



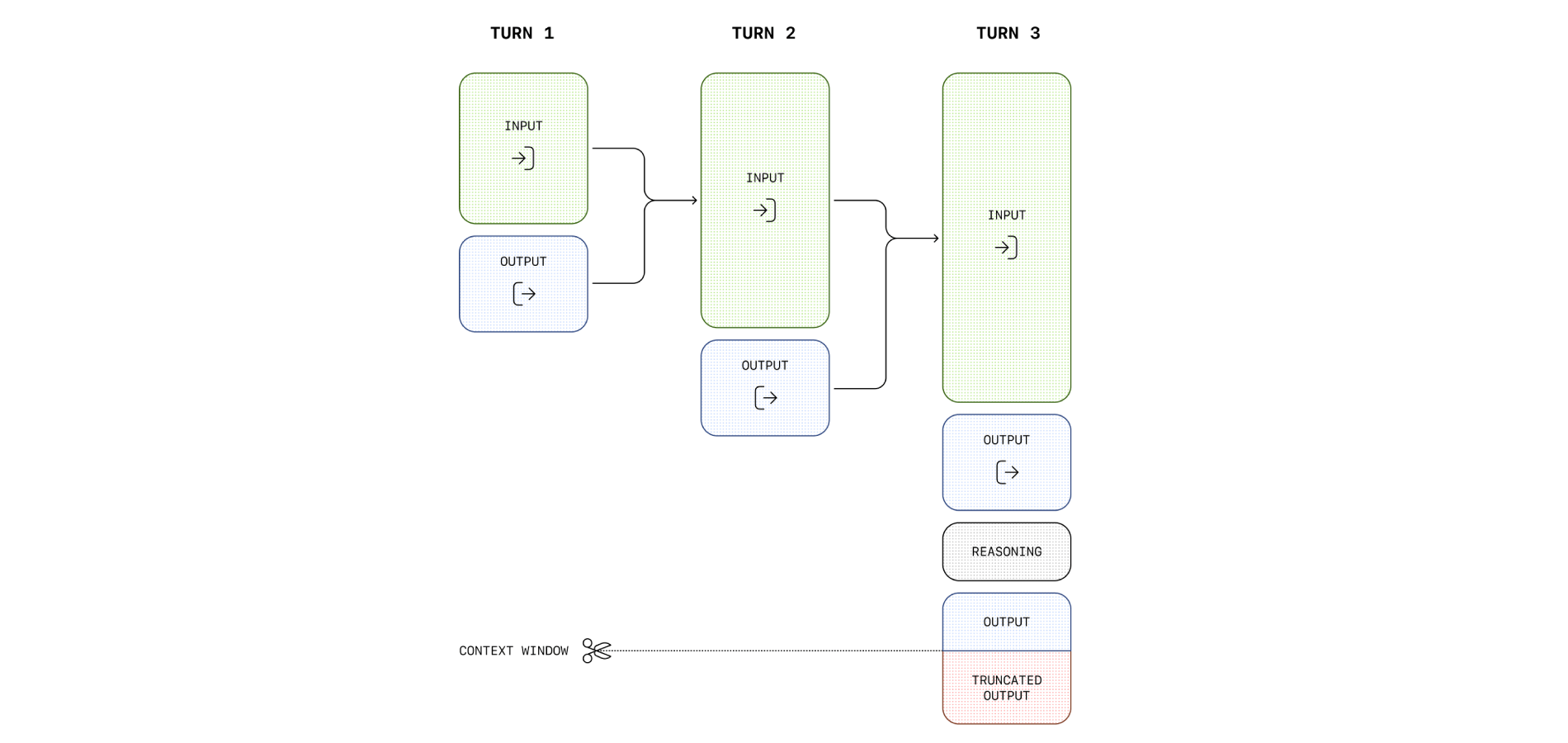
Еще несколько лет назад нейросети отвечали на запросы практически мгновенно. Быстро – значит хорошо, казалось бы. Но именно в этой скорости и крылась главная проблема: модель не «думала» над ответом, а строила его по вероятности следующего слова. Сложные задачи давались ей плохо, и никакое увеличение размера модели не решало вопрос кардинально.
В 2024-2025 годах появился другой подход – reasoning-модели, которые перед ответом сначала разворачивают внутреннее рассуждение. Теперь это отдельный класс систем, и в марте 2026 года такие модели есть у всех крупных разработчиков.
В чем проблема обычного чат-бота
Стандартная языковая модель – это предсказатель следующего токена. Она обучается на огромных массивах текста и учится строить правдоподобные продолжения. Это работает отлично для большинства задач: ответить на вопрос, написать письмо, объяснить концепцию. Но когда задача требует последовательного рассуждения (решить задачу по алгебре в несколько шагов, разобрать юридический документ с перекрестными ссылками, найти баг в многофайловом проекте), модель начинает давать сбои.
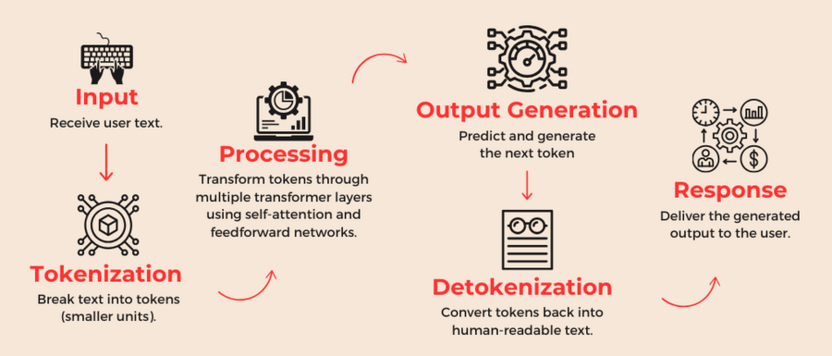
Причина технически понятна: каждый токен генерируется на основе фиксированного числа вычислительных слоев трансформера. Сколько бы текста ни стояло перед ответом, глубина обработки не меняется. Поэтому обычная модель нередко «прыгает» к ответу через несколько шагов там, где нужны десятки, и делает это уверенно – даже если где-то посередине ошиблась.
Reasoning-модели решают эту проблему иначе: они генерируют большой блок внутренних «мыслей» до того, как сформировать финальный ответ. Этот блок – не просто дополнительный текст, а полноценное пространство для рассуждения: проверки гипотез, возврата назад, пересмотра промежуточных выводов.
Как это работает внутри
Ключевое понятие здесь – chain of thought, или цепочка рассуждений. Изначально это была просто техника промтинга: дописать к запросу «думай шаг за шагом» – и обычная модель начинала выдавать более точные результаты. Reasoning-модели обучены делать это автоматически, причем значительно глубже, через отдельный механизм тренировки.
Такие модели обучаются с применением reinforcement learning – обучения с подкреплением. Модель пробует разные пути рассуждения, получает обратную связь о качестве результата и постепенно учится находить более эффективные стратегии решения задач. В итоге в ходе тренировки модель осваивает несколько конкретных навыков:
- проверять промежуточные выводы, не принимая их сразу за окончательные;
- возвращаться назад, если текущий путь рассуждения заходит в тупик;
- пробовать альтернативный подход, когда первый не срабатывает.
Это принципиально отличается от обычного дообучения на правильных ответах.
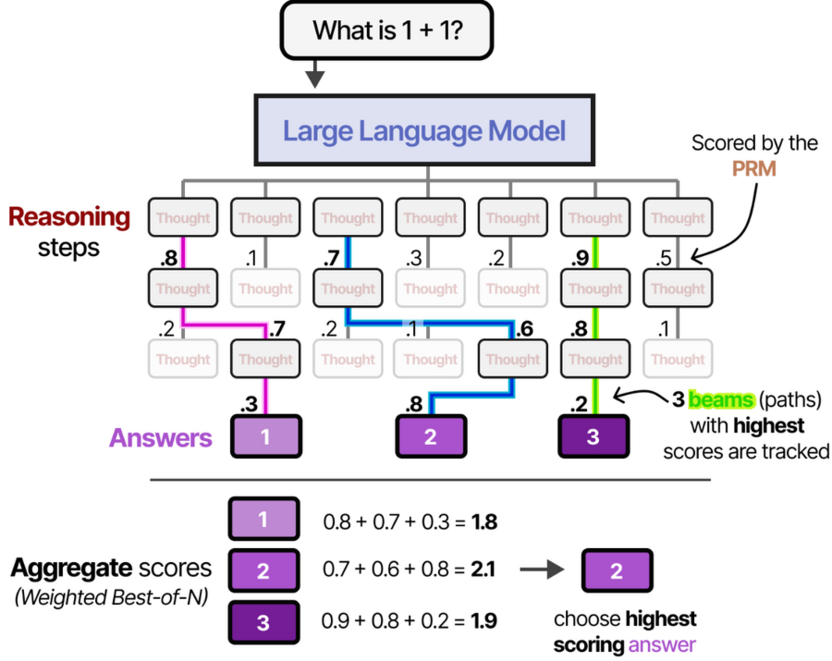
Второй важный момент касается так называемых thinking tokens, или токенов размышления. Они потребляют вычислительные ресурсы точно так же, как и финальный ответ, но служат внутренним черновиком. Именно здесь и происходит реальная работа: модель может потратить на рассуждение в десятки раз больше токенов, чем займет итоговый ответ, и за счет этого существенно точнее решить задачу.

Из этого следует важный практический вывод: reasoning-модели медленнее и дороже стандартных. Это осознанный компромисс. Там, где важна скорость и задача несложная, они избыточны. Там, где нужна точность на многошаговых проблемах, они выигрывают.
Основные reasoning-модели в 2026 году
Сегодня reasoning-возможности есть у всех ключевых игроков рынка, но реализованы они по-разному. Одни разработчики сделали из reasoning отдельную линейку моделей, другие встроили его как опциональный режим в уже существующие системы. Есть и открытые решения, которые можно развернуть локально. Ниже – разбор четырех наиболее значимых вариантов с учетом их архитектурных различий и доступности на март 2026 года.
OpenAI o-серия
Первой публично анонсированной reasoning-моделью стала OpenAI o1, вышедшая в сентябре 2024 года. Она задала стандарт: модель тратит время на внутренние рассуждения, пользователь видит только краткое резюме этого процесса – полная цепочка мыслей не раскрывается. По заявлению OpenAI, это сделано осознанно: необработанное рассуждение может содержать промежуточные шаги, которые не стоит показывать напрямую.
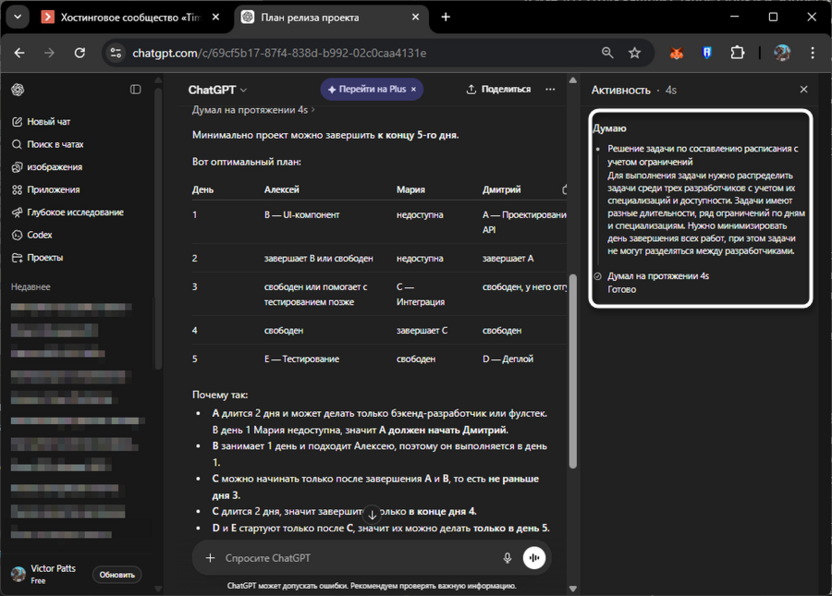
Сейчас актуальна o3: она доступна пользователям Plus и Pro в ChatGPT. Контекстное окно составляет 200 000 токенов, модель умеет работать с изображениями прямо в ходе рассуждения. Позднее в 2025 году OpenAI выпустила o4-mini – облегченную версию с акцентом на скорость и экономичность при сопоставимом качестве рассуждений.
Claude с Extended Thinking
Anthropic пошла другим путем. В феврале 2025 года вышел Claude 3.7 Sonnet – первая в отрасли гибридная reasoning-модель. Ее ключевая особенность: это не отдельная специализированная модель, а та же система с переключаемым режимом. В стандартном режиме она работает как обычный чат-бот, в режиме Extended Thinking – разворачивает полноценное рассуждение, причем пользователь может видеть его в сыром виде.
В мае 2025 года вышли Claude Opus 4 и Sonnet 4 – они сохранили режим расширенного мышления, но показывают уже сокращенную версию рассуждения, не полную цепочку. В феврале 2026-го Anthropic выпустила Claude Opus 4.6 с так называемым adaptive thinking – модель сама решает, когда ей нужно думать дольше, в зависимости от сложности задачи. Разработчики через API могут задать «бюджет токенов» для размышления, напрямую регулируя соотношение скорости и глубины ответа.
Принципиальная позиция Anthropic, зафиксированная в официальном блоге: reasoning должен быть интегрированной способностью модели, а не отдельным специализированным продуктом.
Gemini с Deep Think
Google представила Gemini 2.5 Pro в середине 2025 года – свою «мыслящую модель» с явным режимом Deep Think. Главное преимущество, которое выделяет Gemini среди конкурентов, – контекстное окно в 1 миллион токенов.
Это может подойти для задач, где нужно проанализировать очень большой объем информации: многостраничные кодовые базы, обширные юридические документы, длинные технические отчеты. Другие reasoning-модели на такой масштаб не рассчитаны: у Claude и o3 контекстное окно составляет 200 000 токенов.
DeepSeek R1
Отдельного упоминания заслуживает DeepSeek R1, вышедший в январе 2025 года под лицензией MIT. Это первая крупная открытая reasoning-модель: полные веса доступны публично, ее можно развернуть локально, доработать или использовать для обучения других моделей. Китайская компания DeepSeek обучила R1 преимущественно через reinforcement learning – без масштабного этапа supervised fine-tuning, что само по себе стало научным результатом. В мае 2025 года вышло обновление R1-0528 с улучшенным качеством рассуждений и поддержкой function calling.
Принципиальное отличие от o-серии: DeepSeek R1 показывает внутреннее рассуждение полностью – оно оборачивается в теги <think> и видно пользователю. В декабре 2025 года DeepSeek перевела API-модели на V3.2, которая совмещает режим рассуждений с быстрым режимом в одной системе.
Когда reasoning-модели реально помогают
Разберем несколько конкретных сценариев, где переход от стандартной модели к reasoning-модели дает заметный результат.
- Математика и точные вычисления. OpenAI приводит в документации реальный пример из финансовой аналитики: расчет взаимозависимых долей при конвертации в венчурном раунде – задача с круговой зависимостью, которую топ-аналитики решают за 20-30 минут. O1 и o3-mini справляются с этим корректно, тогда как предыдущие модели не могли. Более простой пример: квалификационный экзамен на Международную олимпиаду по математике. GPT-4 в свое время решал 13% таких задач, o1 в момент выхода – 83%.
- Отладка сложного кода. Reasoning-модели умеют пройти по логике программы поэтапно, отслеживая состояние переменных и вызовы функций через несколько уровней вложенности. Это задача, где «прыжок» к ответу почти никогда не работает. Пользователи Claude с Extended Thinking регулярно отмечают, что модель в режиме мышления сначала перечисляет возможные причины бага, проверяет каждую и только потом предлагает исправление, в отличие от стандартного режима, где ответ приходит немедленно, но нередко мимо.
- Анализ юридических и финансовых документов. По данным из документации OpenAI API, компания Hebbia, работающая с кредитными соглашениями, зафиксировала, что o1 стабильно лучше справляется со сложными многостраничными договорами: умеет выделять перекрестные условия и делать выводы, не лежащие на поверхности в отдельном разделе. Это задача, где важна системность и нельзя упустить связь между разными частями документа.
- Планирование многошаговых решений. Reasoning-модели хорошо проявляют себя там, где нужно сначала составить план, а потом его реализовать. Например: «Спроектируй структуру директорий и напиши код Python-приложения, которое хранит пары вопрос-ответ и отвечает на похожие запросы». Обычная модель либо сразу генерирует код без продуманной структуры, либо предлагает структуру, которая потом плохо вяжется с кодом. Reasoning-модель сначала выстраивает архитектуру, проверяет ее логику, и только потом переходит к реализации.
Когда reasoning-модели избыточны
Это важный момент, который часто упускают. OpenAI в документации прямо указывает: если для задачи нужна работа с изображениями, быстрые ответы или вызов функций, то GPT-4o подходит лучше, чем o-серия. Добавить к запросу «думай шаг за шагом» в reasoning-модели бессмысленно – она и так это делает по умолчанию.
Собственная оценка OpenAI из блога о запуске o1: при тестировании живыми пользователями o1-preview проигрывал GPT-4o по предпочтениям в задачах на естественный язык. Reasoning-модель не подходит лучше для всего подряд – она подходит лучше именно там, где нужна глубина многошагового рассуждения.
Практически: не стоит тратить токены рассуждения на простые фактические вопросы, резюме текстов, написание коротких писем или быстрый поиск информации. Для этого стандартная модель быстрее и дешевле.
Ограничения
Reasoning-модели не лишены недостатков, и их стоит знать заранее, чтобы выбирать инструмент осознанно, а не разочаровываться в нем.
- Скорость и стоимость. Thinking-токены потребляют ресурсы точно так же, как токены финального ответа, и тарифицируются наравне с ними. При работе через API нужно учитывать, что на сложные запросы модель может потратить тысячи токенов на рассуждение – это прямо влияет на стоимость и время ответа.
- Достоверность цепочки мыслей. Anthropic в системной карточке Claude 3.7 честно признает: цепочка рассуждений не является полным и точным отражением внутренней логики модели. Это полезный и информативный артефакт, но не буквальная «запись мыслей». Поэтому ориентироваться на видимое рассуждение как на окончательное объяснение решения – не вполне корректно.
- Избыточное мышление. На тривиальных запросах reasoning-модель иногда тратит значительный токен-бюджет на самоочевидные шаги. Именно поэтому Anthropic в Claude Opus 4.6 реализовала adaptive thinking – модель сама оценивает, насколько глубокое рассуждение нужно в конкретном случае.
- Открытые модели и риски данных. DeepSeek R1 – мощный инструмент и единственная крупная открытая reasoning-модель на рынке. Вместе с тем серверы DeepSeek находятся в Китае, что создает риски для чувствительных корпоративных данных. Для таких задач разумнее развертывать модель локально – такая возможность есть благодаря открытому коду и весам.
Заключение
Reasoning-модели – это не «умнее, чем ChatGPT», а точнее «медленнее, но значительно лучше на задачах, где важна последовательность и проверка промежуточных шагов». В марте 2026 года такие модели есть у всех крупных игроков: o3 от OpenAI, Extended Thinking в Claude, Deep Think в Gemini, открытый DeepSeek R1.
Они используют разные подходы к прозрачности рассуждений и разные механизмы управления глубиной мышления, но принцип один – больше вычислений во время ответа дают лучший результат на по-настоящему сложных задачах. Поэтому выбор между обычной и reasoning-моделью – это в первую очередь вопрос о том, насколько многошаговой является задача, а не о том, какая модель лучше в абстракции.
Изображение на обложке: OpenAI






Комментарии