



Как понять, хорошо ли, как быстро и насколько правильно работает сервер? По сути, приведённые далее проверки можно осуществлять на любом сервере, компьютере либо виртуальной машине. Для начала необходимо разобраться с основными терминами, которые будут использованы.
Утилита — компьютерная программа для выполнения специализированных задач, связанных с работой оборудования и операционной системы устройства.
Можно сказать, что это небольшие программы, которые помогают производить анализ каких-либо данных, настройку или другими способами облегчать работу пользователя с системой.
Мы видим утилиты в качестве ярлыков на рабочих столах, файлов скриптов, вызываем их из командной строки или двойным щелчком. Однако внутри содержится программный код, который за нас производит все необходимые действия.
Утилиты могут входить в состав операционных систем, идти в комплекте со специализированным оборудованием или распространяться отдельно (в таком случае их нужно скачать либо установить из репозитория).
Производительность (вычислительная мощность компьютера) — это скорость выполнения определённых операций на компьютере, которую можно представить (измерить) количественной характеристикой (процентами, секундами, флопсами).
Оценка реальной вычислительной мощности производится путём прохождения специальных тестов, предназначенных для проведения некоторых операций и измерения времени их выполнения.
В нашем случае всю работу по тестированию и оценке данных (насколько это возможно) будут производить утилиты. Мы увидим лишь конечный результат. Основная задача: понять, что именно означают выводимые значения.
Для верной интерпретации полученных фактов необходимо также понимать: существует взаимосвязь между различными аппаратными компонентами, в сумме они влияют на производительность сервера (будь то Windows или Linux).
По этой причине мы будет рассматривать отдельно несколько параметров работы системы. В сумме их показатели влияют на общую производительность системы. Измерив всего один показатель, нельзя сказать, что работа происходит плохо, долго или некорректно.
Сейчас большинство серверов работают на основе операционной системы Linux, поэтому мы рассмотрим её более подробно в первую очередь. Вторую популярную в большей степени для домашнего использования систему Windows тоже не обойдём стороной.
Важно помнить, что приведённые утилиты имеют свои аналоги в обеих системах. Поэтому будут рассмотрены основные принципы работы наиболее популярных команд и программ. Дополнительные данные можно найти в открытом доступе сети Интернет. На форумах и в других источниках. Главное - понять, что искать. Приступим.
Сервер:
★ Linux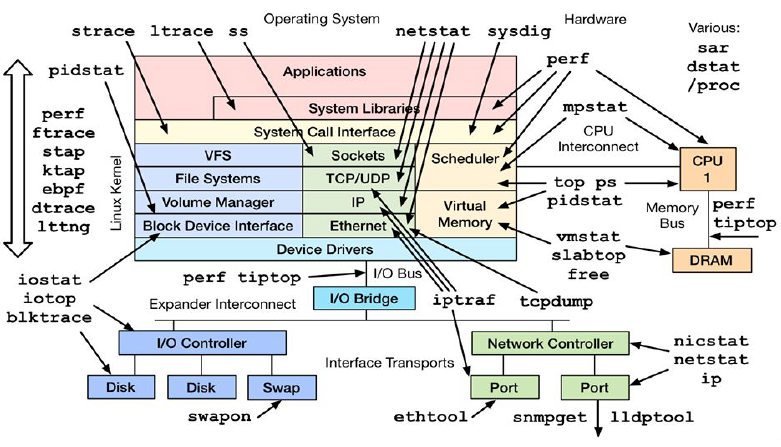
Общая схема подбора различных утилит для анализа запущенных процессов
Мониторинг состояния системы с разбиением по процессам
Поиск проблемных мест стоит начать с использования команды top.
Данная утилита широко используется для анализа программ в режиме реального времени. Набрав в командной строке top, мы сразу же видим динамическую выдачу процессов, которые в данный момент выполняются, спят или ожидают своей очереди. Однако сейчас нас в большей степени интересует самый верх - шапка - вывода команды. Выглядит это следующим образом:
top - 19:18:29 up 12 days, 16:55, 8 users, load average: 1,80, 1,77, 1,98 Tasks: 289 total, 4 running, 284 sleeping, 0 stopped, 1 zombie %Cpu(s): 33,6 us, 2,7 sy, 0,0 ni, 63,7 id, 0,0 wa, 0,0 hi, 0,0 si, 0,0 st KiB Mem: 12211328 total, 11368356 used, 842972 free, 172500 buffers KiB Swap: 6105648 total, 1405972 used, 4699676 free. 3704548 cached Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 28124 admin7 20 0 3065672 1,508g 242044 R 132,6 12,9 3084:46 mysqld 21572 admin7 20 0 3294116 1,518g 221012 S 8,0 13,0 1718:40 nginx
Показатели, на которые стоит обратить внимание, помечены красным цветом, их показатели - зелёным. В данном случае значения были выделены вручную для наглядности.
Более яркий вывод может обеспечить использование htop - это аналог рассматриваемой нами системной утилиты top, но для начала разберёмся с тем, на что стоит обращать внимание в обоих случаях.
Показатели загруженности системы: load average и %CPU, us, id, wa
1. load average
Состоит из трёх чисел и демонстрирует усреднённую загрузку сервера за 1, 5 и 15 минут. Чем ниже значения, тем лучше.
Простое правило: значения не должны быть больше количества процессоров.
2. %CPU
Какие процессы сколько процессорных ресурсов потребляют:
- us
Загрузка пользовательскими процессами. Если ваш сервер постоянно не загружен ресурсоёмкими операциями типа конвертации видео, то этот показатель не должен превышать 10-20%.
- id
Процент времени бездействия процессора должен быть высоким, в норме - от 80.
- wa
Ожидание операций ввода/вывода, чем ниже, тем лучше (иначе процессор слишком долго ждёт ответы от диска или сети).
Существует целый набор консольных утилит для измерения и анализа производительности системы - sysstat:
- iostat - показывает статистику использования процессора и потоков ввода/вывода для дисков;
- mpstat - выводит информацию об отдельных параметрах и общей статистике по процессору;
- isag - построение графика активности системы в интерактивном режиме;
- pidstat - мониторинг отдельных задач, управление которыми осуществляется ядром Linux.
Последнюю утилиту стоит рассмотреть подробнее. Для её использования мы сможем применить информацию, полученную с помощью предыдущей программы - top.
Pidstat - это утилита, которая предназначена для сбора и вывода статистики использования ресурсов процессами.
Команда сообщает об использовании процессорного времени. Мы используем её с флагом -р (что означает, сейчас мы будет указывать PID):
pidstat -p 611,1102 10 1
PID необходимого процесса вы можете посмотреть в результатах вывода той же команды top: первый столбец сообщается process id (мы указали PID 611 и 1102).
Таким образом мы узнаём количество выделяемых ресурсов процессам с определённым идентификационным номером в системе.
После необходимо указать время в секундах, в течение которого будет осуществляться проверка (в данном случае это 10 секунд). Вы можете задавать время на своё усмотрение в зависимости от задач, которые предстоит решить.
В завершение указываем число отчётов, которые желаем видеть по итогу.
При помощи флага -d можно получить статистику ввода/ вывода (остальные показатели остались неизменными):
pidstat -p 1102 -d 10 1
При помощи флага -r можно получить статистику использования оперативной памяти:
pidstat -p 1102 -r 10 1
Использование оперативной памяти
Для подробного отчёта об использовании всей оперативной памяти на устройстве подойдёт:
free -h
total used free shared buff/cache available Память: 7,3G 5,0G 1,0G 124M 1,2G 1,8G Подкачка: 7,5G 1,3G 6,2G
total used free shared buff/cache available Mem: 488M 23M 370M 94M 441M Swap: 0B 0B 0B
Столбцы:
- total
Общее количество памяти
- used
Реально использующая и зарезервированная системой память
- free
Свободная память (total - used)
- shared
Разделяемая память (быстрое средство обмена данными между процессами)
- buff/cache
Буферы в памяти (страницы памяти, зарезервированные системой для выделения их процессам, когда они потребуют этого, также известна как heap-memory)
- available
Доступная для использования память
Строки:
- mem (память)
Показывает, сколько физической оперативной памяти сейчас свободно. Стабильно низкий объём свободной памяти сам по себе не говорит о каких-то проблемах, но за ним стоит начать следить, чтобы убедиться, что памяти будет хватать даже при пиковых нагрузках.
- swap (подкачка)
Показывает использование файла подкачки или виртуальной оперативной памяти. Если значение больше нуля, значит, часть данных не помещается в оперативную память и вытесняется на диск, а так как дисковые операции чтения и записи гораздо медленнее аналогичных для памяти, то падает производительность всей системы.
Далее кратко рассмотрим утилиту PS.
PS (от англ. process status) — программа, выводящая отчёт о работающих процессах.
Вы можете использовать следующую готовую команду, чтобы узнать топ прожорливых к памяти процессов:
ps aux --sort=-rssize | head -20
Отсортировать и по виртуальному размеру - что процесс просит у ядра, но не получает.
ps aux --sort=-vsz | head -20
Использование процессорного времени
Утилита vmstat
Используется для определения производительности системы.
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 7596 329216 13260 14506756 0 0 4625 26 42 145 4 1 81 13 0
- us (user)
Процессорное время, затраченное на пользовательские процессы (демоны и прикладного ПО).
- sy (system)
Системное время, затраченное на пользовательские процессы (демоны и прикладного ПО).
- in (interrupts)
Количество прерываний контекста
- cs (context switches)
Количество переключений контекста
Утилита nmon
Программа называется Nigel’s Monitor, или просто nmon. Она в реальном времени выводит сведения о различных показателях, характеризующих состояние сервера.
Nmon имеет текстовый интерфейс, поэтому для работы с ним достаточно подключиться к серверу по SSH.
Работа с nmon
В окне утилиты, показанном на рисунке ниже, надо указать, какие именно сведения вас интересуют, включая и отключая соответствующие информационные разделы.
Скажем, вас интересуют дисковые накопители. Если нажать клавишу d на клавиатуре, nmon выведет данные обо всех дисках, которые подключены к серверу.
Далее добавим информационные разделы со сведениями о сети и памяти - клавиши n и m.
Для того, чтобы выйти из nmon, нажмите клавишу q.
Сервер:
★ Windows
Серверы на Windows не так распространены, как их опенсорсные коллеги. Однако в данной системе можно наглядно зафиксировать интересующие показатели в виде разноцветных графиков и диаграмм, благодаря наличию большого количества утилит, которые имеют приятный графический интерфейс.
Использование предложенных ниже программ в большинстве случаев интуитивно понятно. Мы разберём самые востребованные в данном случае функции каждой из них.
Как найти самые большие файлы на жёстком диске
1. CCleaner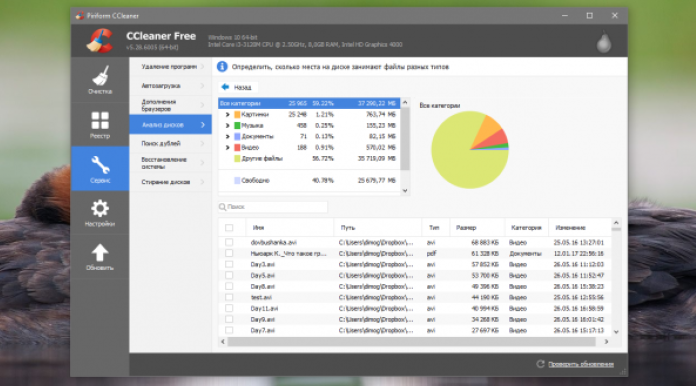
В разделе «Сервис» находится полезный инструмент - «Анализ дисков», который используется для поиска больших файлов.
Использование дискового пространства иллюстрируется с помощью круговой диаграммы, отображающей распределение между основными типами файлов — изображениями, документами, видео.
Также вы можете перейти в раздел очистки системы, включить автоматическое определение файлов, которые могут быть удалены из оперативной памяти и жесткого диска за ненадобностью.
Однако рекомендуем внимательно ознакомиться с результатами вывода, чтобы не затронуть важные файлы, необходимые для функционирования ваших программ.
2. WinDirStat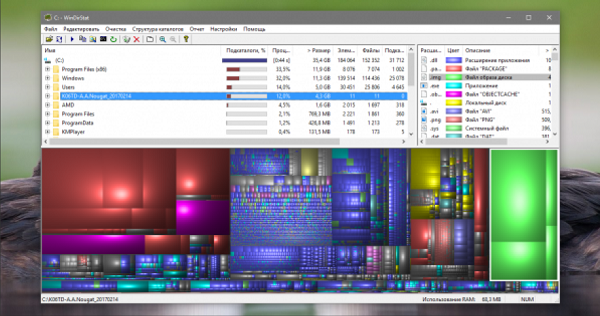
После запуска и предварительной оценки заполненности жёсткого диска WinDirStat выдаёт полную карту его состояния. Она состоит из различных квадратов, размер которых соответствует размеру файла, а цвет — его типу. Клик по любому элементу позволяет узнать его точный размер и месторасположение на диске. С помощью кнопок на панели инструментов можно удалить любой файл или просмотреть его в файловом менеджере.
3. SpaceSniffer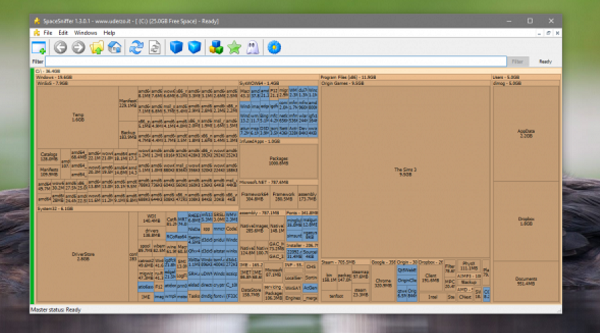
Это приложение показывает карту заполненности диска, можно регулировать глубину просмотра и количество отображаемых деталей.
Для сбора данных Windows сервера можно также воспользоваться Performance Monitor.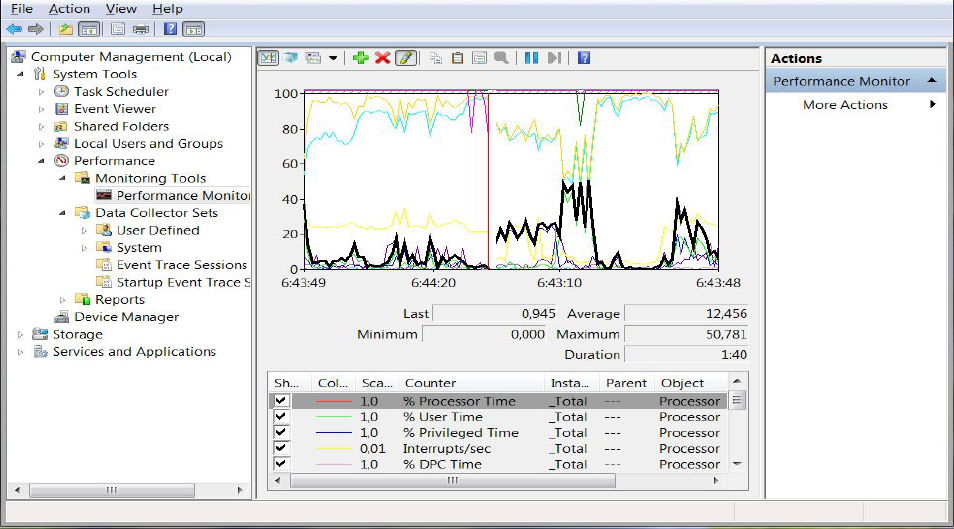 Однако данный функционал нуждается в небольшой предварительной настройке.
Однако данный функционал нуждается в небольшой предварительной настройке.
Для оценки базовой производительности сервера достаточно собрать информацию:
- Average Disk Queue — для жестких дисков
- % Processor Time — для процессора и процессов
- Committed Bytes — для оперативной памяти
Когда процессу нужен доступ к физическому ресурсу, операционная система ставит запрос в очередь. Если в очереди стабильно больше 2 элементов, значит, ресурс становится узким местом.
Анализ данных с помощью утилиты PAL
Утилита написана Клинтом Хаффманом, который является PFE-инженером Microsoft и занимается анализом производительности систем.
На вкладке Counter Log задаётся путь к файлу данных со счетчиками производительности, собранными ранее.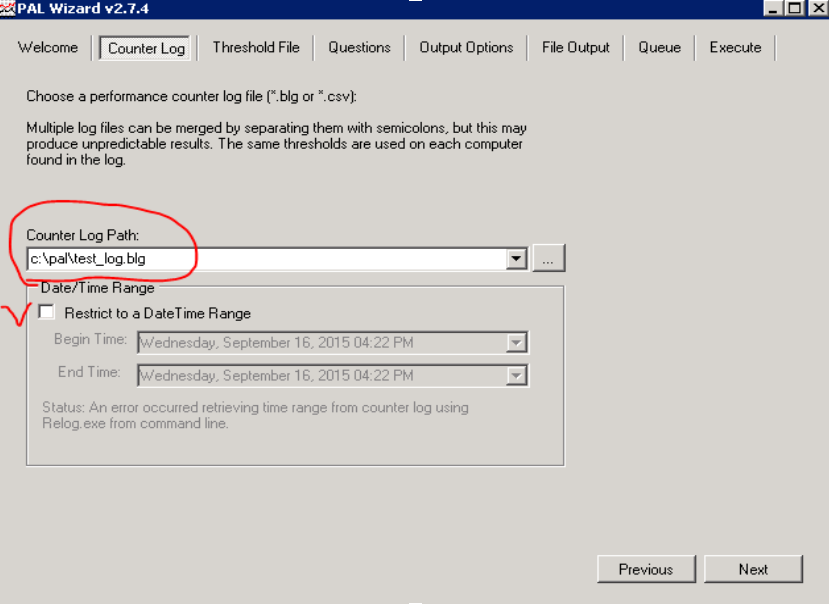
Также мы можем задать интервал, за который будет производиться анализ.
На вкладке Threshold File находится список шаблонов, которые можно экспортировать в формат xml и использовать как список счетчиков для сборщика данных.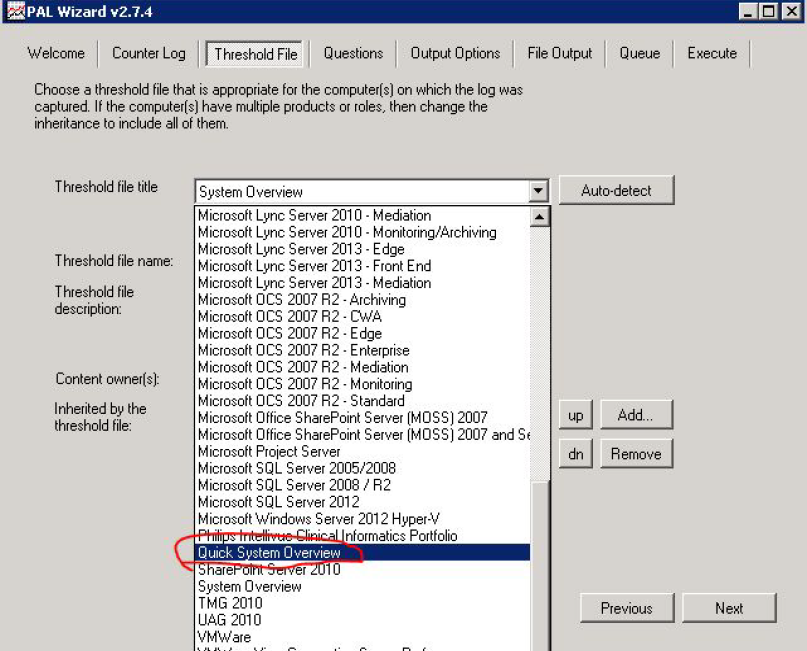
Вот и всё. Здесь собрано значительное количество, однако далеко не все инструменты, которые можно использовать для анализа производительности на сервере. Важно понимать, какой критерий в производительности является для вас основополагающим. И выбирать программное обеспечение, отталкиваясь от заданных целей. Удачной работы.






Комментарии
А есть фотография Екатерины Рысь? Мне кажется, я даже видел Екатерину в игре "Что? Где? Когда?"))