, которая преодолела барьер в 1400 ELO баллов на Chatbot Arena, заняв первое место по предпочтениям пользователей. Интеграция с платформой X обеспечивает доступ к актуальной информации в реальном времени, что особенно ценно для анализа текущих событий и трендов.
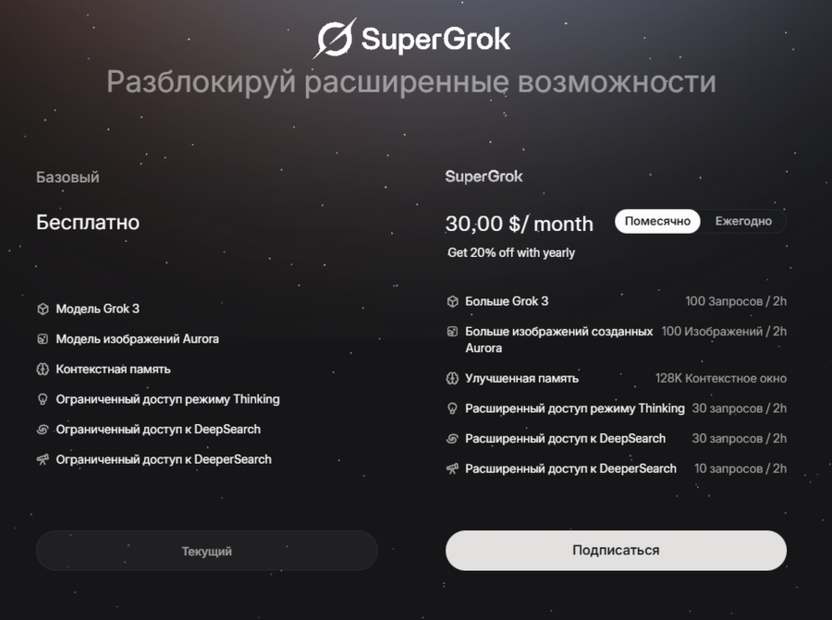
Grok 3 доступен пользователям X Premium+ ($50/месяц) с полным доступом ко всем режимам мышления. Также существует отдельная подписка SuperGrok ($30/месяц), которая предоставляет дополнительные возможности reasoning и DeepSearch запросов, плюс неограниченную генерацию изображений.
Gemini Deep Think
Google представил свою версию reasoning-моделей в рамках семейства Gemini 2.5, анонсированного в марте 2025 года. Deep Think mode для Gemini 2.5 Pro позиционируется как экспериментальная функция расширенного рассуждения, использующая новые исследовательские техники.
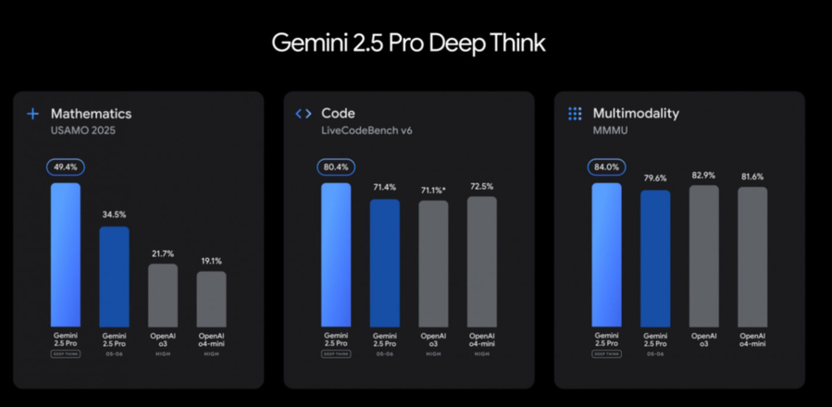
Gemini Deep Think отличается от конкурентов возможностью рассматривать несколько гипотез параллельно перед формулированием ответа. Этот подход имитирует процесс решения сложных проблем экспертами, которые тестируют альтернативные варианты прежде чем принять окончательное решение.
Модель показывает сильные результаты на бенчмарке USAMO 2025 – одном из самых сложных математических тестов, лидирует на LiveCodeBench для соревновательного программирования и достигает 84% на MMMU, тестирующем мультимодальное рассуждение.
Особенностью Gemini является возможность управления «бюджетом размышлений» – пользователи могут устанавливать, сколько токенов модель может потратить на обдумывание.
Когда стоит использовать Deep Think, а когда лучше обойтись
Выбор между обычными и reasoning-моделями – это не просто вопрос качества, а вопрос целесообразности. Deep Think требует больше времени и ресурсов, поэтому важно понимать, когда эти затраты оправданы. Ранее я говорил о технических различиях моделей, теперь остановимся на практических сценариях применения. Грубо говоря, если ошибка может стоить денег, репутации или безопасности – стоит потратить время на размышления. Если нужна быстрая помощь или творческое вдохновение, то обычные модели справятся лучше.
Deep Think оправдан при:
-
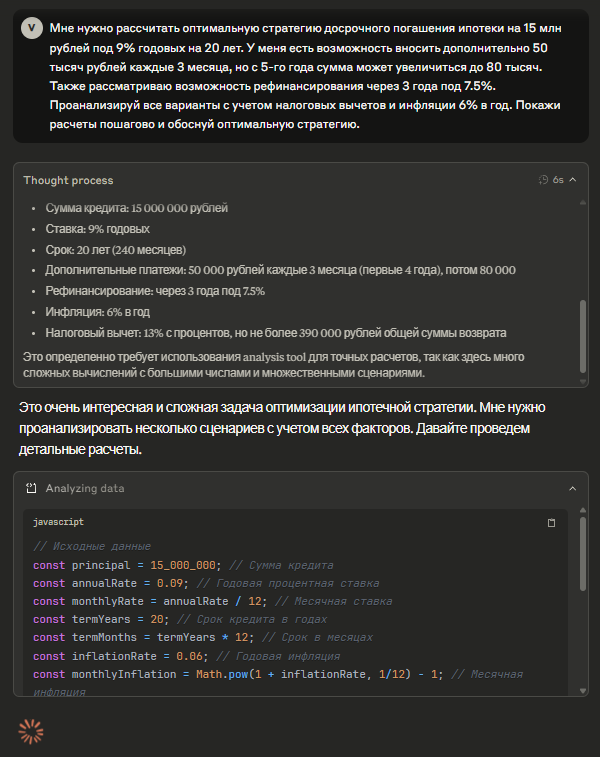
Решении математических задач повышенной сложности. Когда речь идет о многоступенчатых уравнениях, доказательствах теорем или финансовых расчетах, где каждый шаг влияет на результат. Например, при расчете сложных процентов по кредиту, анализе статистических данных для научной работы или проверке математических моделей в инженерных проектах. Обычные модели часто «срезают углы» в вычислениях, а reasoning-модели методично проверяют каждый этап.
-
Написании критически важного кода. Особенно когда разрабатываете системы безопасности, финансовые алгоритмы или медицинское ПО, где ошибка может иметь серьезные последствия. Deep Think помогает выявить потенциальные уязвимости, проанализировать граничные случаи и предусмотреть обработку исключений. Также полезен при рефакторинге legacy-кода или интеграции сложных API.
-
Анализе юридических документов. При изучении контрактов, патентов, судебных решений или нормативных актов, где важно не пропустить скрытые условия или противоречия. Reasoning-модели лучше отслеживают логические связи между разными частями документа и могут выявить потенциальные правовые риски, которые не очевидны при поверхностном чтении.
-
Стратегическом планировании. Когда разрабатываете бизнес-стратегию, анализируете инвестиционные возможности или планируете сложные проекты с множественными зависимостями. Deep Think помогает учесть взаимосвязи между факторами, оценить риски и выстроить логическую последовательность действий.
-
Научных исследованиях. При формулировании гипотез, анализе экспериментальных данных, peer-review статей или проектировании исследований. Reasoning-модели помогают выявить логические пробелы в рассуждениях, предложить альтернативные объяснения результатов и проверить методологическую корректность подходов.
Обычные модели предпочтительны для:
-
Творческих задач. Написание рассказов, генерация идей для маркетинговых кампаний, создание сценариев или разработка концепций дизайна. Здесь важнее спонтанность и креативность, а не логическая строгость. Reasoning-модели могут «зациклиться» на поиске «правильного» ответа там, где нужна просто интересная идея.

-
Быстрой генерации контента. Когда нужно написать email, создать описание товара, подготовить пост в социальных сетях или сделать краткий пересказ. В таких случаях скорость важнее совершенства, а дополнительные размышления не добавляют ценности к результату.
-
Простых вопросов и ответов. Объяснение базовых концепций, перевод текстов, поиск фактической информации или помощь в изучении языков. Здесь reasoning может даже навредить, усложнив простые ответы и добавив ненужные детали.
-
Повседневного общения. Повседневные беседы, обсуждение хобби, получение рекомендаций по фильмам или ресторанам, планирование досуга. В таких сценариях естественность диалога важнее аналитической глубины.
-
Задач, где скорость важнее точности. Мозговые штурмы, первичная обработка больших объемов информации, создание черновиков или быстрое прототипирование идей. Иногда лучше получить 10 приблизительно правильных вариантов за минуту, чем один идеальный за десять.
Заключение
2025 год стал переломным в развитии ИИ-технологий. Функции Deep Think превратили нейросети из продвинутых автозаполнителей в системы, способные к настоящему анализу и рассуждению. Каждая крупная компания предложила свой подход: OpenAI сделал ставку на скрытые размышления, Anthropic – на гибридность и прозрачность, DeepSeek открыл код для всех, а xAI интегрировал социальные медиа.
Парадокс галлюцинаций показывает, что путь к «умному» ИИ не линеен. Более мощные модели могут быть менее надежными в некоторых аспектах, что требует нового подхода к валидации и проверке результатов. Пользователям важно понимать ограничения каждой модели и выбирать подходящий инструмент для конкретной задачи.
Стоимость использования reasoning-моделей пока остается высокой, но тенденция к снижению цен уже заметна. DeepSeek показал, что качественные модели можно создавать с меньшими затратами, что неизбежно повлияет на ценообразование конкурентов.






Комментарии