




При работе с большими массивами данных часто возникает необходимость в автоматизированной обработке текстовой информации. Ручное редактирование в таких случаях не только отнимает много времени, но и чревато ошибками. Функция REGEXREPLACE в Google Таблицах предоставляет необходимые возможности для решения подобных задач с использованием регулярных выражений.
В этой статье я детально разберу все возможности этой функции, начиная с базовых примеров и постепенно переходя к более сложным сценариям использования.
Таблица для примеров
Прежде чем приступить к изучению функции REGEXREPLACE, давайте создадим набор тестовых данных, который поможет нам наглядно продемонстрировать различные аспекты работы с регулярными выражениями. Я подобрал примеры, с которыми чаще всего приходится работать в реальных проектах: телефонные номера, электронные адреса, даты и денежные значения. Каждый из этих типов данных имеет свои особенности форматирования и требует индивидуального подхода при обработке.
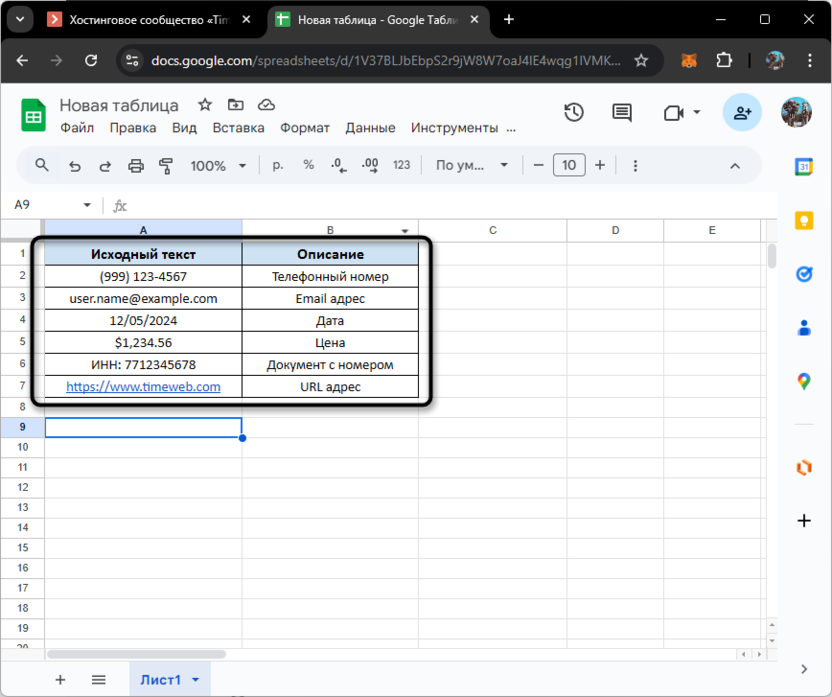
Если вас интересует конкретный тип данных, можете сразу перейти к разделу, соответствующему вашей задаче. Там вы найдете нужную формулу, а также детальное объяснение ее составляющих, чтобы было понимание, какие регулярные выражения (скрипты редактирования текста) использовались и как они повлияли на отображение нового результата.
Пример 1: Базовая замена текста
Сейчас телефонные номера все еще остаются одним из основных способов связи, и их корректное хранение в базах данных имеет критическое значение. Однако пользователи часто вводят номера в самых разных форматах: кто-то использует скобки для кода города, кто-то разделяет группы цифр дефисами, пробелами или точками. Более того, иногда в номера случайно попадают посторонние символы при копировании из различных источников. Чтобы эффективно работать с такими данными, первым делом нужно научиться приводить их к единому формату, очищая от всех нецифровых символов. В этом поможет рассматриваемая функция REGEXREPLACE в формуле, представленной ниже.
=REGEXREPLACE(A2; "[^0-9]"; "")
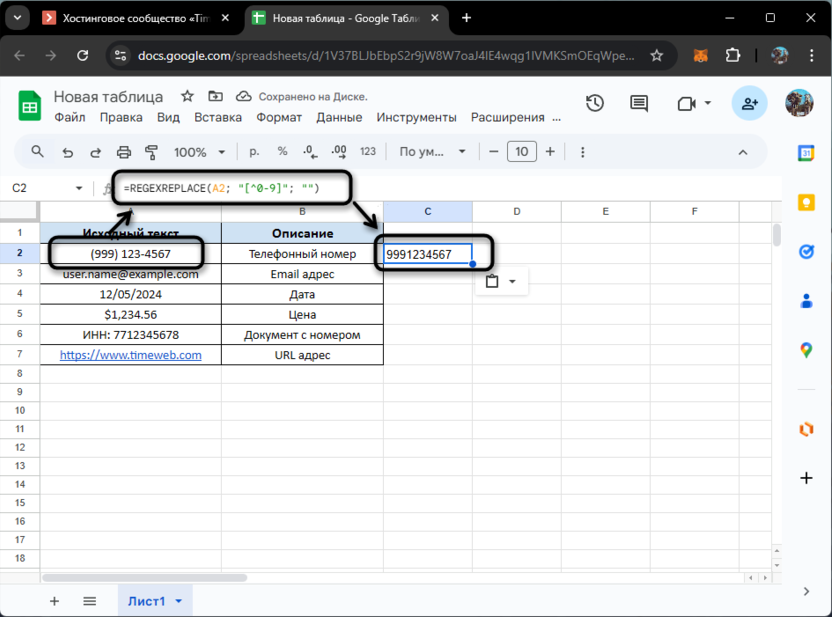
В данной формуле мы используем один из базовых, но мощных приемов работы с регулярными выражениями – инвертированный класс символов. Квадратные скобки с символом «^» определяют набор символов, которые мы хотим найти и заменить. В нашем случае [^0-9] означает «любой символ, который не является цифрой от 0 до 9». Такой паттерн позволяет одним действием избавиться от всех скобок, дефисов, пробелов и любых других нецифровых символов, которые могут присутствовать в номере телефона. Второй параметр функции – пустая строка – указывает, что все найденные символы должны быть просто удалены.
Пример 2: Форматирование телефонных номеров
После того как мы научились очищать телефонные номера от лишних символов, следующим логичным шагом становится их форматирование в соответствии с определенным стандартом. В России принято записывать мобильные номера в формате "+7 (XXX) XXX-XXXX". Такое написание не только делает номера более читаемыми, но и помогает визуально выделять код оператора и группы цифр. Для решения этой задачи мы можем использовать более сложную конструкцию, комбинирующую две функции REGEXREPLACE.
=REGEXREPLACE(REGEXREPLACE(A2; "[^0-9]"; ""); "(\d{3})(\d{3})(\d{4})"; "+7 ($1) $2-$3")
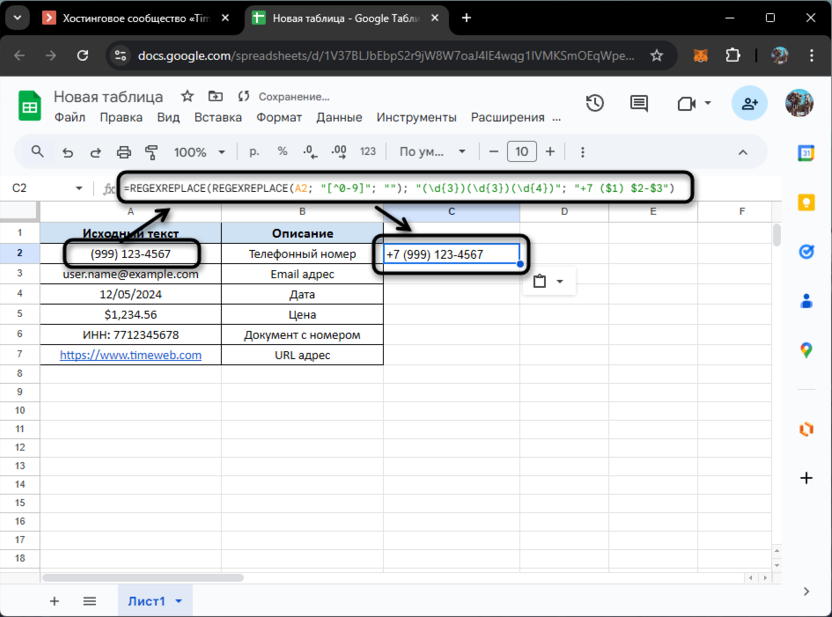
Данная формула представляет собой двухэтапный процесс преобразования. На первом этапе, как мы уже разобрали выше, происходит очистка номера от всех нецифровых символов. Затем очищенный номер обрабатывается второй функцией REGEXREPLACE, которая использует технику захватывающих групп.
Паттерн "(\d{3})(\d{3})(\d{4})" разбивает последовательность цифр на три группы: первые три цифры для кода оператора, следующие три для первой части номера и последние четыре для второй части. Круглые скобки в регулярном выражении создают так называемые карманы, к которым мы можем обратиться в строке замены через специальные переменные $1, $2 и $3 соответственно.
Пример 3: Работа с email-адресами
При работе с базами данных клиентов или сотрудников часто возникает необходимость в извлечении определенных частей email-адресов, например, доменного имени. Это может быть полезно для различных аналитических задач: определения корпоративных клиентов, группировки пользователей по почтовым сервисам или проверки корректности адресов. В этом примере я рассмотрю, как с помощью REGEXREPLACE можно довольно просто извлечь доменную часть из email-адреса.
=REGEXREPLACE(A3; ".*@"; "")
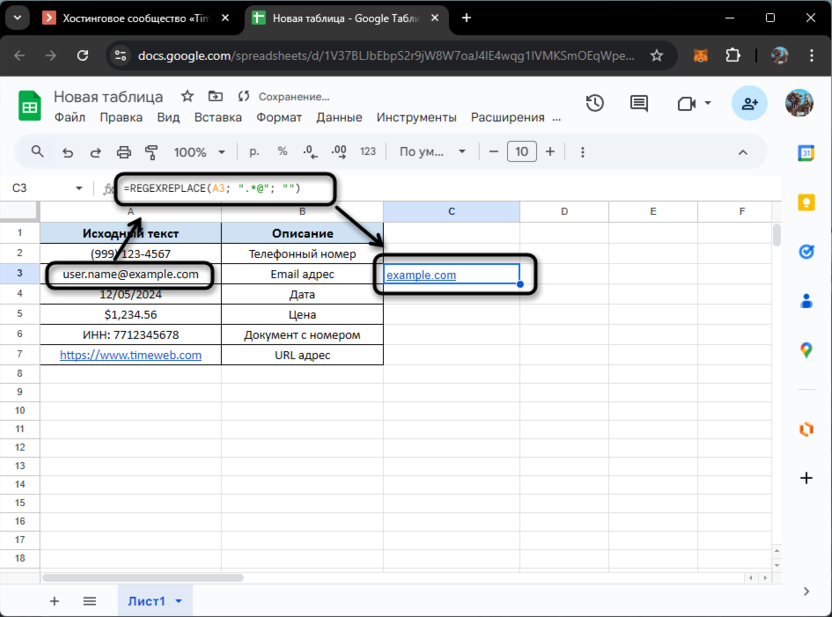
В этой формуле мы используем одну из самых мощных концепций регулярных выражений – жадный поиск. Точка с звездочкой (.*) означает «любая последовательность любых символов», а символ @ служит якорем, определяющим конец захватываемой части.
Таким образом, формула находит все символы от начала строки до знака @ включительно и заменяет их пустой строкой, оставляя только доменную часть адреса. Эта техника особенно примечательна тем, что не требует сложных проверок или множества условий – она просто работает для любых корректно составленных email-адресов.
Пример 4: Преобразование формата даты
Работа с датами в таблицах часто становится настоящим испытанием для аналитиков, особенно когда приходится иметь дело с данными из разных источников. Различные страны и организации используют разные форматы дат: американский формат MM/DD/YYYY, европейский DD/MM/YYYY или стандарт ISO YYYY-MM-DD.
При объединении данных или подготовке отчетности часто возникает необходимость привести все даты к единому формату. REGEXREPLACE предоставляет удобное решение этой задачи, позволяя не только изменить порядок компонентов даты, но и заменить разделители.
=REGEXREPLACE(A4; "(\d{2})/(\d{2})/(\d{4})"; "$3-$2-$1")
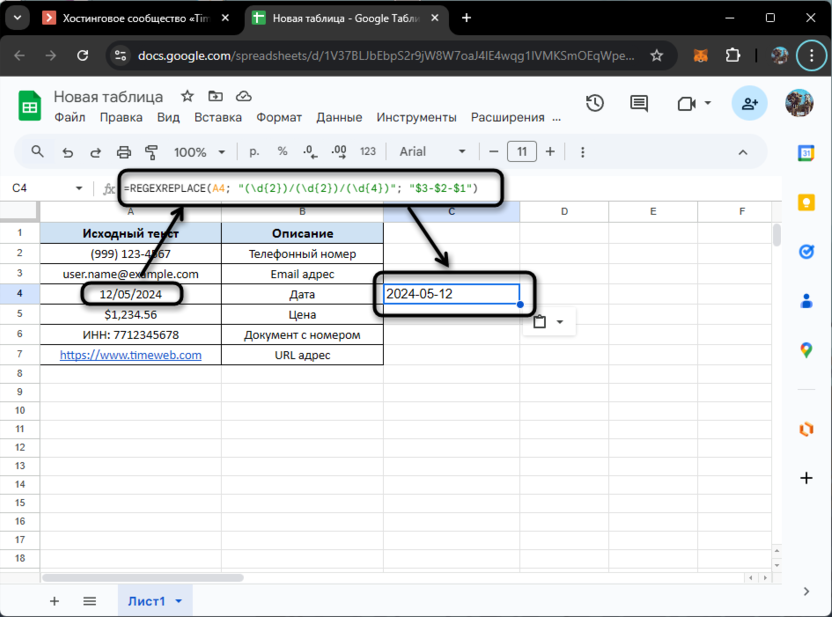
Обратите внимание на то, что функция сработает только в том случае, если формат ячейки указан как текстовый, поскольку именно с текстом и происходит взаимодействие. Если формат отличается, появится уведомление об ошибке. При возникновении таковой в 99% случаев речь идет как раз о неправильно выбранном формате, поэтому вручную проверьте его и поменяйте на текстовый.
Теперь разберем непосредственно алгоритм действий. В данном случае мы используем более сложную технику захватывания групп символов. Каждая группа цифр в исходной дате заключается в круглые скобки, создавая отдельные карманы: (\d{2}) захватывает ровно две цифры для дня и месяца, а (\d{4}) – четыре цифры года. Слеши между группами цифр соответствуют буквальным символам в исходной строке.
В строке замены мы используем ссылки на эти карманы ($1, $2, $3), но располагаем их в нужном нам порядке, добавляя между ними дефисы в качестве разделителей. Таким образом, мы не только меняем формат даты, но и обеспечиваем единообразие разделителей во всем массиве данных.
Пример 5: Извлечение чисел из текста
При работе с финансовыми данными часто возникает необходимость очистки числовых значений от различных форматирующих символов: знаков валют, разделителей групп разрядов, лишних пробелов. Особенно актуальной эта задача становится при импорте данных из разных источников, где могут использоваться различные форматы представления чисел, что мешает дальнейшему применению значений в различных формулах. REGEXREPLACE прекрасно справляется с решением этой проблемы, очищая числа от всех нецифровых символов, кроме десятичного разделителя. Нужна формула будет иметь следующий вид:
=REGEXREPLACE(A5; "[^\d\.]"; "")
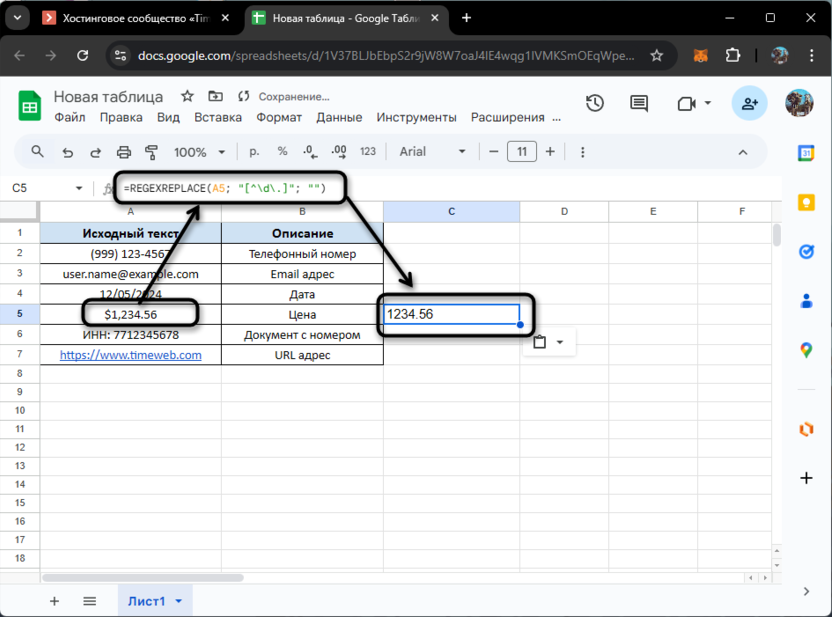
Данная формула использует технику инвертированного класса символов, похожую на ту, что мы рассматривали в первом примере, но с важным дополнением. Внутри квадратных скобок мы добавляем точку как разрешенный символ (.), загораживая ее обратным слешем, чтобы она воспринималась буквально, а не как специальный символ регулярных выражений. Таким образом, формула сохраняет все цифры и десятичные точки, удаляя все остальные символы. Это особенно полезно при работе с ценами, где могут присутствовать символы валют, разделители тысяч и другие форматирующие элементы.
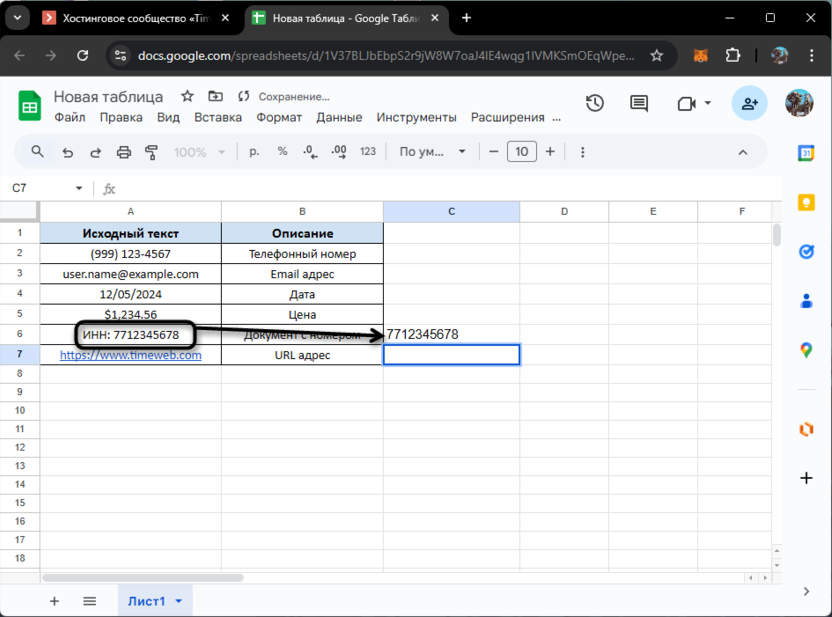
При этом отмечу, что актуальной будет подобная замена и в тех случаях, когда речь идет об идентификаторах в различных документах, будь то номер декларации, ИНН и другие данные. На скриншоте ниже вы видите, как применение функции в аналогичном представлении приводит к тому же самому результату. Конечно, регулярное выражение можно немного поменять, избавившись от лишних условий, но в конкретном случае это не является критичным и вы можете смело использовать такую же формулу в упомянутых сценариях.
Пример 6: Работа с URL-адресами
Завершающий пример работы с регулярными выражениями и функцией REGEXREPLACE позволит сократить URL-адреса, убирая из них протокол и часть www, которая по факту не нужна для корректной работы ссылки и только занимает место в ячейке. Ничего сложного в этом процессе нет, предлагаю использовать формулу следующего вида:
=REGEXREPLACE(A7; "^(https?://)?(www\.)?"; "")
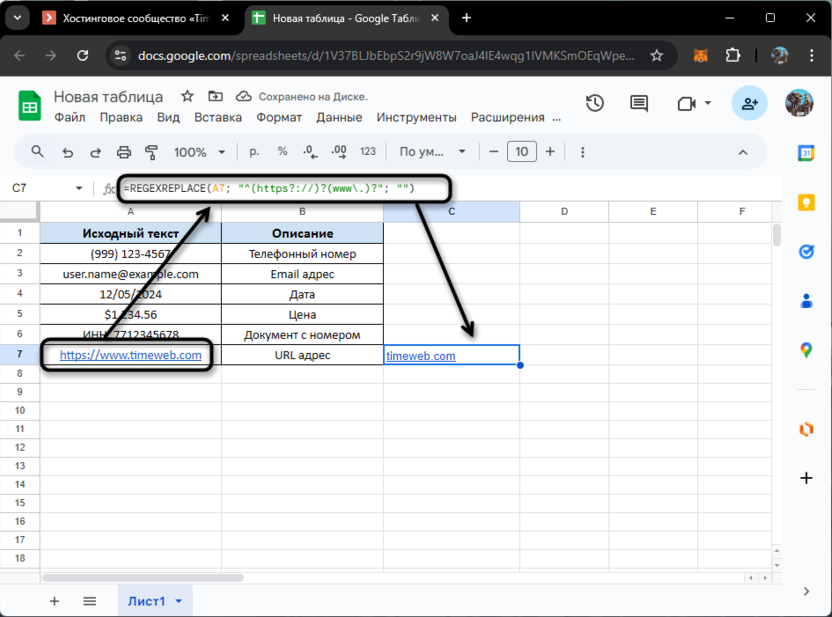
Изначально формула находит http:// или https:// в начале строки, вне зависимости от того, какой именно протокол используется. После этого сразу приступает к поиску www, потом берет все эти части и удаляет, оставляя только сам адрес и домен в конце. Соответствующий результат вы видите на изображении выше.
Заключение
Только что вы увидели целых шесть примеров работы с функцией REGEXREPLACE, которая связана с регулярными выражениями. Освоив основные их принципы, вы сможете автоматизировать множество задач по форматированию и очистке данных. Важно начинать с простых шаблонов и постепенно переходить к более сложным случаям, тестируя каждое регулярное выражение на различных наборах данных.
Отмечу, что кратко синтаксис регулярных выражений был разобран в каждом примере, но этого может оказаться недостаточно для того, чтобы научиться самостоятельно создавать более сложные формулы, когда речь идет о продвинутом использовании Google Таблиц. Поэтому, если у вас возникло желание детальнее разобраться в инструменте, советую сначала обязательно прочитать официальную документацию по ссылке ниже.





Комментарии