


Моя лента
Новое
Популярное

165
Microsoft добавила в PowerPoint функцию для редактирования изображений
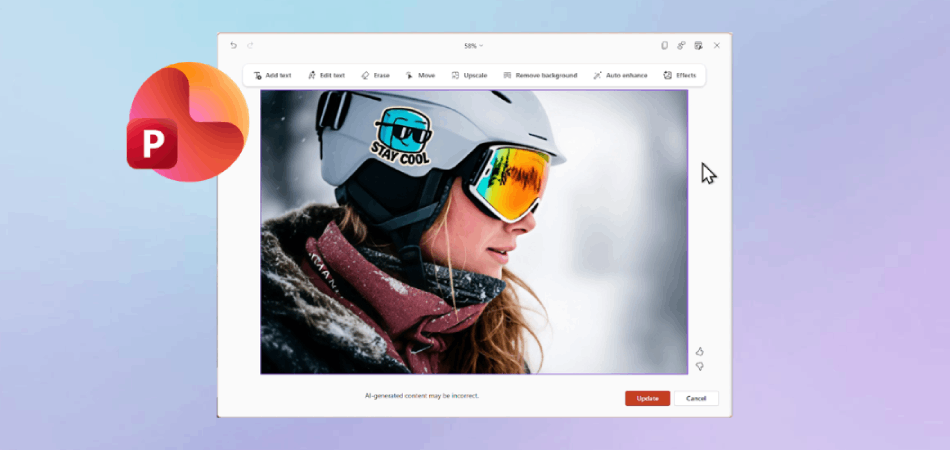
Microsoft добавила встроенный редактор изображений в приложении PowerPoint. В блоге компания рассказала, что с помощью редактора можно упростить обработку изображений в презентацией, не прибегая при этом к сторонним приложениям.

141
Конструктор для создания чат‑бота в MAX: от идеи до запуска

Платформа MAX позволяет создать такого цифрового помощника без навыков программирования – достаточно воспользоваться встроенным конструктором. Разберём пошагово, как это сделать.
232
Adobe добавила AI-ассистента в Photoshop – редактировать фото теперь можно текстом

Adobe открыла публичную бета-версию AI Assistant для Photoshop. Инструмент доступен в веб-версии редактора и мобильных приложениях всем пользователям, он позволяет редактировать изображения с помощью текстовых запросов. В мобильной версии команды можно отдавать голосом.

175
Использование Obsidian для личной базы знаний и заметок

Большинство людей хранят заметки хаотично: часть в телефоне, часть в браузерных закладках, часть в случайных документах. Через несколько месяцев найти нужную мысль уже почти невозможно. Obsidian решает именно эту проблему – он создан для того, чтобы строить личную базу знаний.

128
Корпоративная психотерапия сотрудников. Тренд или маркетинговый пузырь?

Рынок корпоративных программ психологической поддержки (EAP) переживает бум. Однако за фасадом успешных сделок скрывается системный сбой: агрегаторы продают бизнесу не решение проблем, а маркетинговые иллюзии.
Вакансии в Timeweb
PHP Developer (middle)
🏰 Санкт-Петербург 💷 Зарплата: от 150 000 руб. на руки 💪 Опыт: 3-6 лет 💼 Полная занятость, можно удаленно
Python Developer
🏰 Санкт-Петербург 💷 Зарплата: обсуждается 💪 Опыт: 3-6 лет 💼 Полная занятость, гибридный формат работы
Product Owner / Менеджер продукта MyReviews
🏰 Санкт-Петербург 💷 Зарплата: обсуждается 💪 Опыт: 1-3 года 💼 Полная занятость, гибридный формат работы
Lead / Senior JavaScript developer
🏰 Санкт-Петербург 💷 Зарплата: обсуждается 💪 Опыт: 3-6 лет 💼 Полная занятость